For infrastructure reasons the Fedora flatpaks are delivered using the container registry, rather than OSTree (which is normally used for flatpaks). Container registries are quite inefficient for updates, so we have been getting complaints about large downloads.
I’ve been working on ways to make this more efficient. That would help not only the desktop use-case, as smaller downloads are also important in things like IoT devices. Also, less bandwidth used could lead to significant cost savings for large scale registries.
Containers already have some features designed to save download size. Lets take a look at them in more detail to see why that often doesn’t work.
Consider a very simple Dockerfile:
FROM fedora:32
RUN dnf -y install httpd
COPY index.html /var/www/html/index.html
ENTRYPOINT /usr/sbin/httpd
This will produce an container image that looks like this:
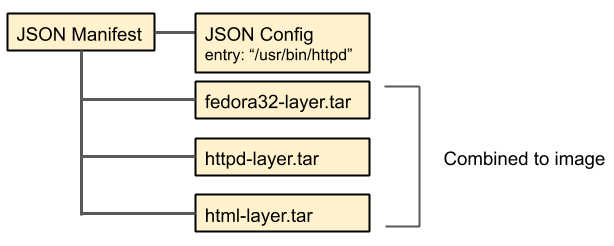
The nice thing about this setup is that if you change the html layer and re-deploy you only need to download the last layer, because the other layers are unchanged.
However, as soon as one of the other layer changes you need to download the changed layer and all layers below it from scratch. For example, if there is a security issue and you need to update the base image all layers will change.
In practice, such updates actually change very little in the image. Most files are the same as the previous version, and the few that change are still similar to the previous version. If a client is doing an update from the previous version the old files are available, and if they could be reused that would save a lot of work.
One complexity of this is that we need to reconstruct the exact tar file that we would otherwise download, rather than the extracted files. This is because we need to checksum it and verify the checksum to protect against accidental or malicious modifications. For containers, the checksum that clients use is the checksum of the uncompressed tarball. Being uncompressed is fortunate for us, because reproducing identical compression is very painful.
To handle such reconstruction, I wrote a tool called tar-diff which does exactly what is needed here:
$ tar-diff old.tar.gz new.tar.gz delta.tardiff
$ tar xf old.tar.gz -C extracted/
$ tar-patch delta.tardiff extracted/ reconstructed.tar
$ gunzip new.tar.gz
$ cmp new.tar reconstructed.tar
I.e. it can use the extracted data from an old version, together with a small diff file to reconstruct the uncompressed tar file.
tar-diff uses knowledge of the tar format, as well as the bsdiff binary diff algorithm and zstd compression to create very small files for typical updates.
Here are some size comparisons for a few representative images. This shows the relative size of the deltas compared to the size of the changed layers:
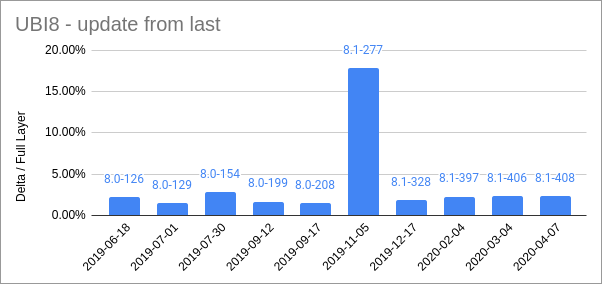
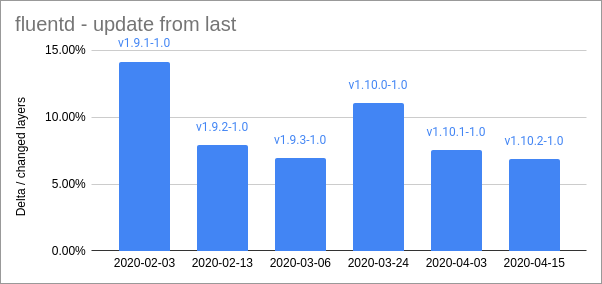
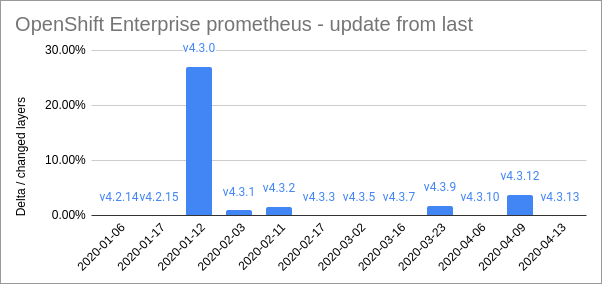
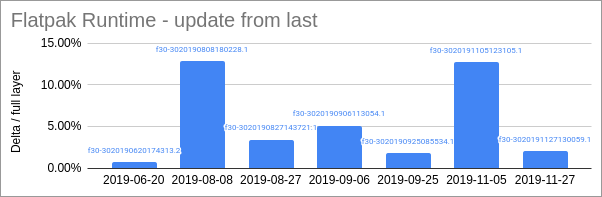
These are some pretty impressive figures. Its clear from this that some updates are really very small, yet we are all downloading massive files anyway. Some updates are larger, but even for those the deltas are in the realm of 10-15% of the original size. So, even in the worst case deltas are giving around 10x improvement.
For this to work we need to store the deltas on a container registry and have a way to find the deltas when pulling an image. Fortunately it turns out that the OCI specification is quite flexible, and there is a new project called OCI artifacts specifying how to store other types of binary data in a container.
So, I was able to add support for this in skopeo and podman, allowing it both to generate deltas and use them to speed up downloads. Here is a short screen-cast of using this to generate and use deltas between two images stored on the docker hub:
All this is work in progress and the exact details of how to store deltas on the repository is still being discussed. However, I wanted to give a heads up about this because I think it is some really powerful technology that a lot of people might be interested in.