如果你常逛技术社区,大概率听过 “大语言模型(LLM)能做很多事”—— 写文案、答问题、编代码,但真要把它放进实际业务里,比如给公司做个智能客服、给团队搭个文档问答工具,却总卡壳:要么模型记不住上下文,聊两句就 “断片”;要么模型不懂专业知识,回答全是 “通用废话”;要么调用外部工具时,得自己写一堆复杂逻辑……
这时候,LangChain 就该登场了。它不是一个新的 AI 模型,而是帮你 “盘活” LLM 的开发框架,像给模型搭了个 “工具箱 + 操作台”,让你不用从零造轮子,就能快速搭建出能用、好用的 LLM 应用。今天就用最通俗的话,带你入门 LangChain。
先抛个结论:LangChain 是连接 LLM 与实际业务的 “桥梁”。
你可以把 LLM 想象成一个 “聪明但没经验的实习生”—— 脑子好使,但不知道公司的业务规则、没有存业务数据的文件夹、不会用公司的办公软件(比如查订单的系统、调数据的 API)。而 LangChain 就是这个实习生的 “带教老师”:
简单说,直接用 LLM 像 “徒手干活”,用 LangChain 就是 “带着工具干活”—— 效率和效果完全不是一个级别。
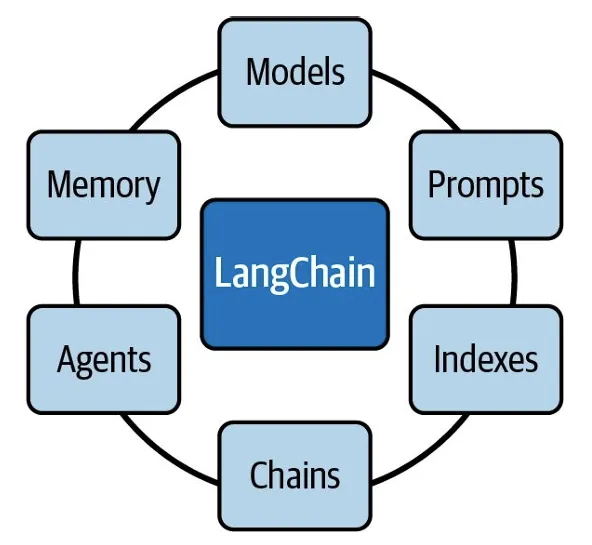
新手不用一开始就啃复杂概念,先记住 LangChain 最常用的 4 个核心能力,覆盖 80% 的入门场景:
1. 记事儿:让 LLM “不健忘”(Memory 功能)
你有没有过这种体验:跟 AI 聊 “帮我推荐一款性价比高的笔记本”,聊到一半说 “再推荐个同价位的平板”,AI 却问 “你说的同价位是多少?”—— 这就是 LLM “健忘”,默认记不住之前的对话。
LangChain 的Memory 模块就是帮 LLM “记事儿” 的:
举个简单代码例子,让 AI 记住对话:
from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationChain from langchain.llms import OpenAI # 初始化记忆模块,存对话历史 memory = ConversationBufferMemory() # 把LLM和记忆模块组合成对话链 conversation_chain = ConversationChain( llm=OpenAI(api_key="你的API密钥"), memory=memory ) # 第一次对话 print(conversation_chain.run("我想买一款适合办公的笔记本,预算5000元")) # 第二次对话,AI会记住“预算5000元” print(conversation_chain.run("有没有同价位的平板推荐?"))
运行后你会发现,AI 不会再问 “预算多少”,直接推荐 5000 元左右的平板 —— 这就是 Memory 的作用。
2. 查资料:让 LLM “懂专业”(Retrieval 功能)
LLM 的 “知识库” 截止到训练时(比如 GPT-4 截止到 2023 年),而且不懂你公司的产品手册、行业文档。想让它回答 “我们公司产品的保修政策”,直接问只会 “瞎猜”。
LangChain 的Retrieval 模块就是帮 LLM “查资料” 的,核心是 “检索增强生成(RAG)”—— 简单说就是:用户提问后,先从你的专业文档里找答案,再让 LLM 基于找到的资料回答,避免 “瞎编”。
比如做一个 “产品手册问答工具”,步骤很简单:
代码示例(用 Chroma 向量库):
from langchain.document_loaders import PyPDFLoader from langchain.vectorstores import Chroma from langchain.embeddings import OpenAIEmbeddings from langchain.chains import RetrievalQA from langchain.llms import OpenAI # 1. 加载产品PDF手册 loader = PyPDFLoader("你的产品手册.pdf") documents = loader.load() # 2. 拆分文档(每段500字,重叠50字保持连贯) from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) splits = text_splitter.split_documents(documents) # 3. 存储到向量库 vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(api_key="你的API密钥")) # 4. 搭建问答链,用户提问时先查资料再回答 qa_chain = RetrievalQA.from_chain_type( llm=OpenAI(api_key="你的API密钥"), chain_type="stuff", # 把找到的资料塞进Prompt里让LLM回答 retriever=vectorstore.as_retriever() ) # 测试:问产品保修政策 print(qa_chain.run("我们产品的保修期限是多久?"))
这样回答的内容完全来自你的产品手册,不会有 “幻觉”,专业度拉满。
3. 串流程:让 LLM “按步骤做事”(Chains 功能)
很多任务不是 “问一句答一句” 这么简单,比如 “先分析用户的问题类型,再决定是查知识库还是直接回答,最后整理成简洁的回复”—— 这需要多步操作,LangChain 的Chains 模块就是帮你 “串流程” 的。
你可以把 Chain 理解成 “任务流水线”:把多个步骤(比如 “处理问题→查资料→生成回答→检查格式”)串起来,让 AI 自动按顺序执行。
比如做一个 “客户投诉处理链”,步骤是:
代码示例(用 SequentialChain 串步骤):
from langchain.prompts import PromptTemplate from langchain.chains import SequentialChain, LLMChain from langchain.llms import OpenAI llm = OpenAI(api_key="你的API密钥") # 步骤1:提取投诉关键词 extract_template = "从用户投诉中提取核心问题:{complaint}\n核心问题:" extract_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(extract_template), output_key="core_issue") # 步骤2:查解决方案(这里简化为让LLM生成,实际可对接知识库) solve_template = "针对投诉核心问题「{core_issue}」,生成解决方案:\n解决方案:" solve_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(solve_template), output_key="solution") # 步骤3:生成标准化回复 reply_template = "用户投诉:{complaint}\n解决方案:{solution}\n请生成标准化回复(包含道歉、方案、联系方式):" reply_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(reply_template), output_key="final_reply")
运行后会直接输出标准化回复,比如:“非常抱歉您的订单延迟未送达,我们已查询到物流卡在 XX 环节,将为您优先协调配送,预计 24 小时内更新物流,如有问题可联系客服热线 400-XXX-XXXX。”
4. 用工具:让 LLM “能干活”(Agents 功能)
有时候,LLM 需要 “动手做事”—— 比如查实时天气、查用户订单、调用翻译 API,这些不是靠 “说” 能解决的,需要调用外部工具。LangChain 的Agents 模块就是让 LLM“自己决定用什么工具、怎么用”。
比如做一个 “智能助手”,能查实时天气(调用天气 API)、算数学题(用计算器工具):
虽然入门阶段不用写复杂的工具调用代码,但你要知道:Agents 是 LangChain “进阶” 的关键 —— 它让 LLM 从 “只会说” 变成 “能做事”,比如自动查订单、自动生成报表、自动发邮件。
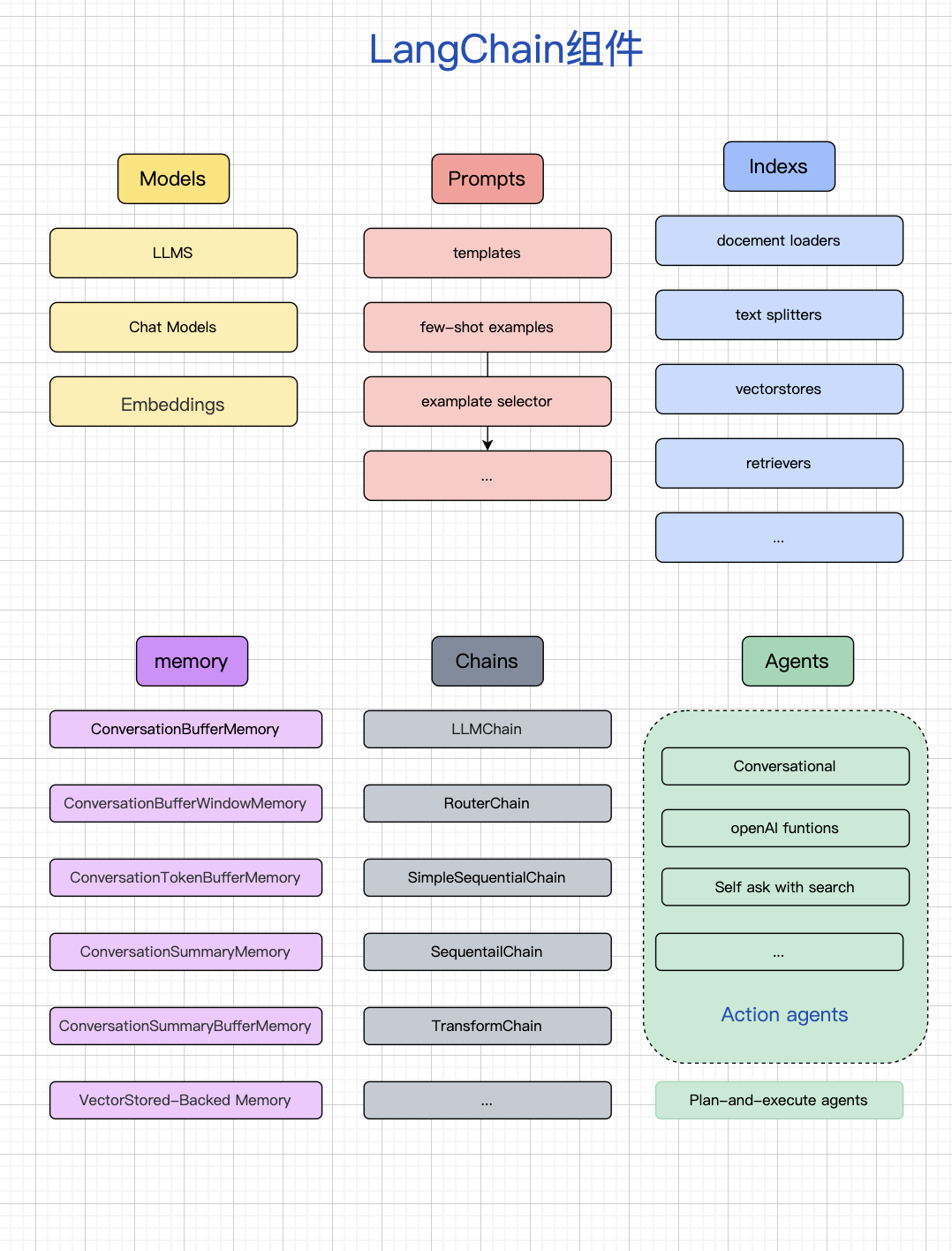
内容
LangChain 提供了对各种大语言模型(LLM)和聊天模型(ChatModel)的统一接口,屏蔽了底层差异(比如 OpenAI、Anthropic、Cohere、本地 LLM)。
细节
包括 LLM、ChatModel、EmbeddingModel 三类。
内置了输出解析器(Output Parser),可以把大模型的自然语言输出转换为结构化数据(JSON、Pydantic 对象、数值等)。
价值
让开发者专注业务逻辑,不必关心不同模型的调用差异和 SDK 繁琐细节。
内容
提供 PromptTemplate、ChatPromptTemplate 等机制,帮助管理复杂的提示(prompt engineering)。
细节
动态变量替换:支持把上下文、用户输入等注入到模板。
Few-shot 示例管理:便于组织多个样例。
消息式提示:结构化地传递 system、user、assistant 等多角色信息。
价值
把 prompt 工程从“硬编码字符串”升级为可配置、可维护、可重用的组件,降低“提示散落在代码里”的混乱。
内容
用于构建 知识库增强生成(RAG) 应用,把外部文档接入大模型。
细节
文本分割器:将长文档切成可检索的 chunk。
向量化存储:支持 Pinecone、Weaviate、FAISS、Chroma 等。
检索器(Retriever):把用户问题转化为向量查询,返回相关文档。
价值
解决了 LLM 无法“记住所有知识”的问题,把专有文档、实时数据整合进大模型回答中。
内容
管理对话的上下文记忆,使得大模型可以“连续对话”。
细节
短期记忆:保存当前会话的上下文(最近几轮对话)。
长期记忆:通过数据库或向量存储保存长期信息。
记忆类型:
ConversationBufferMemory:存储所有对话。
ConversationBufferWindowMemory:只存储最近 N 轮。
VectorStoreRetrieverMemory:基于检索的记忆。
价值
让应用从“一问一答”变成“对话式交互”,接近人类交流体验。
内容
LangChain 的核心抽象,用来把模型调用、提示模板、工具调用、解析等串联起来。
细节
简单链:Prompt → LLM → 输出。
顺序链:多个链按顺序执行。
分支链:根据条件决定走不同子链。
LCEL(LangChain Expression Language):声明式定义链,支持并发、重试、回退。
价值
让开发者能够构建复杂工作流,而不需要自己写一堆控制逻辑。
内容
代理(Agent)是比链更高阶的抽象,让大模型能自主决定调用什么工具、何时调用。
细节
核心思想:大模型通过解析用户问题,决定调用哪些工具(搜索、数据库查询、Python 计算等),然后综合工具结果再生成回答。
工具(Tools):LLM 外的功能模块,比如 API、SQL、计算器。
代理框架:ReAct、Conversational Agent 等。
价值
让 LLM 从“被动回答”升级为“主动规划、调用工具”,成为真正的 智能体(AI Agent)。
看完理论,动手做个最简单的 “文档问答工具”,感受一下 LangChain 的效率:
步骤 1:准备环境
首先安装需要的库(Python 环境):
# 安装LangChain核心库、OpenAI(用GPT模型)、PDF加载器、向量库 pip install langchain openai pypdf chromadb
步骤 2:准备文档
找一个你熟悉的文档(比如《Python 基础语法.pdf》),放在代码同一个文件夹里。
步骤 3:写代码运行
复制下面的代码,替换 “你的 API 密钥” 和 “文档路径”,运行:
# 2. 拆分文档 from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) splits = text_splitter.split_documents(documents) # 3. 存储到向量库 vectorstore = Chroma.from_documents( documents=splits, embedding=OpenAIEmbeddings(api_key="sk-你的OpenAI密钥") # 替换成你的API密钥 ) # 4. 搭建问答链 qa_chain = RetrievalQA.from_chain_type( llm=OpenAI(api_key="sk-你的OpenAI密钥"), chain_type="stuff", retriever=vectorstore.as_retriever() ) # 5. 提问测试 while True: question = input("请输入你的问题(输入q退出):") if question == "q": break print("回答:", qa_chain.run(question))
=
很多新手觉得 Agents “很酷”,不管什么任务都用 Agents,结果代码复杂还容易出错。其实 80% 的简单任务(比如单轮问答、固定流程)用 Chain 就够了,Agents 适合需要 “动态决策” 的场景(比如不确定用哪个工具、需要多轮调用工具)。
做 RAG 时,直接把整个文档扔进去,结果 AI 回答混乱 —— 因为文档太长,拆分后的片段要么不完整,要么包含无关信息。新手建议用「RecursiveCharacterTextSplitter」,把 chunk_size 设为 500-1000 字,chunk_overlap 设为 50-100 字,保持语义连贯。
觉得 “让 LLM 自由发挥更好”,结果回答格式混乱、重点不突出。其实用 Prompt 模板(比如 “请用「问题 + 原因 + 解决方案」的格式回答:{question}”)能让 AI 的回答更规范,新手一定要养成写模板的习惯。
五、总结:LangChain 入门的核心逻辑
新手不用一开始就掌握所有功能,记住一个核心逻辑:LangChain 是 “LLM 的辅助工具集”,你需要什么功能,就用什么模块——
从最简单的 “文档问答”“对话机器人” 做起,慢慢尝试更复杂的场景(比如智能客服、自动化报表),你会发现:原来把 LLM 放进实际业务里,并没有那么难。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。