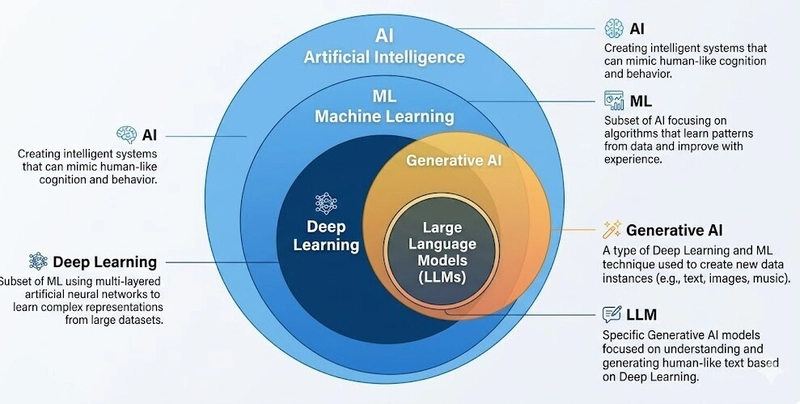
Artificial Intelligence has progressed far beyond its early rule-based origins. What once depended on predefined logic has evolved into systems that can learn from data, reason through problems, and even generate entirely new content. This transformation is largely driven by Machine Learning (ML), where algorithms improve their performance by identifying patterns in large datasets rather than following hard-coded instructions.
Building on ML, Deep Learning introduces neural networks—layered computational structures inspired by the human brain. These networks excel at processing complex data such as images, speech, and text. The next leap in this evolution is Generative AI, which shifts the focus from analyzing data to creating it. Whether producing text, images, or audio, generative systems mimic human creativity in increasingly sophisticated ways.
Large Language Models: The Core of Modern GenAI
At the center of today’s generative revolution are Large Language Models (LLMs). These models are designed to interpret and produce human-like language, enabling natural conversations, content generation, and problem-solving.
Most modern LLMs are built on the Transformer architecture, introduced in the landmark concept “Attention Is All You Need.” This architecture uses attention mechanisms to understand how words relate to each other in context, making it far more effective than earlier sequence models.
Some prominent LLM families include:
- OpenAI models such as GPT-4.5, GPT-4o, and smaller optimized variants
- Anthropic’s Claude series (e.g., Claude 3.5 Sonnet, Claude 3 Opus)
- Meta’s Llama models (e.g., Llama 3.x series)
- Google’s Gemini models
These models power a wide range of applications, from chatbots and virtual assistants to marketing content generation, document summarization, and even software development tasks like debugging and code generation.
How LLMs Work in Practice
Accessing LLMs
Users can interact with LLMs through intuitive interfaces (chat-based systems) or integrate them into applications using APIs.
Prompting and Instructions
To guide an LLM toward the desired output, users provide structured inputs—this process is known as prompt engineering. The clarity and design of prompts significantly influence the quality of responses.
Understanding Language via Embeddings
LLMs convert text into numerical representations called embeddings. These vectors capture semantic meaning, enabling the model to understand relationships between words, phrases, and broader contexts.
Controlling Output with Temperature
LLMs do not always produce the same answer. A parameter called temperature controls how deterministic or creative the output is. Lower values lead to predictable responses, while higher values increase variability and creativity.
Grounding LLMs with Real-World Knowledge
Despite their capabilities, LLMs are inherently general-purpose. They do not automatically know company-specific or real-time information. To make them useful in practical settings, additional context must be provided. Two key approaches enable this: Retrieval-Augmented Generation (RAG) and Fine-Tuning.
Tokenization: How Models Read Language
Computers don’t interpret language the way humans do. Instead of understanding full words or sentences directly, Large Language Models break text into smaller units called tokens. These tokens are then converted into numbers so the model can process them mathematically.
A token isn’t always a whole word—it can be:
A complete word (“river”)
A fragment of a word (“run” + “ning”)
Symbols or punctuation (like “?” or “.”)
Different AI models use different methods to split text into tokens. Some rely on frequently occurring patterns, while others use statistical approaches to segment text.
On average, in English:
1 token is roughly equal to 4 characters
Or about ¾ of a word
Why this matters:
Efficiency: Breaking text into tokens allows models to process language in a structured way.
Flexibility: Even unfamiliar words can be understood by splitting them into smaller parts.
Cost impact: More tokens directly increase usage costs.
Example:
Sentence: “Learning AI is fun.”
Possible tokens: “Learn”, “ing”, “ AI”, “ is”, “ fun”, “.”
Each of these is internally mapped to a numeric ID for computation.
Context Windows: The Model’s Working Memory
LLMs don’t have unlimited memory. Instead, they operate within a fixed limit called a context window, which defines how many tokens the model can consider at one time.
Think of it as short-term memory:
Smaller models handle a few thousand tokens
Advanced models can process very large inputs, even entire books
If the input exceeds this limit, older parts are removed from consideration. The model then loses access to that earlier information.
Why this matters:
Conversations: Important details from earlier messages can disappear in long chats.
Large files: Long reports or documents must often be split into sections.
Cost vs capability: Larger windows provide more context but require more resources.
Example:
Imagine summarizing a long report. If the report is longer than the model’s context window, only the most recent sections might be considered unless special techniques are used.
Token-Based Pricing: Why Usage Adds Up
Most AI platforms charge based on token usage. This includes both:
Input tokens: The text you send
Output tokens: The text generated in response
The total cost depends on the combined number of tokens processed.
Simple breakdown:
Total tokens = input + output
Pricing is typically calculated per 1,000 tokens
Why this matters:
Efficiency saves money: Shorter prompts reduce cost
Control output: Limiting response length prevents unnecessary usage
Planning: Developers often estimate token usage before sending requests
Example:
Input: 300 tokens (a short question with context)
Output: 450 tokens (a detailed answer)
Total: 750 tokens
This total determines the cost of that interaction.
Retrieval-Augmented Generation (RAG)
RAG enhances LLMs by connecting them to external knowledge sources such as databases, documents, or APIs.
How It Works
- A user submits a query
- Relevant information is retrieved from a knowledge source
- This information is added to the model’s input
- The LLM generates a response grounded in both its training and the retrieved data
Benefits
Produces more accurate, fact-based responses
Keeps information up to date without retraining
Cost-efficient since the base model remains unchanged
Trade-offs
Slightly slower due to the retrieval step
Fine-Tuning: Customizing Intelligence
Fine-tuning takes a pre-trained LLM and further trains it on domain-specific data. This process embeds specialized knowledge directly into the model.
How It Works
- A base model is trained further on curated datasets
- It learns domain terminology, patterns, and workflows
Benefits
- Faster responses (no external lookup required)
- Highly tailored outputs aligned with specific use cases
Trade-offs
Expensive in terms of compute and maintenance
Requires retraining to incorporate new information
RAG vs Fine-Tuning
RAG and fine-tuning serve different but complementary purposes:
RAG is ideal for dynamic, frequently changing knowledge
Fine-tuning is best for consistent, domain-specific expertise
In real-world systems, combining both often yields the best results—fine-tuning for behavior and tone, and RAG for factual accuracy and freshness.
Understanding LLM Performance
The effectiveness of an LLM is closely tied to its size, typically measured by the number of parameters (often in billions). Larger models tend to perform better on complex tasks but require significant computational resources to train and deploy.
This trade-off has led to the rise of smaller, efficient models—sometimes called “mini-giants”—which aim to deliver strong performance with lower cost and latency.