大家好,今天来分享一下我们队(ECNU_ICA)在 2021 年字节跳动安全 AI 挑战赛色导用户识别方面的工作。
先说名次,在经历了初赛、复赛以及决赛的重重竞争,最终我们拿到了全国第七的成绩。
呜呜,虽然在决赛里是垫底的样子,但是我认为我们做的这些工作还是有一定的学习价值。
也感谢各位大佬前来观摩~
这里再放几个相关链接:
放一张团队简介,我们团队横跨国内外三大高校。要问距离这么远我们是怎么结缘的,一切都源于,我们都是 imqxms. 社区的成员。
继 2020 年 7 月底,imqxms. 首次线下聚会后~ 这也算是社区成员又一次因为同一件事情聚在了一起~
哈哈哈,没有安排紧致的各种活动,大家都因为一些兴趣组成了这样一个小圈子~

本次赛题主要以网络黑产识别为背景,根据用户基本信息(如性别、个性签名、关注人数)、用户行为信息(如点赞数、评论数等)以及用户投稿信息来预测该用户是否为色情导流用户。
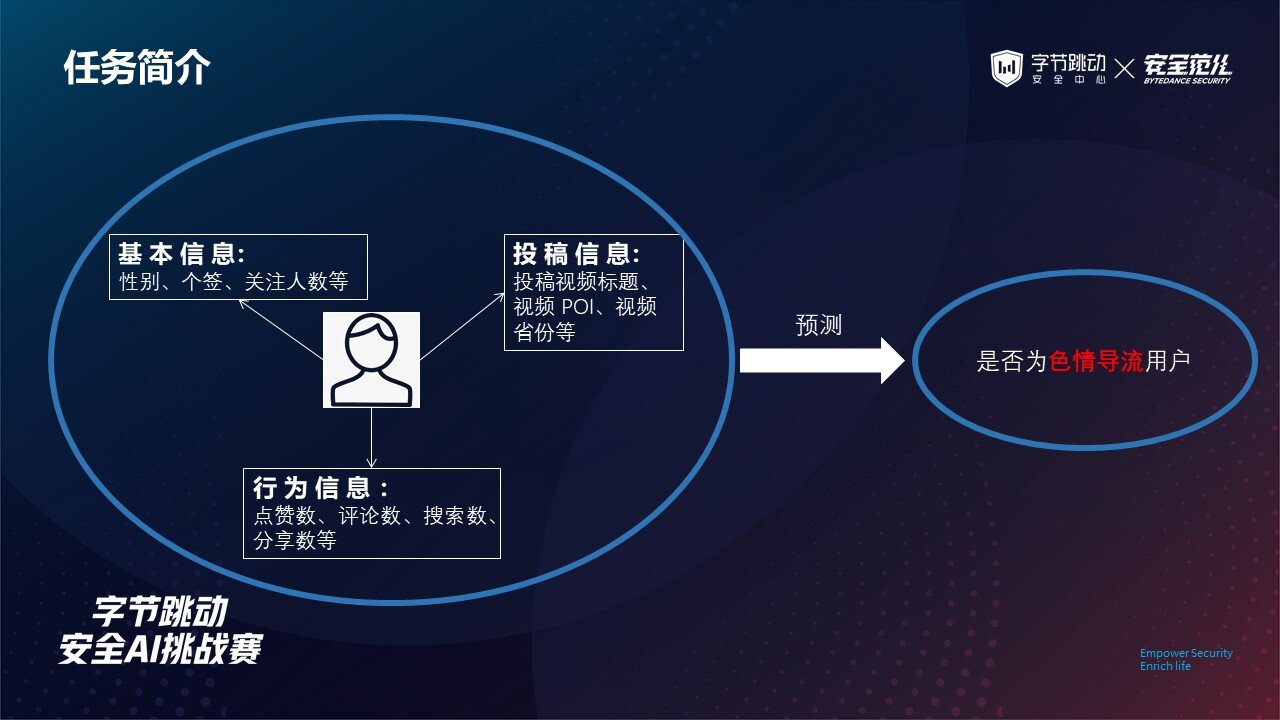
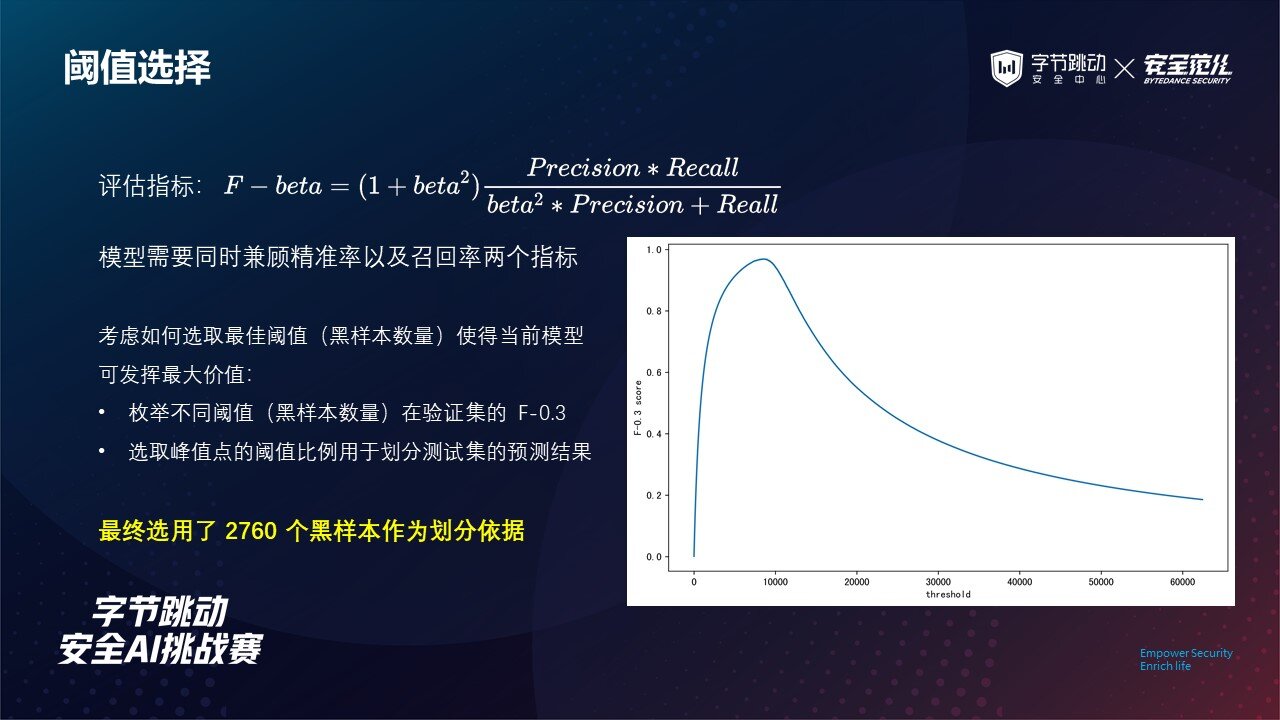
任务的评估指标选用 F-beta,这里的 beta 为 0.3,该指标可用于权衡预测结果的精准率以及召回率。

这里是数据集所能提供的所有基础特征,我们将这些特征分为三类:

除此以外,想要深刻的理解任务以及做出更加合理的解决方案,需要我们对当前业务以及用户导流方式有一个基本的认知。
因此,我们基于题目描述所知的信息调查了现有主流的几种用户导流方式:
当然,这些导流方式有的受限于当前所提供的数据难以实现,例如视频及头像信息缺失、文本信息已做脱敏处理等。

这里是关于个人主页中的一些引流方式的示例。
考虑防止被现有模型检测以及过滤,色导用户的联系方式往往会通过象形字 / 同音字或 emoji 表情的方式引出,例如『v♥』代表微信、『加薇』之类的也代表微信添加的方式,也有『+q』代表 qq 的联系方式。
有的联系方式之前使用冒号来分隔。
部分用户在个性签名中也会留有导流途径的介绍,例如『看头像找我』,而头像中则包含二维码等信息。
除了通过同音字 / 象形字 / emoji 表情引出联系方式以外,部分色导用户还会用这种手段摆明意图,例如最后一张图。
当然,也存在正常的商业导流,但其行为与色情导流的差别在于是否刻意使用语义技巧来隐藏信息。

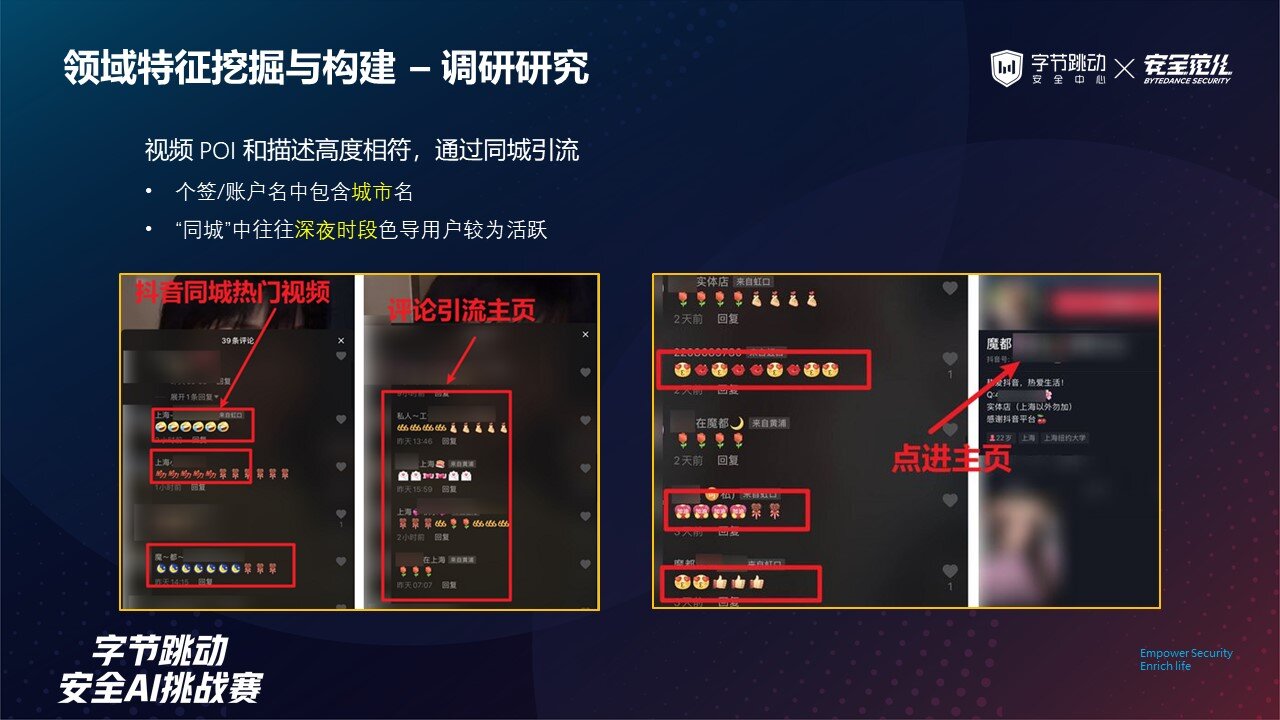
另外也有一些同城引流的示例,通常黑产团伙会设计好专门的话术,并且加上明显的 POI 地点,因为距离的接近,会使得导流成功的概率大大提升。
例如操作大批账号在热门视频下评论,而部分账户的个人介绍或账号名中包含着城市名,这样一批评论会吸引有心之人点进主页,再根据一些隐含的联系方式导流到其他平台。
根据调研发现,抖音『同城』功能中,深夜时段为色情导流用户的活跃期。
这些结果都表明,在现有任务所提供的数据下,如何更好的去建模个性签名、投稿时间等信息对模型提升的潜力是很大的。
但现阶段由于脱敏等缘故难以建模同音字或 emoji 等信息,因此我们考虑尽可能的基于脱敏文本挖掘有用的知识。
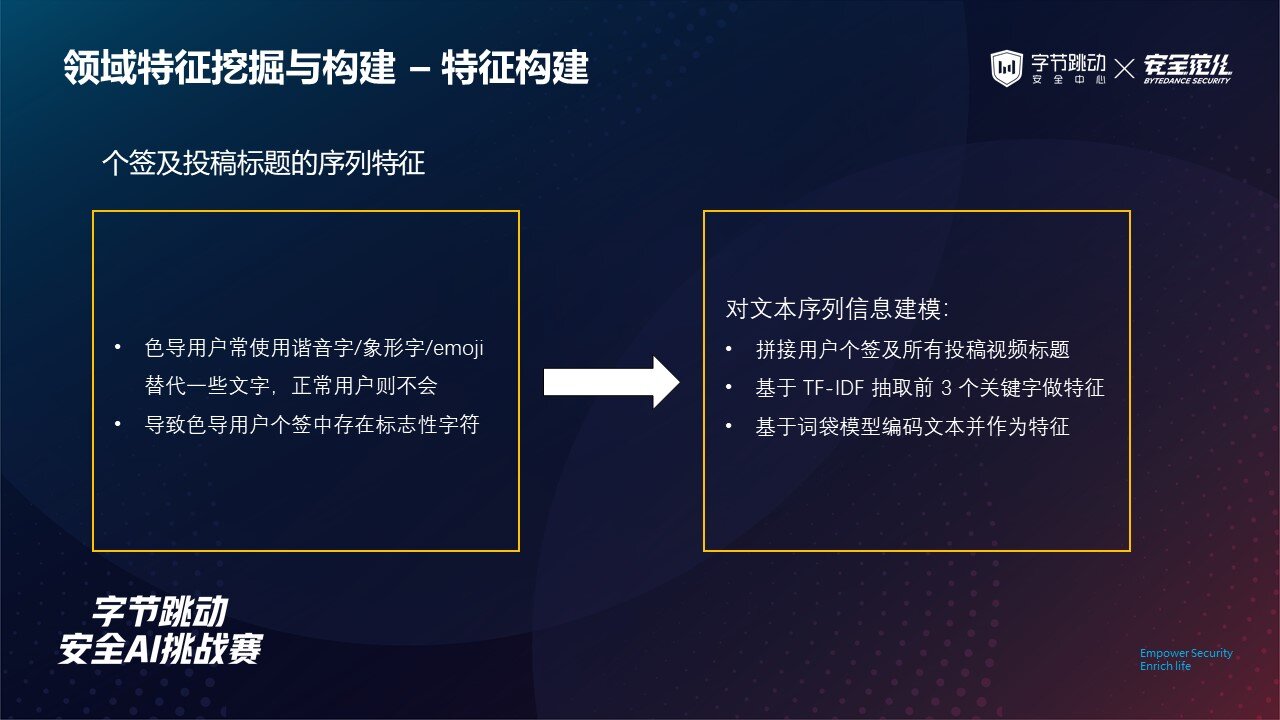
这里是具体特征构建的过程,针对个性签名以及投稿标题的序列特征,我们考虑色导用户通常使用谐音字 / 象形字 / emoji 来替代一些文字,而正常用户则不会。
这会导致色导用户个签中可能存在一些标志性的字符或短语,这些字符或短语在正常用户中出现频率很低。
因此,我们考虑拼接用户的个性签名及其所有投稿视频的标题,形成该用户的描述性文本。
然后基于 TF-IDF 算法从该描述性文本中抽取前 3 个代表性的关键字。
同时我们基于词袋模型为描述性文本进行编码,生成文本的词袋表征用于后续模型训练。
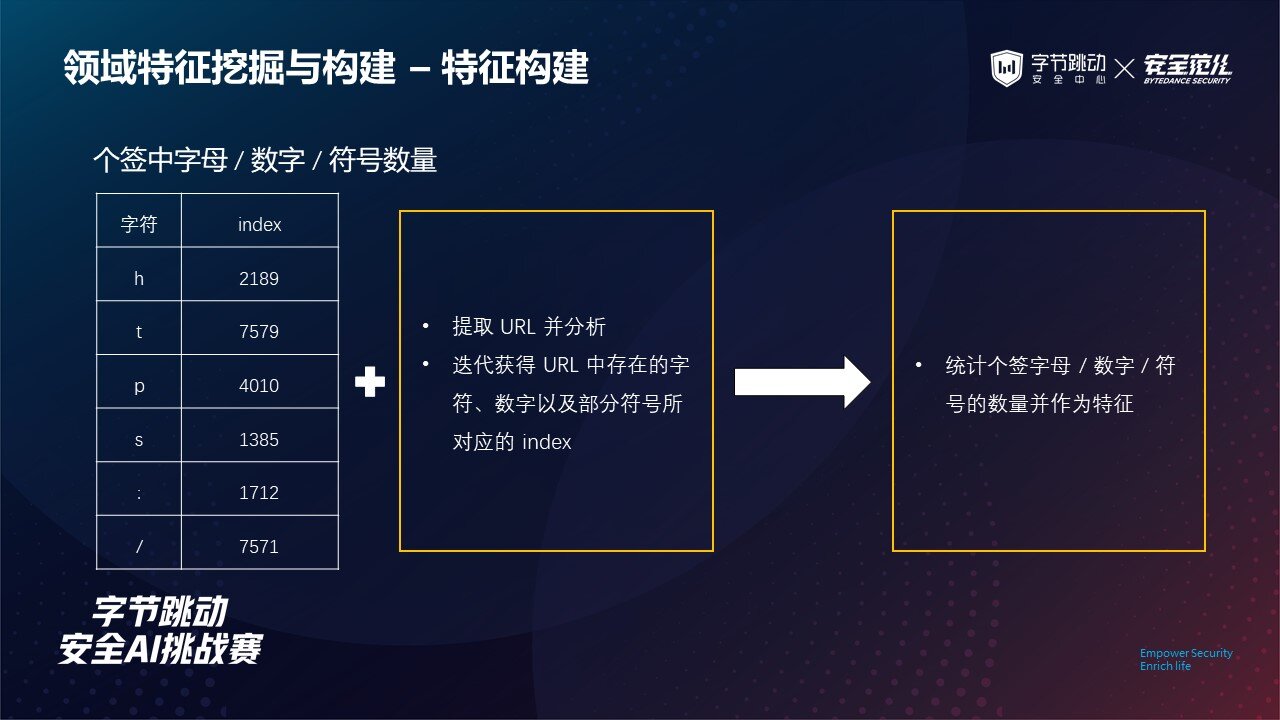
针对用户个性签名及投稿视频标题中以链接进行导流的方式,
我们设计规则来鉴别链接信息,主要是 http 及 https 两类,然后得出脱敏 index 与相关字符的一个映射关系。
根据该规则,我们提取出用户个性签名及其视频标题中是否包含链接以及包含链接的数量作为特征。

考虑到色导用户其个性签名中往往使用谐音字来隐藏信息,而谐音的一个来源则包括字母及数字。此外,有无联系方式的存在也是有无导流行为的一个鉴别依据。
因此,在上一步确定 http 及 https 相关信息后,我们基于规则提取完整链接并做进一步的分析,迭代获得了链接中存在的字符、数字以及部分符号所对应的 index,进而将个签中所包含字母 / 数字 / 符号的数量作为了特征。
在有了前面的基础特征和领域特征后,我们还采用特征聚合及特征交叉的方式生成新的特征。
特征聚合就是说根据现有的一个或多个离散列执行聚合操作,并统计出其余列的一些统计信息。
例如:每个用户的投稿数量、每个用户投稿地区覆盖了多少个省份 / POI、个性签名为空的用户的平均粉丝数是多少。
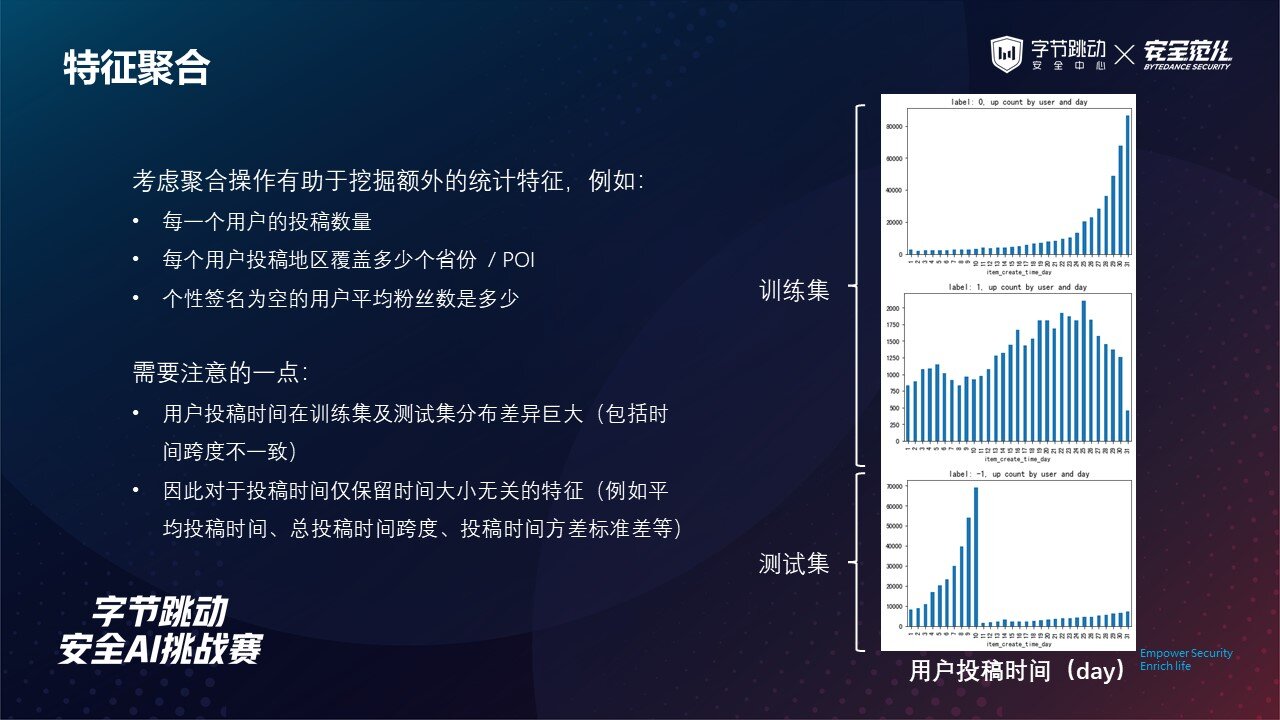
在比赛中我们发现,投稿时间这一个特征训练集与测试集之间的分布差异非常大。
在根据投稿时间的时间戳提取出一个月每一天的投稿量时,我们发现训练集中正常用户的投稿量随着月初到月末逐渐增加,而色导用户的投稿量也有着较为平滑的浮动曲线。
同样的,测试集中投稿量随着天数的增加也有一定的变化规律,但其分布与训练集差异较大。
实验中也发现了这一特征有穿越的现象(可能是构建数据集采样时出现了一些问题),因此综合考虑下最终我们仅保留了与时间大小无关的特征,例如平均投稿时间、总投稿时间跨度等。
此外,针对一些特定的连续型特征,我们还考虑特征之间的交互容易组合出一些更为有用的新特征,
例如播放时长 / 播放次数 = 平均播放时长、粉丝数 / 投稿数 = 平均每个投稿所获粉丝量,
因此我们考虑通过加减乘除对候选的连续型特征进行组合。

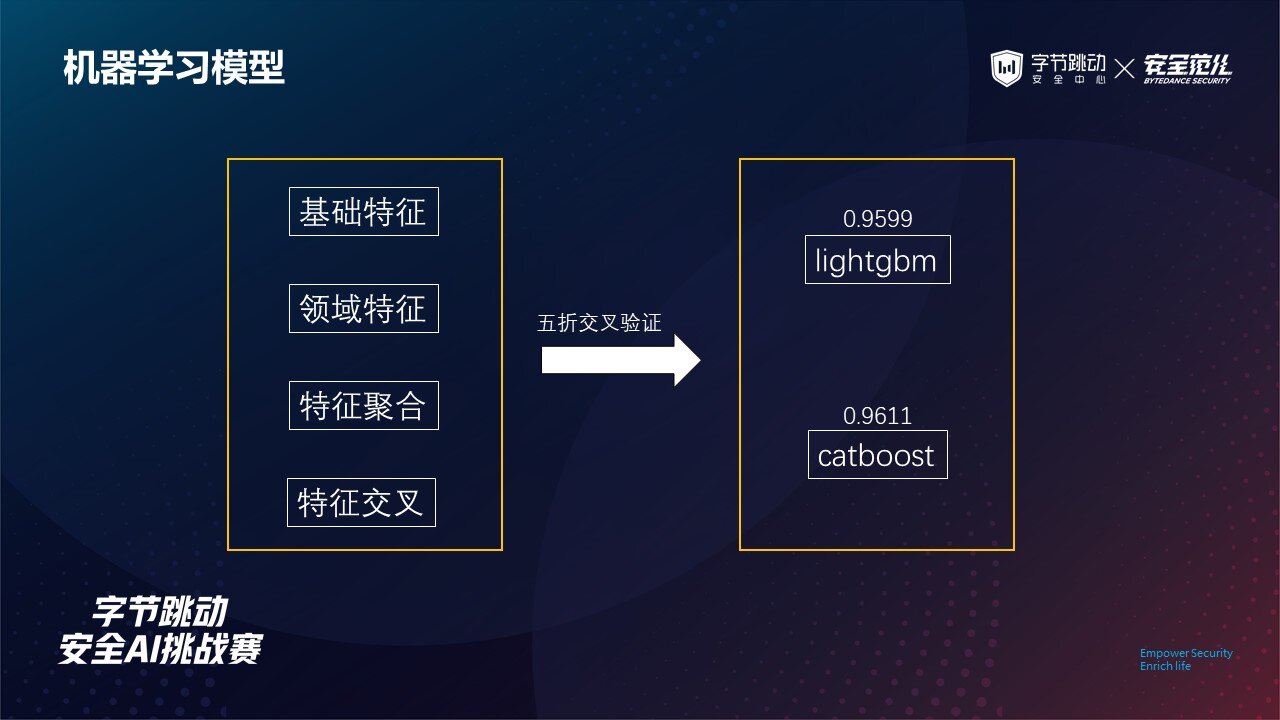
基于前面得到的基础特征、领域特征以及特征聚合与特征交叉的结果,我们使用五折交叉验证的方法训练下游的树模型,主要测试过 lgb 以及 catboost 两个模型,最终在 catboost 中取得了复赛 0.9611 的成绩。
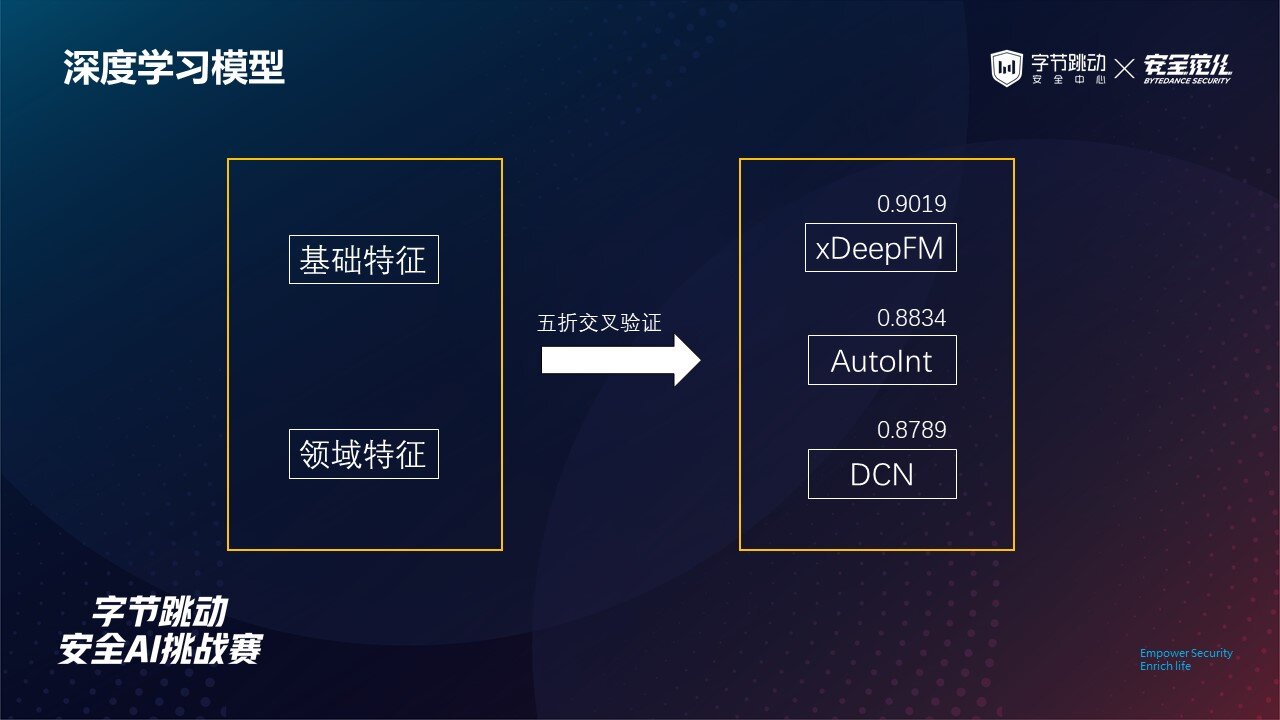
我们也尝试过将基础特征与领域特征送入深度学习模型,使用神经网络自动挖掘有用的组合特征。
由于色导用户识别与推荐任务中的点击率预测在建模中有着相似性,因此我们主要用到 xDeepFM、AutoInt 以及 DCN 这几个模型,但实验效果都未达到预期。
有了输入特征,有了模型,现在要训练使模型为每一个样本进行打分,打分结果接近于 1 的则更可能为色导用户。
那便存在这样一个问题,究竟打分结果高于多少时认定该样本为色导用户。
根据评估指标,我们的预测结果要权衡精准率以及召回率,因此,合适的分界可以更好的评估模型的优劣。
这里我们基于五折交叉验证中所有验证集的预测结果,按打分从高到低枚举不同的黑样本数量并绘制 F-0.3 的变化曲线,最后选取峰值点的阈值比例用于划分测试集的预测结果。
最终,我们的模型选用 2760 个黑样本作为划分依据(实际测试集黑样本数量应该是 3748)。
除此以外,我们也做了许多其他的尝试,包括部分本地提升但在线评估效果降低的方案。

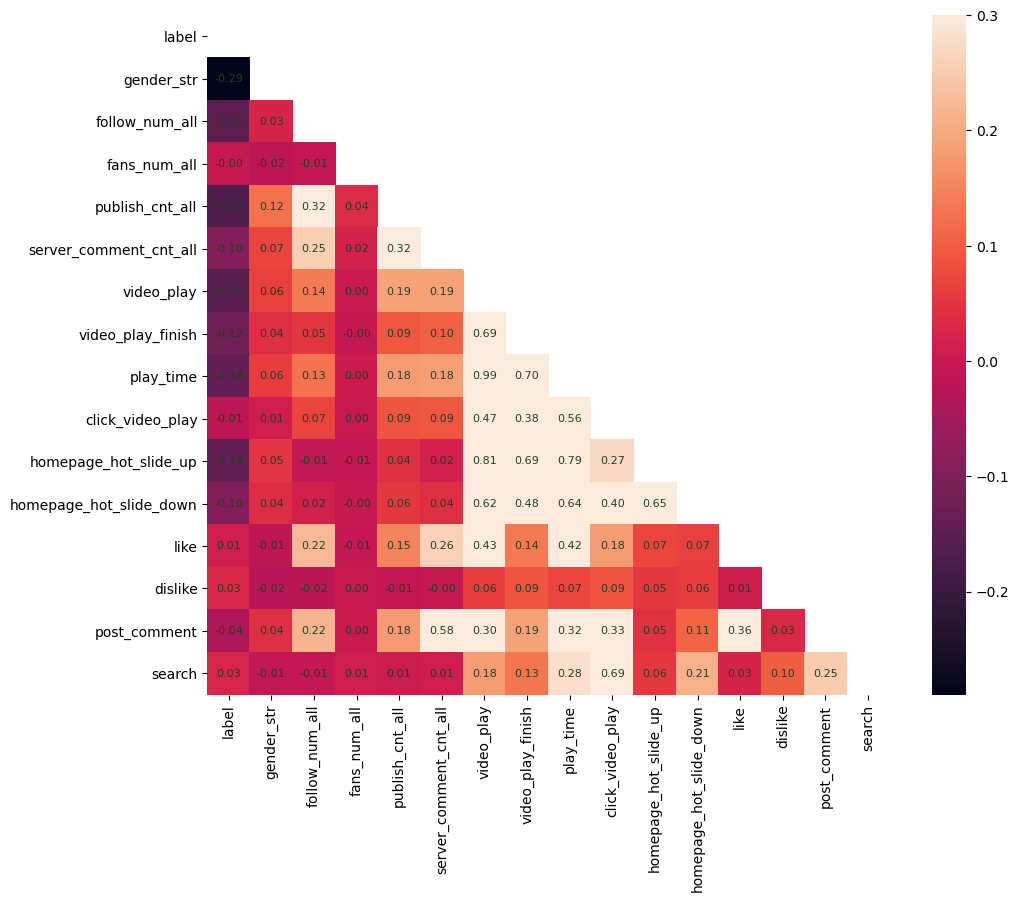
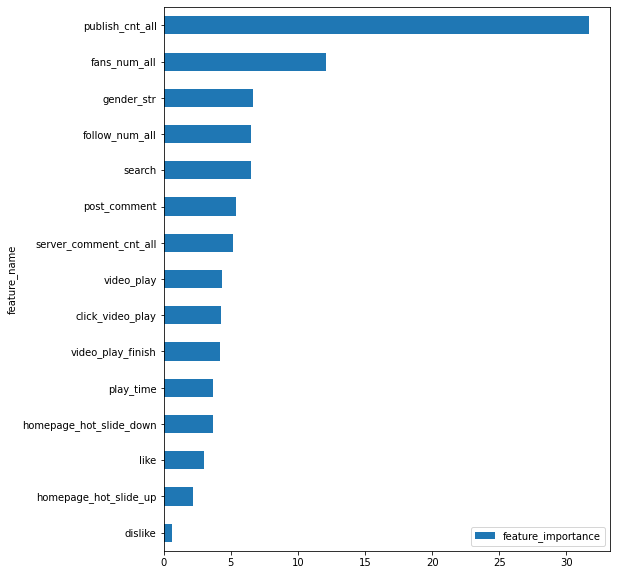
A * B、A + B 为对应特征的交叉4807、6951 这样纯数字的特征为个签及视频标题的词袋表征对应 index 的重要性sparse:user_up_info_group_var_(id)_poi_name_nunique 为针对用户上传表中的 id 列执行 group 操作,取 poi_name 列的 nunique 数作为特征;dense: 开头的同理。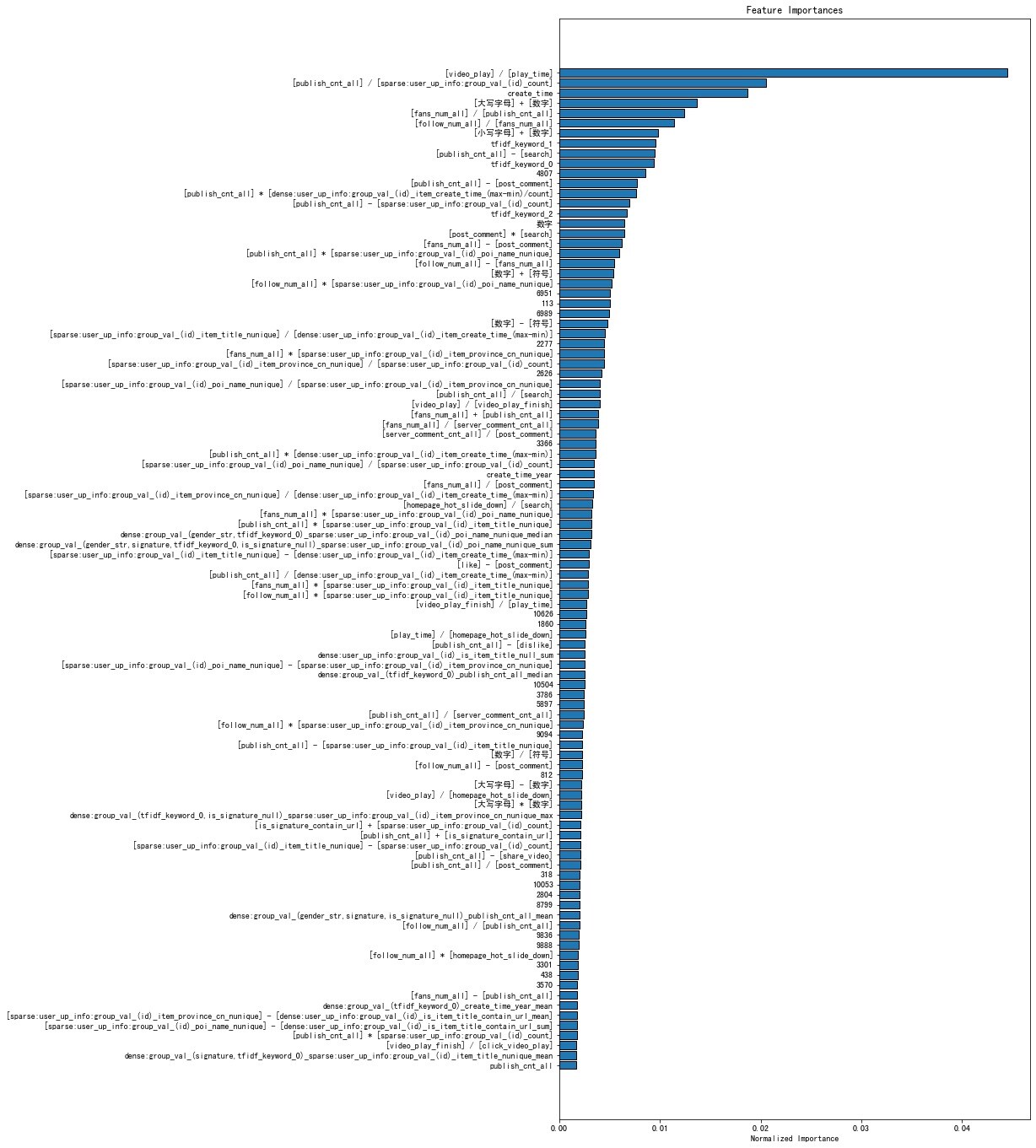

Q1: 有没有分析过为什么深度学习模型相比于树模型效果要差一些?
在色导用户识别还有像推荐的一些任务里,正负样本以及长尾分布的现象是非常明显的,这对于深度学习模型来说就是噩梦,模型感知到大量的数据预测为某个标签时它就倾向于建模这些数据,从而导致长尾尾部的那些信息难以建模,这是此类任务对深度学习的难点。
但树模型因为是基于一种可量化的规则建模的,本身并不会受到类似的影响。
Q2: 有没有在特征重要性这块做过细致的分析,然后哪些特征更为重要,沿着这个方向深入挖掘?举例哪些是找到的,哪些是扩展出来的。
Q3: 从讲解中感觉在数据分析类的工作偏少一些,这部分是没有展示还是没有做?
Q4: 有没有考虑模型鲁棒性的一些因素?
Q5: 一类导流方式是通过大规模的发布然后诱导用户产生关联,但是在本次工作的介绍中没有看到相关的关联关系,这个是什么原因,是因为本身提供数据的限制还是基于什么样的考虑?
Q6: 有没有观察过一些误判的 case 是什么?这些误判的 case 主要是因为哪些特征导致的?
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。