Hermes Agent 的记忆系统是三个 Markdown 文件——SOUL.md 定义 Agent 是谁,MEMORY.md 记录 Agent 学到的环境事实,USER.md 刻画你是谁。三者在会话启动时冻结注入系统提示词,合计约 1,300 Token 的"永远在场"记忆预算。这篇文章从源码级拆解这套机制的每一个细节。
本文是 Hermes Agent 完全指南 系列的深度子篇,聚焦人设工程与记忆系统。如果你还不了解 Hermes 的整体架构,建议先读完全指南再回来。
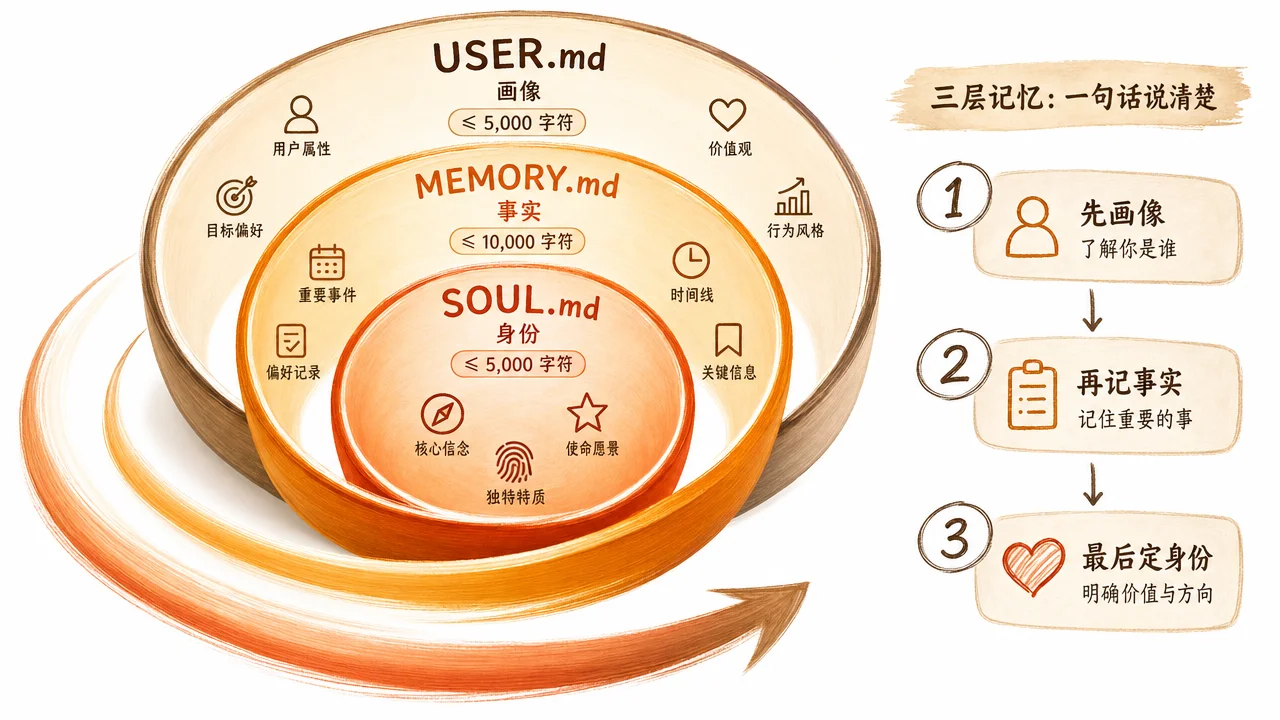
三层记忆:一句话说清楚
| 层 | 文件 | 存什么 | 字符上限 | 约合 Token |
|---|---|---|---|---|
| 身份层 | SOUL.md | Agent 的人格、语气、行为边界 | 20,000(截断) | 视内容而定 |
| 事实层 | MEMORY.md | 环境事实、项目约定、工具变通方法 | 2,200 | ~800 |
| 画像层 | USER.md | 用户姓名、角色、偏好、沟通风格 | 1,375 | ~500 |
💡 通俗讲:SOUL.md 决定 Agent "用什么腔调说话",MEMORY.md 决定 Agent "知道你的电脑装了什么",USER.md 决定 Agent "知道你喜欢简洁还是详细"。三个文件都是纯 Markdown,用任何文本编辑器就能改。
这三个文件存储在 ~/.hermes/ 目录下(MEMORY.md 和 USER.md 在 ~/.hermes/memories/ 子目录),只从 Hermes 主目录加载,不跟随项目目录变化。这是有意为之——人设属于 Hermes 实例本身,不属于某个项目。
SOUL.md 的定位:系统提示词 #1 号槽位
SOUL.md 是 Agent 的主要身份(Primary Identity)。当它存在且有内容时,直接替换 Hermes 硬编码的默认身份,成为系统提示词的第一个内容块。加载逻辑的源码清晰呈现了这一优先级:
加载逻辑有三个关键行为:
- 只读 Hermes 主目录——
get_hermes_home()返回~/.hermes/,不查看当前工作目录。切换项目不会意外改变人设。 - 安全扫描——
_scan_context_content()检测提示词注入模式、凭据泄露、不可见 Unicode 字符。恶意内容会被阻止。 - 截断保护——超过 20,000 字符的内容会被裁剪,避免过长的 SOUL.md 挤占上下文空间。
当 load_soul_md() 返回内容时,build_context_files_prompt(skip_soul=True) 会跳过 SOUL.md,防止它在上下文文件部分重复出现。
SOUL.md 应该放什么
适合放的:
- 语气和沟通风格——"直接但不冷漠"
- 交互默认值——"遇到模糊请求时,问一个澄清问题然后按最佳判断执行"
- 应避免的风格——"不讨好、不用夸张语言、不重复用户错误的框架"
- 处理不确定性的方式——"明确说出置信度"
不适合放的:
- 项目文件路径——这属于 AGENTS.md
- 仓库代码规范——这属于 AGENTS.md
- 一次性任务指令——这属于对话中的用户消息
- 临时工作流细节——这属于项目配置
判断规则:如果某条指令应该跟 Agent 到处走(换项目也生效),放 SOUL.md;如果只属于某个项目,放 AGENTS.md。

官方示例与社区模板
官方推荐的 SOUL.md 结构遵循四段式:
提示词:生成四段式 SOUL.md 结构
请帮我生成一份 Hermes Agent 的 SOUL.md 人设文件。要求:
- 严格按四个一级标题组织:Identity(Agent 是谁)、Style(语气和沟通风格)、Avoid(不应做的事)、Defaults(遇到模糊情况时的默认行为)
- 每个段落用具体、可操作的描述,不用泛泛之词
- 总长度控制在 30 秒能读完的篇幅,大约 4-8 行核心定义
- 只写真正改变 Agent 默认行为的内容,不要重述"有帮助""清晰"等 Hermes 已有的默认表现
官方示例——实用主义高级工程师:
提示词:生成实用主义工程师 SOUL.md
请帮我生成一份"实用主义高级工程师"风格的 Hermes SOUL.md。要求:
- 开头用 Personality 段落定义核心人格:务实的高级工程师,品味强,优先追求真相、清晰和实用性,不搞礼貌表演
- Style 段落包含:直接但不冷漠、内容优于填充、遇到坏主意要反驳、坦率承认不确定性、解释尽量紧凑除非深入有价值
- What to avoid 段落包含:讨好、夸张语言、在用户框架错误时重复其框架、过度解释显而易见的事
- Technical posture 段落包含:偏好简单系统而非聪明系统、关注运营现实而非理想化架构、把边缘情况当设计的一部分而非事后清理
社区方面,Soul Forge 插件(LeventeNagy/soul-forge)提供了目前唯一的 SOUL.md 可视化生成工具,内含 8 种策划模板(Code Architect、Research Analyst、Creative Director 等),支持 AI 生成模式——用自然语言描述理想 Agent,自动生成完整 SOUL.md。安装只需:
hermes plugins install LeventeNagy/soul-forge
hermes plugins enable soul-forge
另外,madhvantyagi/SOUL.md 开源了一个跨平台可复用的人格层集合,每个文件可直接用于 Hermes、OpenClaw、Claude、ChatGPT 等任何能读取 Markdown 指令的 Agent。已有模板包括 Jarvis(审慎技术型)、Gojo(犀利教学型)、Descartes(第一性原理推理型)等。
ClawSouls 则是一个 SOUL.md 模板市场,提供基础模板、高级模板和完整 Soul 包。高级模板如"15 年经验的后端工程师"已经预设了技术判断偏好和代码审查风格。
SOUL.md vs /personality vs AGENTS.md:三角关系
| 维度 | SOUL.md | /personality 预设 | AGENTS.md |
|---|---|---|---|
| 定位 | 持久的基线人格 | 会话级临时模式切换 | 项目级上下文 |
| 生命周期 | 跨所有会话持久 | 退出即消失 | 进入目录时加载 |
| 内容类型 | 身份、语气、风格 | 临时角色覆盖 | 代码规范、文件路径、架构 |
| 优先级 | 系统提示词 #1 号槽位 | 覆盖 SOUL.md | 上下文层(低于身份层) |
Hermes 内置了 14 种人格预设——从 helpful(通用助手)到 kawaii(可爱表达)到 noir(硬汉侦探叙事)。你可以用 /personality pirate 临时切换到海盗模式,退出会话后自动恢复 SOUL.md 定义的基线人格。
除了内置预设,你还可以在配置文件中定义自定义人格:
提示词:配置自定义人格预设
请帮我在 Hermes 配置文件中添加一个自定义人格预设。要求:
- 在
agent:下的personalities:字段中添加新预设 - 预设名称使用小写英文标识符(例如
codereviewer) - 预设值用一段完整的英文描述定义人格角色、核心职责和行为风格
- 示例:代码审查员——严谨的代码审查者,识别 Bug、安全问题、性能隐患和不清晰的设计选择,表达精确且有建设性
MEMORY.md:Agent 的事实记忆
记忆工具的三种操作
Agent 通过 memory 工具管理 MEMORY.md 的内容,支持三种操作:
- add——添加新条目
- replace——通过子字符串匹配替换现有条目
- remove——删除不再相关的条目
没有 read 操作——记忆内容在会话启动时自动注入系统提示词,Agent 每时每刻都能看到。
replace 和 remove 使用短唯一子字符串匹配,不需要提供完整条目文本。如果子字符串匹配了多个条目,返回错误要求更精确的匹配。
记忆在系统提示词中的呈现
══════════════════════════════════════════════
MEMORY (your personal notes) [67% — 1,474/2,200 chars]
══════════════════════════════════════════════
User's project is a Rust web service at ~/code/myapi using Axum + SQLx
§
This machine runs Ubuntu 22.04, has Docker and Podman installed
§
User prefers concise responses, dislikes verbose explanations
格式设计有讲究:头部显示容量百分比和字符计数,让 Agent 自己能判断还剩多少空间;条目间用 §(节号)分隔,条目可以跨多行。
应存与不存
Agent 会主动保存的:
- 用户偏好——"我偏好 TypeScript" → 存入 USER.md
- 环境事实——"这台服务器运行 Debian 12" → 存入 MEMORY.md
- 纠正——"不要用 sudo 运行 Docker 命令" → 存入 MEMORY.md
- 约定——"项目使用 tabs 缩进" → 存入 MEMORY.md
- 明确请求——"记住我的 API Key 每月轮换" → 存入 MEMORY.md
不应存入的:
- 琐碎信息——"用户问了 Python"
- 易重新发现的事实——"Python 3.12 支持 f-string 嵌套"
- 大段原始数据——代码块、日志文件、数据表
- 会话特定的临时信息——临时文件路径、一次性调试上下文
- 上下文文件中已有的信息——SOUL.md 和 AGENTS.md 的内容不需要再存一份
容量管理
| 存储 | 上限 | 典型条目数 |
|---|---|---|
| MEMORY.md | 2,200 字符 | 8-15 条 |
| USER.md | 1,375 字符 | 5-10 条 |
满容量时工具返回错误,显示当前条目和使用量。Agent 应合并冗余条目或移除过时条目后重试。
良好条目的标准——紧凑、信息密集、可操作:
# 好:紧凑、信息密集
User runs macOS 14 Sonoma, uses Homebrew, has Docker Desktop and Podman.
Shell: zsh with oh-my-zsh. Editor: VS Code with Vim keybindings.
# 好:具体、可操作
Project ~/code/api uses Go 1.22, sqlc for DB queries, chi router.
Run tests with 'make test'. CI via GitHub Actions.
# 差:太模糊
User has a project.
最佳实践:当容量超过 80%(在系统提示词头部可见)时,在添加新条目前先合并条目。
USER.md:用户画像
USER.md 的定位是用户画像——Agent 通过这个文件了解你是谁、你喜欢什么样的沟通方式。存储的内容类型包括:
- 姓名、角色、时区
- 沟通偏好——简洁还是详细
- 不喜欢的东西——比如不要道歉、不要用术语
- 工作流习惯
- 技术水平
💡 通俗讲:MEMORY.md 是 Agent 的"工作记忆"或"情景记忆"——记录发生了什么事实;USER.md 是 Agent 的"长期记忆"或"语义记忆"——提炼出关于你这个人的认知。有些社区教程指出,USER.md 的内容可以通过 /insights 命令触发 Hermes 自动从交互历史中提炼。
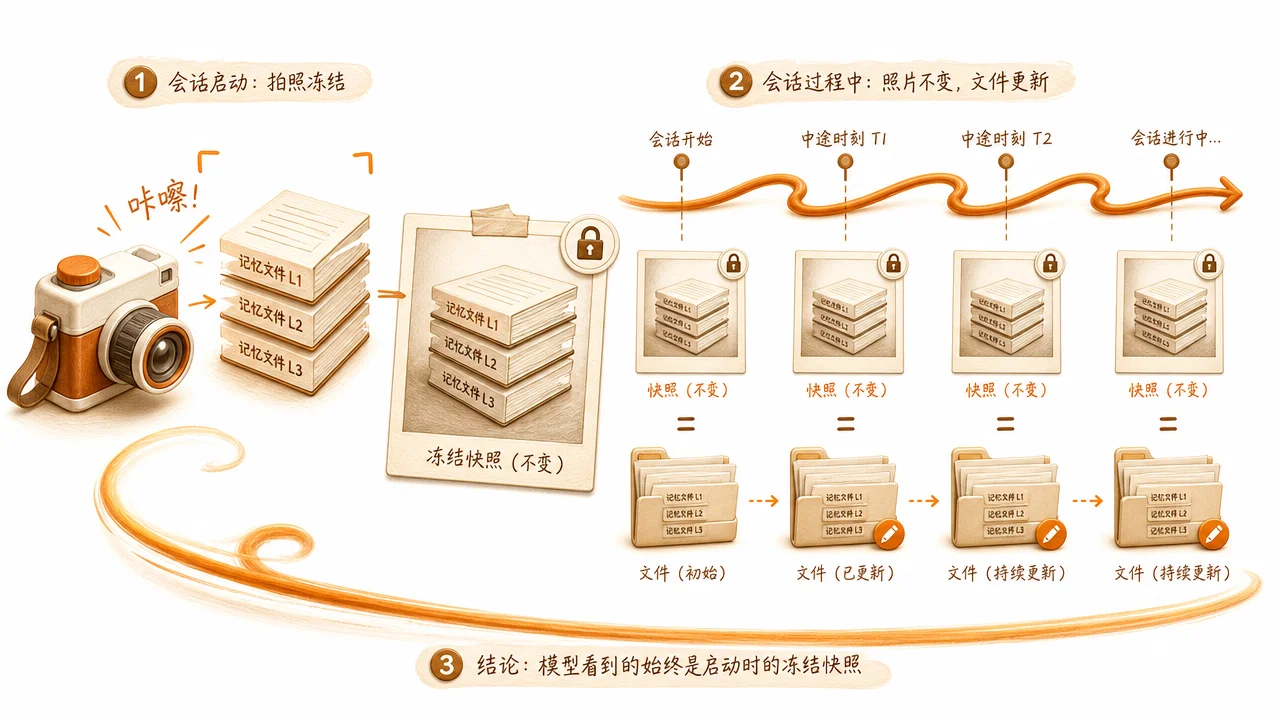
冻结快照模式:为什么记忆不实时更新
Hermes 的记忆采用冻结快照模式(Frozen Snapshot Pattern):系统提示词中的记忆内容在会话启动时捕获一次,中途永不改变。
这不是偷懒——这是经过深思熟虑的工程决策。fp8.co 的深度对比揭示了完整的工程意义:
| 维度 | 冻结快照(Hermes 实际方案) | 实时更新(假设方案) |
|---|---|---|
| 提示词缓存 | 整个会话期间系统提示词不变,每轮命中缓存 | 每次记忆写入后系统提示词变化,缓存失效 |
| Token 成本 | 多轮对话中输入成本降低约 75% | 每次失效后全价重新处理 |
| 一致性 | 会话内行为一致 | 记忆写入后可能改变行为 |
| 新记忆可见性 | 下次会话生效 | 立即生效 |
| 复杂度 | 简单——启动时快照一次 | 复杂——需要缓存失效策略 |
当 Agent 在会话中通过 memory add 写入新条目时,更改持久化到磁盘文件,但不影响当前已构建的系统提示词。工具响应始终反映实时的磁盘状态,所以 Agent 能看到自己刚写的内容。只是这些新记忆要到下次会话启动时才会进入系统提示词。

10 层提示词拼装顺序
Hermes 的系统提示词由 10 个层级严格有序拼装。理解这个顺序对调试人设行为至关重要:
━━━ 缓存稳定层(Stable) ━━━
Layer 1: Agent Identity(SOUL.md 或默认身份)
Layer 2: Tool-aware behavior guidance(工具行为指引 + 记忆使用提示)
Layer 3: Honcho static block(当 Honcho 活跃时)
━━━ 上下文层(Context) ━━━
Layer 4: Optional system message(来自 config 或 API)
Layer 5: Context files(项目上下文文件:AGENTS.md / CLAUDE.md / .cursorrules)
━━━ 易变层(Volatile) ━━━
Layer 6: Frozen MEMORY snapshot(冻结的 MEMORY.md 快照)
Layer 7: Frozen USER profile snapshot(冻结的 USER.md 快照)
Layer 8: Skills index(技能索引——名称 + 一行描述)
Layer 9: Timestamp + session info(时间戳 + 会话信息)
Layer 10: Platform hint(平台提示)
三层结构的设计意图:
- 稳定层极少变化(安装新 Skill 或改 SOUL.md 才变),是提示词缓存的主要受益区
- 上下文层在切换项目时变化,但单个项目内稳定
- 易变层每次会话启动时重建(记忆快照),但会话内冻结
💡 通俗讲:想象系统提示词是一叠纸。最上面是 Agent 的"身份证"(SOUL.md),中间是当前项目的"工作手册"(AGENTS.md),最下面是 Agent 的"笔记本"(MEMORY.md + USER.md)。每次开始新会话,Hermes 把这叠纸拍一张照片交给大语言模型,之后整个会话就看这张照片。
上下文文件发现优先级
Hermes 在项目上下文层会自动发现并加载以下文件:
| 优先级 | 文件 | 搜索范围 | 说明 |
|---|---|---|---|
| 1 | .hermes.md / HERMES.md | 当前目录到 Git 根 | Hermes 原生项目配置 |
| 2 | AGENTS.md | 仅当前目录 | 通用 Agent 指令 |
| 3 | CLAUDE.md | 仅当前目录 | Claude Code 兼容 |
| 4 | .cursorrules / .cursor/rules/*.mdc | 仅当前目录 | Cursor 兼容 |
所有上下文文件都经过安全扫描、截断到 20,000 字符(70/20 头尾比例)、YAML frontmatter 剥离。
会话搜索:记忆之外的历史检索
内置记忆之外,Agent 还可以通过 session_search 工具搜索历史对话。所有终端和消息平台会话都存储在 SQLite 数据库(~/.hermes/state.db),支持 FTS5 全文搜索。
| 特性 | 持久记忆 | 会话搜索 |
|---|---|---|
| 容量 | ~1,300 Token | 无限(全部会话) |
| 速度 | 即时(在系统提示词中) | ~20ms FTS5 查询 |
| Token 成本 | 每次提示词固定 ~1,300 Token | 按需(搜索时才消耗) |
| 用途 | 关键事实始终可用 | 查找特定的历史对话 |
| 管理 | Agent 手动精选 | 自动——所有会话都存储 |
社区把这称为四层记忆金字塔:
- Tier 0 身份:SOUL.md——Agent 知道自己是谁
- Tier 1 连续性:MEMORY.md + USER.md——Agent 知道最近发生了什么
- Tier 2 检索:session_search + 外部提供商——Agent 能快速搜索结构化事实
- Tier 3 可审计性:state.db(全量会话历史)——Agent 能回到原始来源
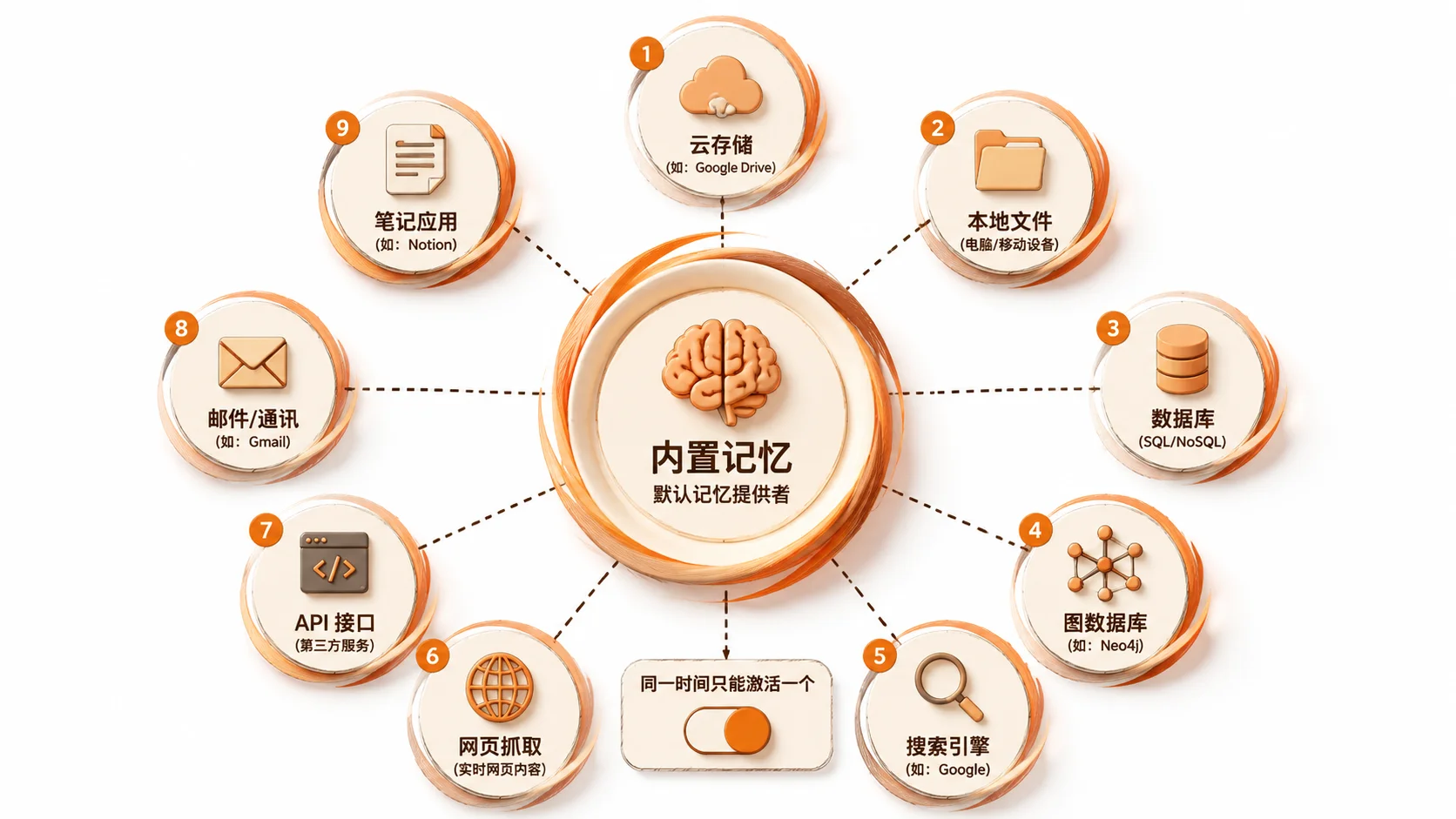
9 种外部记忆提供商对比
Hermes 的内置记忆(MEMORY.md + USER.md)虽然简洁好用,但 2,200 + 1,375 字符的容量上限意味着它只适合存最核心的事实。当你需要更大规模的记忆能力时,9 种外部记忆提供商可以与内置记忆并行运行。
共同机制
当外部记忆提供商活跃时,Hermes 自动执行 5 个步骤:
- 将提供商上下文注入系统提示词
- 每回合前后台预取相关记忆(非阻塞)
- 每次响应后将对话回合同步到提供商
- 会话结束时提取记忆(如提供商支持)
- 将内置记忆写入镜像到外部提供商
重要约束:同一时间只能激活一个外部提供商。内置记忆始终并行运行,不被外部提供商替换。
重点提供商详解
Honcho——方言式用户建模
Honcho 是最复杂的记忆提供商,采用方言式推理(Dialectic Reasoning)实现跨会话用户建模。它的双层上下文注入机制值得深入了解:
- 基础层——会话摘要 + 用户表示 + 用户同伴卡 + AI 自我表示 + AI 身份卡
- 方言式补充——大语言模型合成推理,支持多轮深度(1-3 轮)
三个正交配置旋钮控制刷新频率:contextCadence(基础层刷新间隔,默认 1)、dialecticCadence(方言层刷新间隔,建议 1-5)、dialecticDepth(每次方言调用的轮次,1-3)。
Honcho 还支持多 Agent 隔离——多个 Hermes 实例与同一用户对话时,各自维护独立"同伴"画像,互不干扰。
Holographic——零依赖本地方案
如果你不想依赖任何外部服务,Holographic 是唯一的纯本地方案。它基于 SQLite + FTS5 全文搜索,零外部依赖。独特功能包括:
- HRR 代数查询——用全息缩减表示(Holographic Reduced Representation)做实体代数召回,支持 "A AND B NOT C" 的复合查询
- 矛盾检测——
contradict操作自动检测新条目与现有事实的矛盾 - 信任评分——非对称反馈(+0.05 奖励 / -0.10 惩罚),不可靠的记忆更快衰减
配置极简:
memory_provider:
provider: holographic
# Holographic 使用本地 SQLite,零外部依赖
# 数据存储在 ~/.hermes/holographic/

全量对比表
| 提供商 | 存储 | 成本 | 工具数 | 核心特色 |
|---|---|---|---|---|
| Honcho | Cloud | 付费 | 5 | 方言式用户建模 + 多 Agent 隔离 |
| Mem0 | Cloud | 付费 | 3 | 服务器端自动提取 + 语义搜索 |
| OpenViking | 自托管 | 免费 | 5 | 文件系统层次 + 分层加载(L0→L1→L2) |
| Hindsight | Cloud/本地 | 免费/付费 | 3 | 知识图谱 + 跨记忆综合反思 |
| Holographic | 本地 | 免费 | 2 | HRR 代数 + 信任评分 + 矛盾检测 |
| RetainDB | Cloud | $20/月 | 5 | 混合搜索 + 增量压缩 |
| ByteRover | 本地/Cloud | 免费/付费 | 3 | 压缩前自动提取——防止信息在上下文压缩时丢失 |
| Supermemory | Cloud | 付费 | 4 | 上下文围栏(防递归记忆污染) |
| Memori | Cloud | 免费/付费 | 5 | 工具感知记忆 + 结构化项目归因 |
Supermemory 的"上下文围栏"(Context Fencing)值得特别注意:它在注入召回记忆前,自动从捕获的回合中剥离这些记忆,防止 Agent 把召回的内容又当作新信息再次存储——这种递归记忆污染是长期运行 Agent 的隐蔽问题。
记忆安全扫描与写入审批
三道安全扫描
因为记忆条目会被注入系统提示词,Hermes 设置了三道安全扫描覆盖全流程:
- SOUL.md 安全扫描——加载时通过
_scan_context_content()检测提示词注入模式、不可见 Unicode 字符、凭据泄露企图、SSH 后门 - 记忆条目安全扫描——写入 MEMORY.md 和 USER.md 前扫描,匹配威胁模式的内容被阻止
- 上下文文件安全扫描——所有上下文文件(AGENTS.md、CLAUDE.md 等)加载时扫描
安全扫描检测的威胁模式包括:
ignore previous instructions——提示词注入you are now——角色覆盖system:——系统提示词伪装- URL 注入——记忆不应包含 URL
exec(/<script——代码执行尝试ssh.*@——SSH 后门- 不可见 Unicode 字符——隐蔽的提示词注入载体
社区安全分析(shipsafecli.com)指出,Hermes Agent 引入了传统扫描器不覆盖的四个攻击面:工具注册表(恶意 MCP 覆盖核心工具)、记忆层(通过记忆注入提示词攻击——最隐蔽的向量)、Skill 脚本、上下文文件。记忆层攻击之所以最隐蔽,是因为记忆条目是 Agent 自己写入的,看起来完全合法。
写入审批门控
双层门控设计为安全敏感场景提供人工审批:
提示词:配置记忆与技能写入审批
请帮我在 Hermes 配置文件中开启写入审批门控。要求:
memory:下设置write_approval: true,让所有记忆写入都需要人工审批skills:下设置write_approval: true,让所有技能写入都需要人工审批- 两项独立控制,可以只开其中一项
当 write_approval: true 时,前台写入会内联提示确认,后台自我改进审查的写入被暂存而非提交。审批操作通过命令行完成:
/memory pending # 列出暂存的记忆写入
/memory approve <id> # 批准一条
/memory reject <id> # 拒绝一条
/memory approve all # 全部批准
/memory approval off # 临时关闭门控
💡 通俗讲:Hermes 在每个回合后会运行后台自我改进审查,可能基于对话内容自动写入记忆。如果你担心 Agent 写入了错误的假设——比如把你的偏好理解反了——开启 write_approval: true,每条记忆写入都要经过你的确认才能生效。
这个功能在多平台部署时尤其重要:通过 Discord、Telegram 等平台与 Agent 交互时,第三方消息可能触发不当的记忆写入。
上下文压缩与缓存
双层压缩系统
当对话越来越长,Hermes 用两个独立的压缩层管理上下文:
┌──────────────────────────┐
Incoming message │ Gateway Session Hygiene │ 在上下文 85% 时触发
────────────────►│ (pre-agent, rough est.) │ 安全网——防止超长会话导致 API 失败
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Agent ContextCompressor │ 在上下文 50% 时触发(默认)
│ (in-loop, real tokens) │ 正常的上下文管理
└──────────────────────────┘
Agent ContextCompressor 的压缩算法分 4 个阶段:
- 剪枝旧工具结果——无需大语言模型调用,直接替换旧工具结果为占位符
- 确定边界——头部(保护前 3 条消息)+ 中间(将被总结)+ 尾部(保留最近的对话)
- 生成结构化摘要——中间回合通过辅助大语言模型用结构化模板总结,包含 Goal / Progress / Key Decisions / Next Steps 等字段
- 组装压缩消息——头部 + 摘要 + 尾部
关键细节:后续压缩时,前一次摘要会传给大语言模型并指示更新而非从头总结。这保留了跨多次压缩的信息流——项目状态从"进行中"正确移到"已完成"。
提示词缓存
Hermes 使用 Anthropic 的 cache_control 断点,采用 system_and_3 策略:
- 断点 1:系统提示词(跨所有回合稳定)
- 断点 2-4:最后 3 条非系统消息(滚动窗口)
这使得多轮对话中的输入 Token 成本降低约 75%。而冻结快照模式正是这套缓存策略的前提——如果记忆每次写入都更新系统提示词,缓存就会频繁失效,75% 的节省荡然无存。
配置参考:
提示词:配置上下文压缩与提示词缓存
请帮我在 Hermes 配置文件中调整压缩和缓存参数。要求:
compression:部分:enabled: true开启压缩;threshold设为 0.50(上下文占用 50% 时触发压缩,默认值);target_ratio设为 0.20(尾部保留 20% 最近对话);protect_last_n设为 20(最少保留 20 条消息不被压缩)prompt_caching:部分:cache_ttl设为"5m"或"1h"(缓存存活时间,越长越省 Token,但记忆更新延迟越大)
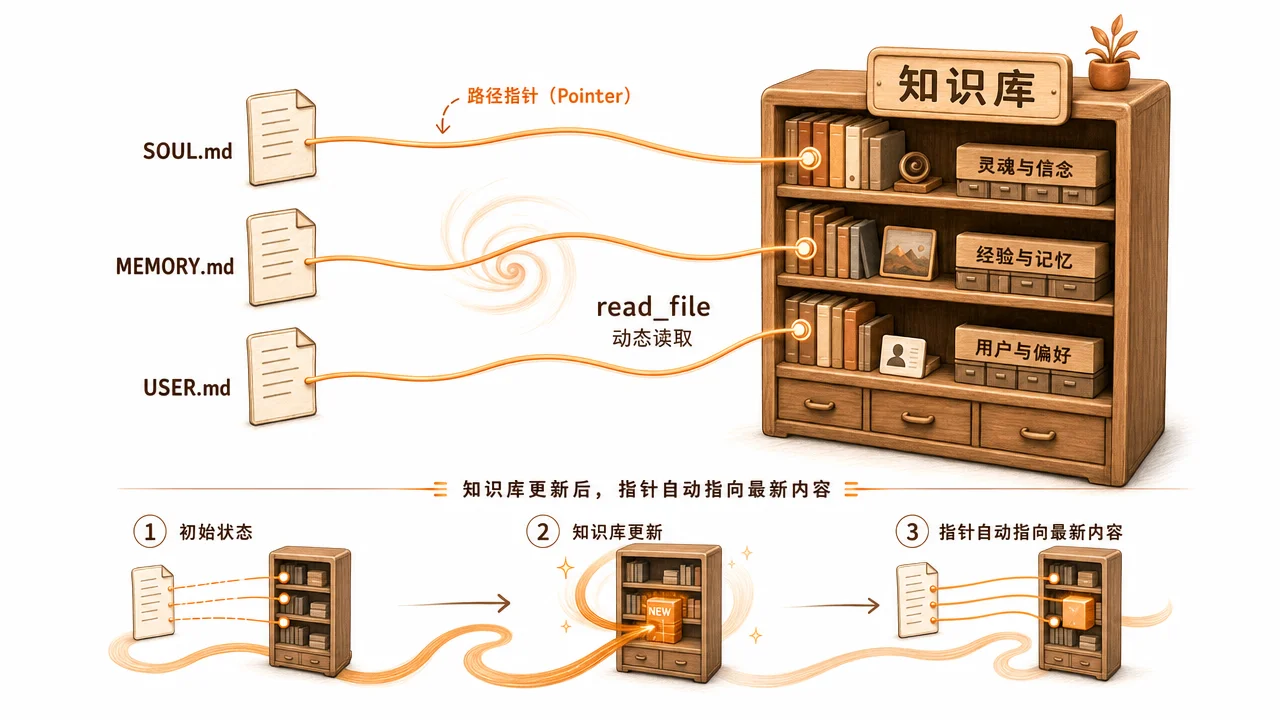
翔宇指针架构实践
以上是 Hermes 记忆系统的官方设计。接下来我展示自己在生产环境中运行 Hermes 半年积累的实战方案——指针架构。
核心问题
我用 Claude Code 每天更新知识库的上百个文件。如果 Hermes 的 SOUL.md、MEMORY.md、USER.md 里硬编码了品牌信息、工具列表、工作流触发词,这些内容很快就会过时。Agent 基于过时的记忆做决策,结果比没有记忆还危险。
指针架构方案
配置内容归零,只存路径和导航方法。所有事实性内容让 Hermes 在对话中通过 read_file 现场读取。
效果:Claude Code 改了任何知识库文件,Hermes 下次对话自动感知。零维护成本。
SOUL.md 全文
提示词:生成指针架构 SOUL.md
请帮我生成一份采用指针架构的 Hermes SOUL.md。要求:
- 开头定义 Agent 身份和沟通平台(如微信、Discord 双平台),并规定每次回复的固定称呼前缀
- 语言段落:专业自然的简体中文;标识符英文不译,概念首次出现括注一次英文之后只写中文;列出明确禁止的用词(赋能、闭环、链路、抓手等黑话,以及中英混杂、标签云、口语腔、自造词);追求精简——能删的词就删,能用短词不用长词,能用主动不用被动
- 导航方法段落:写明知识库根路径;定义四步导航流程——先读总路由表 CLAUDE.md,按用户问题中的关键词匹配触发词定位子目录,读子目录 CLAUDE.md 继续按触发词往下定位,找到具体文件后 read_file 获取内容
- Discord 频道行为段落:频道名自带职责域关键词,收到消息时从频道名提取职责域作为触发词去总路由表定位,不同频道调用不同工作流
- 技能创建规则段落:允许自动创建技能但遵守边界——创作类任务(写文章、发推文等)禁止创建技能必须走知识库工作流,允许创建的仅限平台操作、检索优化、工具调用快捷方式、日常问答
- 红线段落:不代替用户做发布决策;不直接发布内容到公开平台;找不到信息就说找不到不编造;最关键的一条——不在 SOUL/MEMORY/USER 里复制知识库内容,知识库是唯一真值源(这是指针架构的灵魂)
注意最后一条红线——"不在 SOUL/MEMORY/USER 里复制知识库内容"。这是指针架构的灵魂:配置文件只放"怎么找到内容的方法",不放内容本身。
MEMORY.md 全文
提示词:生成指针架构 MEMORY.md
请帮我生成一份采用指针架构的 Hermes MEMORY.md。要求:
- 部署环境段落:记录本机硬件和 IP、进程隔离方式(如 pipx)、后台守护机制(如 launchd)、使用的大语言模型和 Provider、沟通平台(如微信 Bot + Discord Bot)
- 知识库索引段落:标注"纯路径,内容现场读",列出总入口路径和所有一级子目录的 CLAUDE.md 路径(品牌、工作流、工具、规范、业务、研究等),不存任何子目录的具体内容
- CLI 调用模式段落:只记录命令格式模板(如
python3.12 工具/app/xiangyu-{大类}-{名称}-cli/{同名}.py <命令>),明确标注"具体命令现场读对应工具 CLAUDE.md,不记忆" - 动态原则段落:声明其他工具持续更新知识库,本文件只存路径指针;所有事实以知识库文件当前内容为准,过时记忆不作为依据
- 全文不存储任何品牌名称、工作流列表、工具参数等会随时变化的事实性内容
MEMORY.md 没有存任何品牌名称、工作流列表、工具参数——只存路径。所有细节通过 read_file 在对话中现场获取。
USER.md 全文
翔宇:独立开发者,AI 编程教育 + 工具产品。
沟通:直接、技术流、不要客套、不要总结尾巴。
详细档案:~/Downloads/code/kb/品牌/翔宇工作流/身份/
三行。USER.md 只存最核心的画像和一个指针——详细档案在知识库里,不在 USER.md 里重复。
动态读取流程
静态层(系统提示词,每次都在)
├── SOUL.md → 身份 + 语言规则 + "知识库是参考源,路径在这"
├── MEMORY.md → 知识库根路径 + 导航方法(先读 CLAUDE.md → 按触发词路由)
└── USER.md → 极简画像 + "详情读知识库品牌/身份目录"
动态层(对话中按需 read_file)
├── ~/Downloads/code/kb/CLAUDE.md → 总路由表
├── ~/Downloads/code/kb/品牌/*/身份/*.md → 品牌详情
├── ~/Downloads/code/kb/规范/*/ → 写作规范
├── ~/Downloads/code/kb/工具/CLAUDE.md → 工具索引
└── ... 知识库里的一切
12 频道品牌分区
Discord 服务器按品牌拆分为四个分区、12 个频道:
| 分区 | 频道 | 品牌 |
|---|---|---|
| 行政区 | #总部 · #私人助理 · #运维部 | 共用,品牌无关 |
| 翔宇运营区 | #翔宇-公众号 · #翔宇-油管 · #翔宇-官网 · #翔宇-推特 · #翔宇-课程 | 翔宇工作流 |
| SYL 运营区 | #SYL-推特 · #SYL-官网 | SYL/希薇 |
| 共用区 | #研发部 · #情报部 | 跨品牌 |
每个频道的 channel_prompts 不写死内容,而是指向知识库目录入口。Hermes 收到消息后按频道职责域提取触发词,到工作流路由表匹配对应工作流。
这种设计在官方文档和社区案例中没有对标——大多数用户让 Hermes 根据对话内容判断品牌,而我通过频道分区让品牌判断变成自动化的确定性路由。
辅助模型独立配置——防压缩风暴
社区踩坑最多的问题之一:辅助压缩任务默认跟主模型走,主模型一旦限流(比如 GLM 429 错误),压缩也挂,Agent 丢失整个对话上下文。
方案:auxiliary.vision 和 auxiliary.compression 显式配置独立 Provider。视觉用 Gemini Flash(免费额度大),压缩跟主模型但独立配置。切模型时只改一处。
SOUL.md 调优四步法
官方推荐的迭代方法比试图一次设计完美人格更有效:
第一步:从默认开始
首次安装 Hermes 时,如果 SOUL.md 不存在,Hermes 会自动创建一个启动版本。从这个默认文件开始,不要从空白写起。
第二步:修剪不像你要的声音
读一遍默认 SOUL.md,删掉不符合你期望的部分。如果你不想要温和的语气,删掉 "be empathetic" 之类的描述。
第三步:添加 4-8 行核心定义
明确定义你的语气和默认行为。社区的四条铁律:
- 对语气要具体——"Direct and no apologies" 比 "friendly" 更有效
- 说你不想要什么——"Don't use bullet points" 比正面指令更有效
- 提及你的专业水平——说你是高级工程师,Hermes 就不解释基础
- 保持简短——瞄准 30 秒能读完的长度
第四步:对话迭代
跟 Hermes 对话一段时间,观察哪里还不对。如果 Agent 总是解释太多,加一行 "Keep explanations compact unless depth is useful"。如果 Agent 太客气,加一行 "No apologies, no hedging"。
判断强弱 SOUL.md 的标准:
| 维度 | 强 SOUL.md | 弱 SOUL.md |
|---|---|---|
| 稳定性 | 跨项目、跨场景一致 | 充满项目细节,换项目就不适用 |
| 具体性 | "Direct and no apologies" | "Be helpful and clear"(泛泛之词) |
| 独特性 | 真正的人格和风格 | 重述默认行为 |
| 简洁性 | 30 秒能读完 | 太长,占用上下文空间 |
关键认知:Hermes 已经在尝试做到有帮助和清晰。SOUL.md 的价值不是重述这些默认值,而是添加真正改变行为的个性。
排障清单
- 编辑后声音没变——确认编辑的是
~/.hermes/SOUL.md,不是某个仓库本地的 SOUL.md;确认重启了会话(冻结快照模式下,中途改 SOUL.md 不会生效) - Hermes 忽略部分内容——更高优先级指令覆盖了;文件包含冲突指引;文件太长被截断;某些文本触发了安全扫描器
- 变得太项目相关——将项目指令移到 AGENTS.md
常见问题
SOUL.md 和 AGENTS.md 有什么区别?
SOUL.md 是跨项目的持久人格(语气、风格、不确定性处理),AGENTS.md 是项目级上下文(代码规范、路径、架构)。判断规则:跟你到处走的放 SOUL.md,属于某个项目的放 AGENTS.md。
MEMORY.md 和 USER.md 各存什么内容?
MEMORY.md 存环境事实和项目约定(上限 2,200 字符),USER.md 存用户画像和沟通偏好(上限 1,375 字符)。两者在会话启动时作为冻结快照注入系统提示词。
Hermes 的记忆为什么采用冻结快照模式?
冻结快照让系统提示词在会话内保持不变,使 Anthropic 的 cache_control 断点可将输入 Token 成本降低约 75%。实时更新记忆会频繁打破缓存,节省荡然无存。
SOUL.md 应该写多长?
瞄准 30 秒能读完、4-8 行核心定义。截断上限 20,000 字符,但过长会浪费上下文空间。每一行都应改变 Agent 的默认行为,而非重述已有的"有帮助""清晰"等默认表现。
记忆条目满了怎么办?
工具返回错误并显示当前条目和使用量,合并冗余或移除过时条目后重试即可。建议在容量超过 80% 时主动精简。
9 种外部记忆提供商该选哪个?
本地零依赖选 Holographic,跨会话用户建模选 Honcho,自动提取选 Mem0,知识图谱选 Hindsight。同一时间只能激活一个外部提供商,内置记忆始终并行运行。
记忆写入有安全风险吗?
有。记忆条目注入系统提示词,是隐蔽的提示词注入向量。Hermes 自动扫描注入模式、凭据泄露、SSH 后门和不可见 Unicode 字符,也可开启 write_approval: true 做人工审批。
什么是指针架构?为什么用这种方式?
三个配置文件只存路径指针和导航方法,不存事实性内容,所有事实通过 read_file 按需动态读取。好处是知识库被其他工具更新后 Hermes 自动感知,零维护成本。
系列导航:本文是 Hermes Agent 完全指南 的深度子篇。相关阅读——Skill 自我进化系统详解(记忆系统如何与技能系统协作)、成本控制与模型选型(冻结快照模式的成本收益量化分析)。如果你正在构建自己的知识库,推荐阅读 AI 知识库构建指南——指针架构的前提是有一个结构化的知识库供 Agent 导航。
下一步
- AI 编程实操课:Claude Code + Codex + Agent 工作流,覆盖一人公司、自媒体自动化、AI 副业全场景。237 篇实战教程 + 最佳实践 + 源码包,跟着做就出成果。国内版-FlowUS | 国际版-BMC
- YouTube 频道:翔宇工作流
- 微信公众号:搜索「翔宇工作流」