Redis 持久化、主从复制、哨兵、分片集群,每个概念单独来看都很容易理解,但它们之间存在哪些联系?Redis为什么会演化出这几种架构模式?这篇文章告诉你答案。
怎么做数据持久化
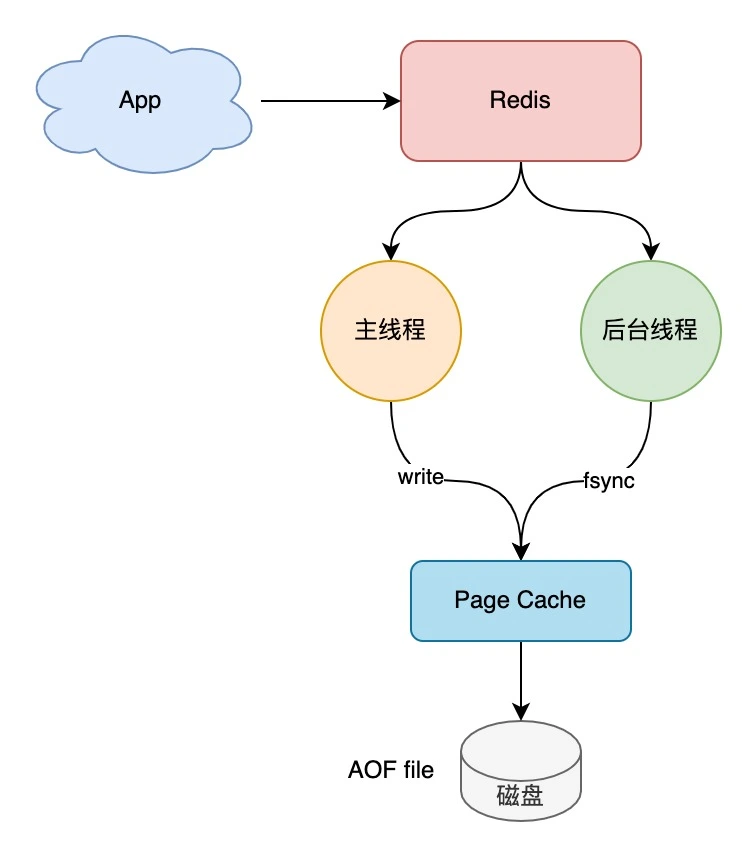
1、AOF——子线程将内存数据进行落盘(对数据完整性支持较好)
- appendfsync always: 主线程同步fsync
- appendfsync no: 由OS fsync
- appendfsync everysec: 定期1s执行fsync
AOF 持续变大,恢复时间变长怎么办?
- 定期rewrite,合并AOF(只需保留最近的状态)
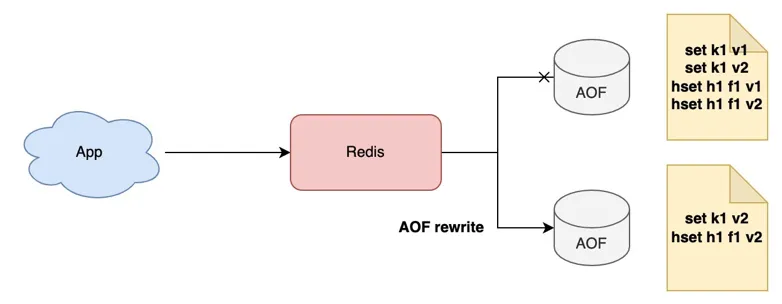
2、RDB定时数据快照(丢失数据不敏感)
- 持久化文件小(二进制、压缩)
- 写磁盘频率低
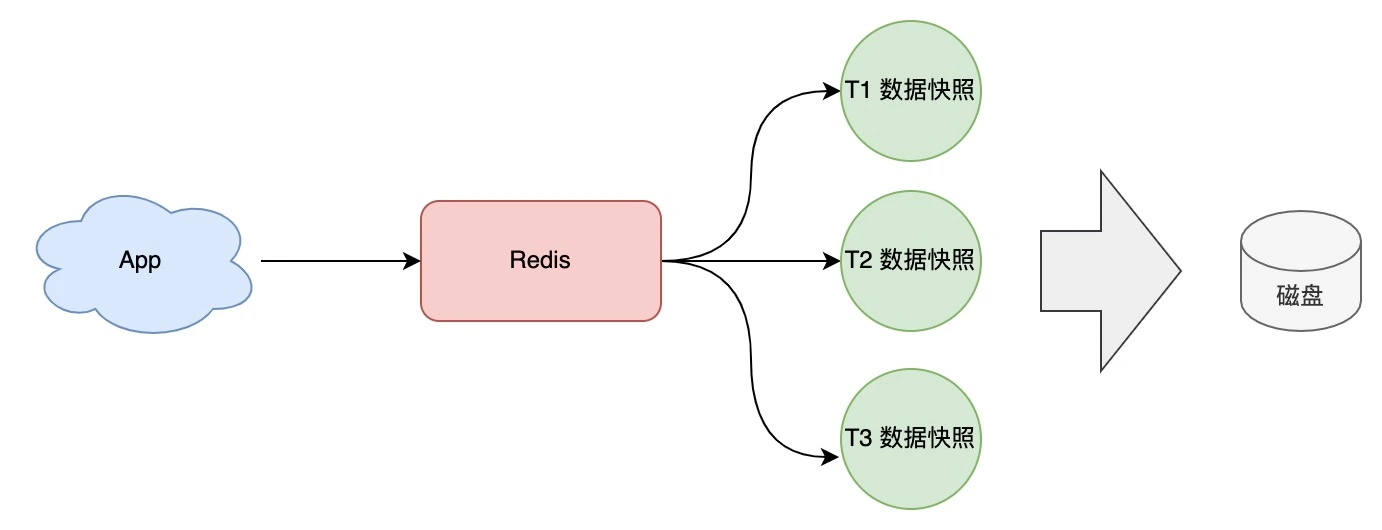
3、混合持久化——综合AOD和RDB
- 定时快照
- 2次快照的间隔使用AOF持久化
主从复制
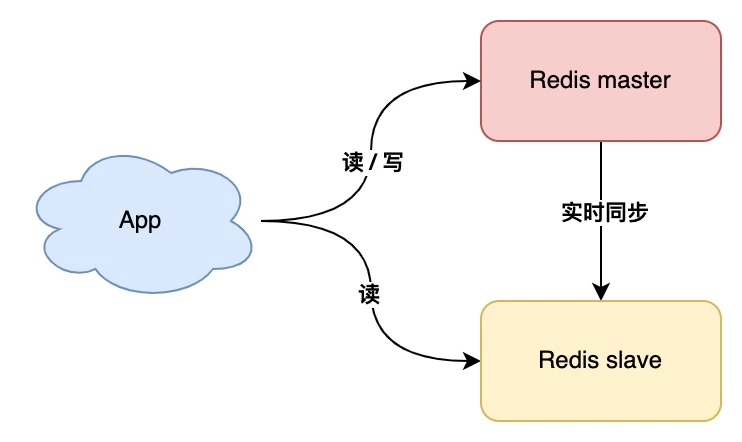
master + 多个 slave 模式
1、master读写,slave只读
2、master 实时同步到slave
3、故障时slave提升为主
哨兵模式
引入观察者角色(哨兵),将slave提升为master的过程自动化。
1、哨兵定期检查master状态
2、master正常应答,继续观测
3、发现master异常,开始发起主从切换
哨兵和master之间网络故障引起误判怎么办?
- 在多个节点部署多个哨兵
- 哨兵监测到master异常数量大于阈值,才判定为故障
由哪个哨兵发起切换?
- 哨兵投票
1个master扛不住怎么办?
分片集群
1、客户端根据key实现路由规则
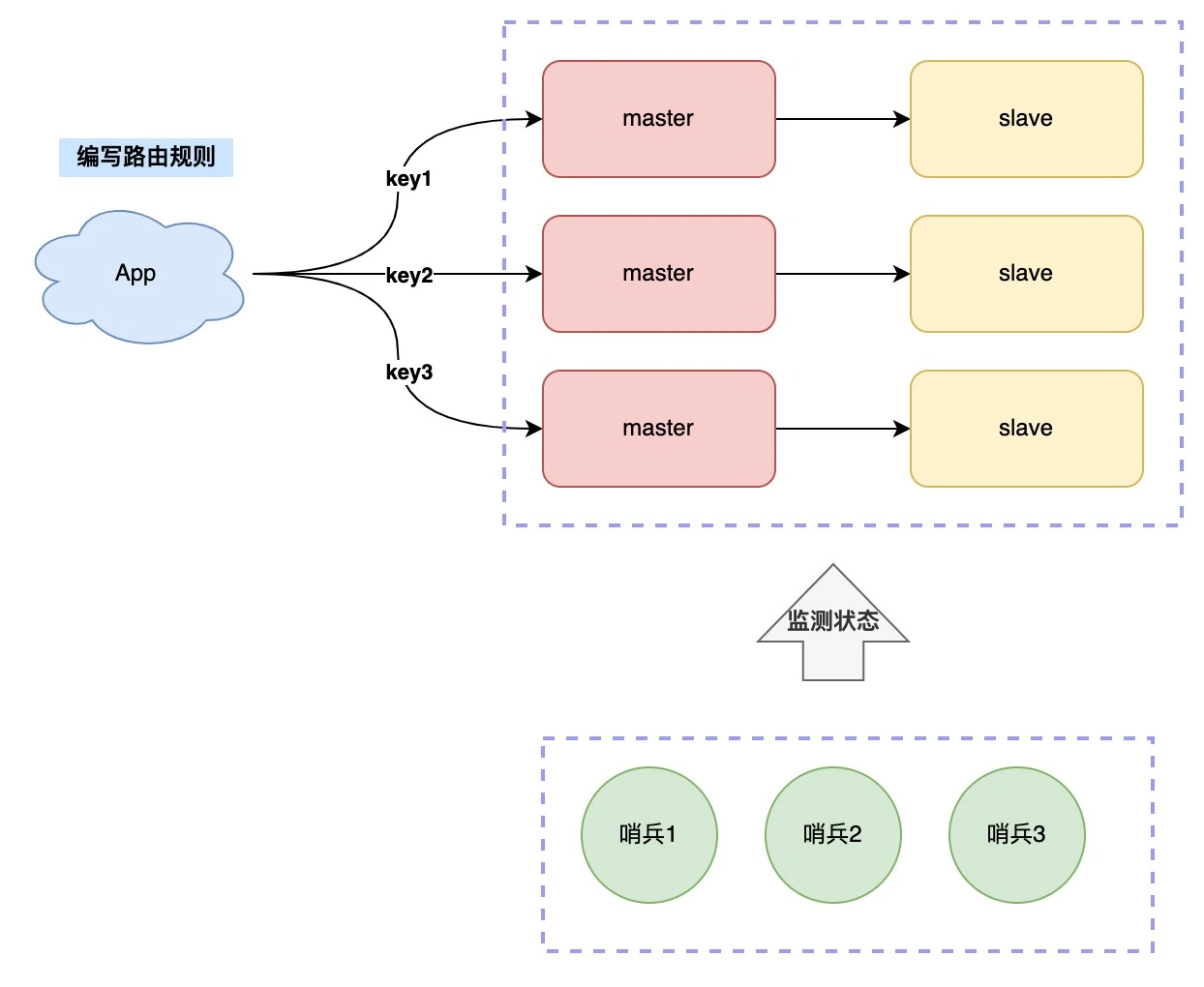
2、proxy模式
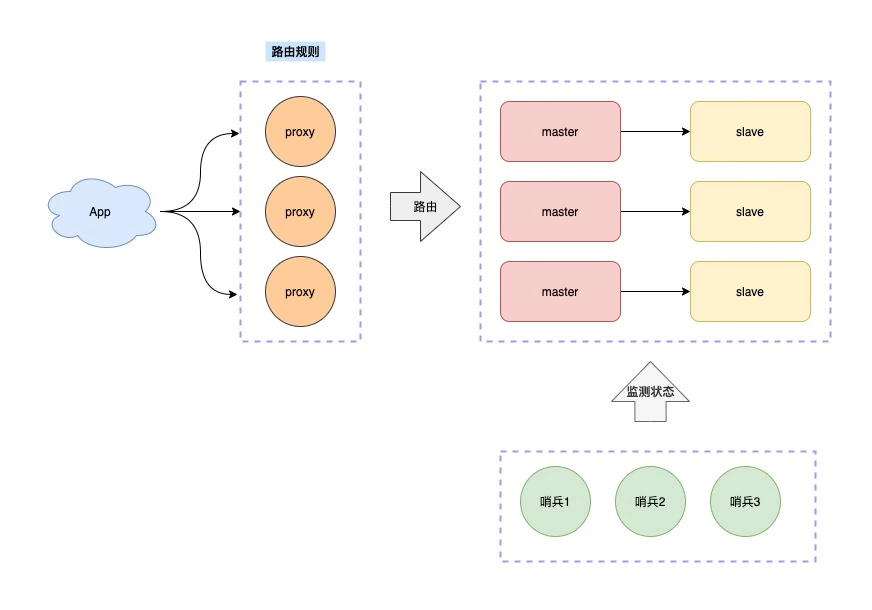
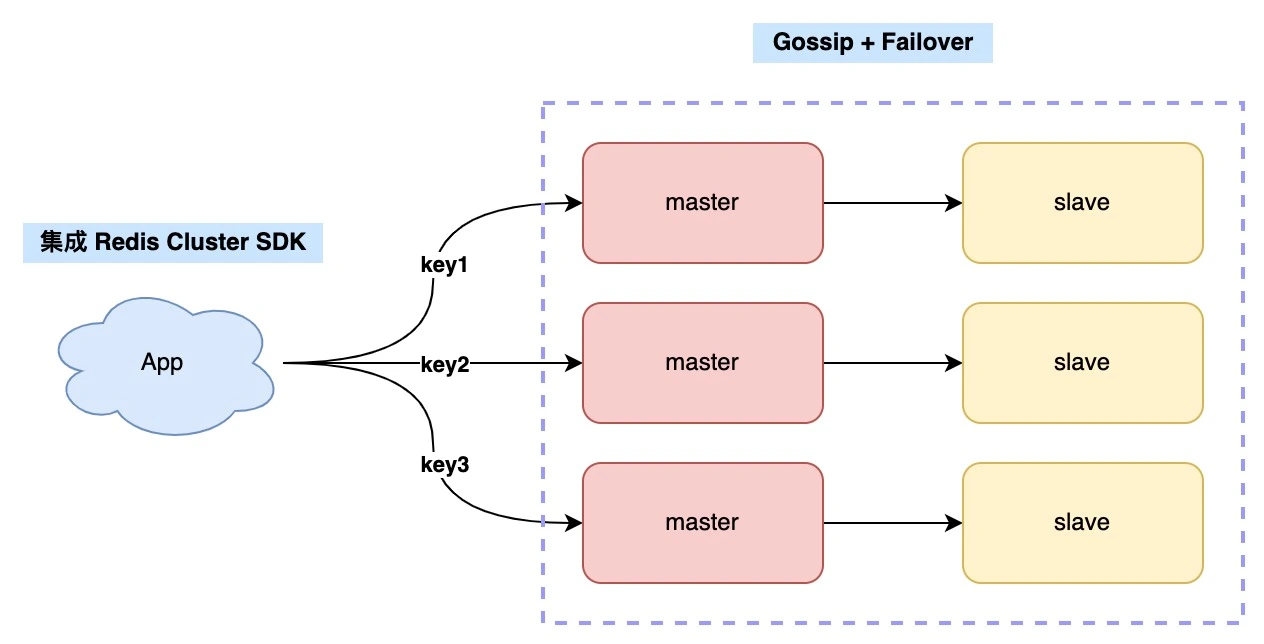
3、官方集群方案
- 无需部署哨兵,节点之间通过gossip协议相互探测健康切换
- 官方提供了sdk用于路由规则,节点删除和增加适配
- 如果老业务升级困难,还可以自己增加一层proxy
总结
总结一下,我们是如何从 0 到 1,再从 1 到 N 构建一个稳定、高性能的 Redis 集群的,从这之中你可以清晰地看到 Redis 架构演进的整个过程。
- 数据怕丢失 -> 持久化(RDB/AOF)
- 恢复时间久 -> 主从副本(副本随时可切)
- 故障手动切换慢 -> 哨兵集群(自动切换)
- 读存在压力 -> 扩容副本(读写分离)
- 写存在压力/容量瓶颈 -> 分片集群
- 分片集群社区方案 -> Twemproxy、Codis(Redis 节点之间无通信,需要部署哨兵,可横向扩容)
- 分片集群官方方案 -> Redis Cluster (Redis 节点之间 Gossip 协议,无需部署哨兵,可横向扩容)
- 业务侧升级困难 -> Proxy + Redis Cluster(不侵入业务侧)
至此,我们的 Redis 集群才得以长期稳定、高性能的为我们的业务提供服务。