In this post, we discuss one of our most recent systems modernization using AWS, which aimed to improve shopping cart latency and increase efficiency on a per-operation basis during the shopping experience.
Shopping cart management is the core of any ecommerce system. It must be simple, fast, and reliable. A shopping cart can vary in size given the different kinds and volumes of information inserted on it, such as items, addresses, and so on.
For several years, VTEX used Amazon Simple Storage Service (Amazon S3) as its primary storage layer for shopping carts. Its reliability and object size limit flexibility were advantages for a long time. For example, a single shopping cart would vary from 1 KB up to 50 MB, with the number of PUT requests over 300,000 per minute during peak traffic hours.
In the ecommerce segment, faster response times lead to higher conversion rates. We wanted to improve both the purchase experience and customer conversion rates.
To accomplish this goal, we evaluated changes to improve the performance of our data storage. We chose Amazon DynamoDB due to its low latency, its managed service capabilities that removed some of the heavy lifting of maintaining database instances, and the fact that DynamoDB was already deployed as part of the company's stack in areas such as data and analytics.
We ran a proof of concept to better understand if DynamoDB would meet our requirements. After a closer evaluation of our data, we realized that some of our shopping cart items were bigger than 400 KB, which is the DynamoDB item size limit.
We reduced our shopping cart data by more than 60% on average with the following strategies:
Payload optimization – We removed legacy fields that weren’t used anymore by any API processing or response.
Removing default fields – We removed additional unnecessary data from the shopping carts, including null fields. The de-serialization process will create these values on the application side.
Compression – We added a compression step before saving it to DynamoDB as a byte array field.
After that, the remaining larger objects (greater than 400 KB) would be offloaded to Amazon S3.
VTEX decided to migrate to the new solution gradually, avoiding unnecessary risks and taking the time to validate associated metrics.
In the initial stage, we wrote data in DynamoDB and Amazon S3 but only read from Amazon S3.
Later, we switched to primarily reading from DynamoDB (fallback readings were still going to Amazon S3) but continued to write on both.
In the third step, we stopped writing in Amazon S3 and used it solely for reading fallback and offloading objects.
Finally, we stopped using Amazon S3 as a fallback for reading and kept it only to store large objects that are larger than DynamoDB items size limit.
The following table shows the type of use for each storage service along the four phases. DynamoDB proved itself as a faster and more efficient solution for our current and near-future use cases.

VTEX had over 4 billion items—70 TB in total—to migrate. Because this was a mission-critical application, the team performed a gradual migration with the help of Amazon S3 TTL. We divided the migration in four different phases.
We wrote the shopping cart elements to DynamoDB and Amazon S3 to prepare for the migration. This allow us evaluate how much capacity we would consume in DynamoDB, as well as its error rate and throttling, and keep writing in Amazon S3 in case of rollback.
We opted to point the application to DynamoDB after 10 days of dual writes while relying on Amazon S3 to handle requests for data older than 10 days. We still wrote in both databases in case of rollback.
We saw consistent latency improvements by adopting DynamoDB for this workload, as shown in the following figure.
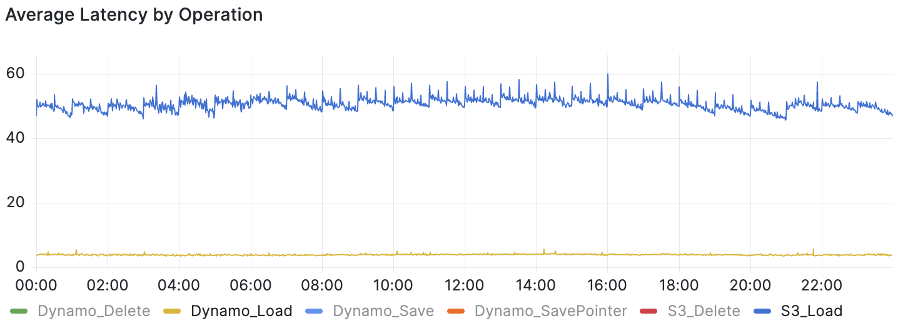
We kept replicating writes to Amazon S3 to be prepared in case of rollback. However, when the team became confident that phase two was successful, we stopped writing to Amazon S3. This step has had a tremendous impact on latency while removing the possibility of rolling back to Amazon S3 without losing shopping carts.
The new approach helped us reduce shopping cart API latency by around 30%, as illustrated in the following figure.
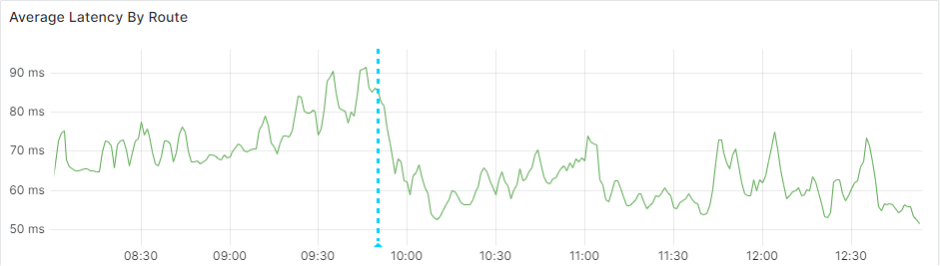
Also, in the following AWS Cost and Usage Report (CUR), we see the efficiency gains at this stage.
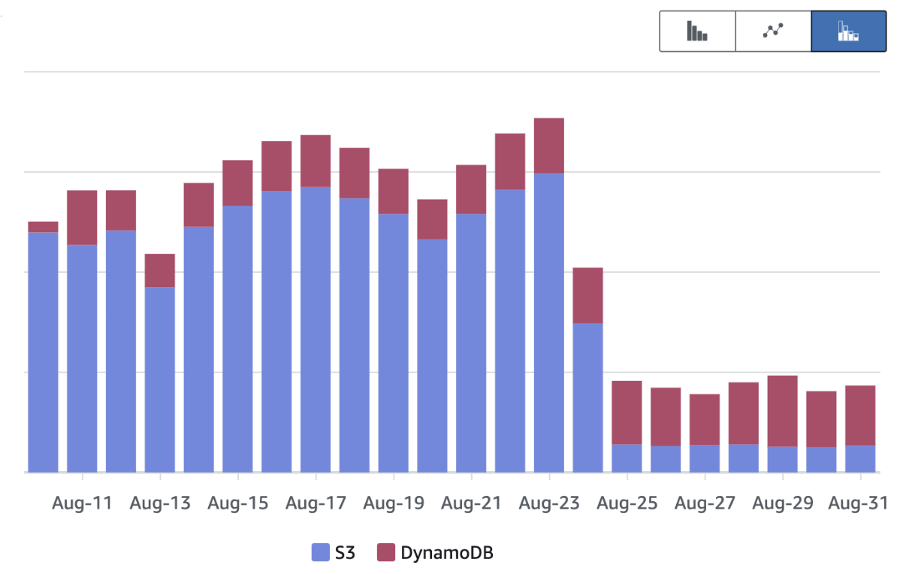
Finally, we stopped using Amazon S3 as the fallback for reading and just use it to offload files larger than 400 KB. With that, we have the final latency improvement.
In this post, we showed you how VTEX modernized its shopping cart system with Amazon DynamoDB. By doing that, VTEX was able to improve its shopping cart API’s latency by about 30%, improving approximately 70% of its shopping cart storage investments with a smooth and safe migration process.
Managing a solution with millions of requests per minute poses a great technical challenge. It’s crucial that the solution is efficient and reliable, with low latency, in order to apply to the business.
This article was produced in collaboration with AWS. Original post co-written with Alberto Frocht
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。