It’s weird how you can muck about with structures for so long and still forget what the hell you’re doing all the time. This post is supposed to try and clarify segment HMMs a bit for me, so that I can approach the learning problem with a clear mind. It’s all very specific; and it’s all below the fold.
I’m going to define the model again. Notation is important:
 : state transition probability
: state transition probability : duration density
: duration density : segment density
: segment density : initial state distribution
: initial state distributionSome things to note.
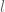 which kind of means the whole thing is still Markovian, though this enough for people to start using terms like ‘semi-Markovian’ which is kind of confusing.
which kind of means the whole thing is still Markovian, though this enough for people to start using terms like ‘semi-Markovian’ which is kind of confusing. is dependent on the state at time . This implies that: and lasts for time steps. This means that the last time index in the ‘current’ segment is
is dependent on the state at time . This implies that: and lasts for time steps. This means that the last time index in the ‘current’ segment is  .
.What we’d like to do is write this out as a properly specified graphical model, but it turns out that this is pretty hard to do for the general case. As a first crack I tried introducing a counting variable 
 : counting variable transition distribution
: counting variable transition distribution : state transition probability conditioned on the counting variable at the previous time point
: state transition probability conditioned on the counting variable at the previous time point : segment density: initial state distribution
: segment density: initial state distributionThe counting variable either decrements or resets, such that 


Similarly, the state variable either stays the same or transitions depending on the counting variable. So 

So we’ve swapped some awkardness in having two ideas of time’s passage – one for the underlying state and one for the observations – with some awkwardness of defining these conditional densities.
As it stands, though, we’re still stuck with a variable topology – the introduction of the counting variable hasn’t really changed the fact that the segment density changes dimension dependent on
The observations aren’t independent though! This is the big difference between Segment HMMs and what are known as explicit-duration HMMs. Hence to be able to draw a graph we must make some assumptions on the form of the output density. Murphy actually states this in one of his technical reports, but it seems to have taken a couple of months for it to actually sink in. Next step, then, is a graphical model for a 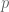
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。