同样用可灵 3.0,有人出电影级画面,有人得到模糊抖动的废片。差距不在模型,在提示词。可灵是快手团队开发的自研视频生成大模型,3.0 版本支持原生多镜头叙事(最多 6 个镜头一次生成)、原生音频对话、六轴摄像机控制和负面提示词,在 AI 视频生成领域处于第一梯队。但如果提示词写得模糊,再强的模型也救不回来。本文提供一个八层统一框架、10 个经过验证的模板和两个元提示词(让 AI 帮你写提示词),从写第一条提示词开始就走正确的路。
要点速览
- 可灵 3.0 支持原生多镜头叙事(最多 6 个镜头)、原生音频对话(中英日韩西 + 方言)、六轴摄像机控制和负面提示词
- 一个八层统一框架覆盖所有场景:单镜头只写「镜头 1」,多镜头扩展到 2-6 个,结构完全一致
- 提示词的核心不是写得长,而是写得准——单镜头最佳区间 40 到 100 字,多镜头 80 到 200 字
- 元提示词可以让 Claude 或 GPT 自动帮你生成符合八层框架的可灵提示词
可灵 AI 是什么:从快手团队到全球 4K 视频生成
可灵(Kling AI)是快手大模型团队开发的自研视频生成大模型,通过文字描述或图片参考生成高质量视频。从 2024 年 6 月的 1.0 版本到 2026 年 2 月的 3.0 版本,可灵在不到两年时间里经历了 1.0 → 1.5 → 1.6 → 2.0 → 2.1 → 2.5 Turbo → 2.6 → 3.0 八个主要版本迭代,完成了从「能生成视频」到「生产级视频工具」的跨越。
核心能力一览
| 维度 | 参数 |
|---|---|
| 输入类型 | 文本 + 图片参考(元素参考 2-4 张)+ 首尾帧控制 |
| 输出规格 | 3-15 秒/片段,支持 16:9、9:16、4:3、3:4、1:1 五种宽高比,原生 4K |
| 生成模式 | 文本转视频(T2V)、图片转视频(I2V)、首尾帧视频(O1)、多镜头叙事 |
| 原生能力 | 多镜头叙事(最多 6 镜头)、原生音频对话、多语言/方言、六轴摄像机控制、负面提示词 |
当前可灵的模型矩阵包括三个核心版本:VIDEO 3.0(通用文生视频和图生视频,擅长高真实感运动和复杂物理模拟)、VIDEO 3.0 Omni(增强元素参考能力,锚定角色和物品一致性)、VIDEO O1(首尾帧视频生成专精模型)。
访问方式有三种:一是通过可灵 AI 官方平台(kling.ai),支持网页端和移动端;二是通过可灵官方 API;三是通过 fal.ai 等已集成的第三方平台。
💡 通俗讲:如果把 AI 视频生成比作拍电影,可灵就是一个自带摄影团队、录音棚和剪辑室的 AI 导演。你给它的「剧本」就是提示词,它不仅能拍出画面,还能自动配音、切镜头、控制摄像机运动。
提示词为什么重要:同样的模型,输出天差地别

用可灵生成视频消耗平台积分。但同样花这笔积分,有人生成出电影级画面,有人得到的是模糊、抖动、角色变形的废片。差距就在提示词。
提示词长度的最佳区间
| 类型 | 推荐字数 | 说明 |
|---|---|---|
| 单镜头 | 40-100 字 | 太短缺细节,太长指令冲突 |
| 多镜头序列 | 80-200 字 | 每个镜头段是独立的迷你提示词 |
| 最佳平衡点 | 40-100 字 | 大多数单镜头的最优区间 |
可灵 3.0 的提示词上限为 2500 个字符。社区测试反复验证了一个结论:提示词越长,后半段的遵循度越低。模型从左到右阅读提示词,写在前面的内容权重最高。
可灵八层统一框架:一个结构覆盖所有场景
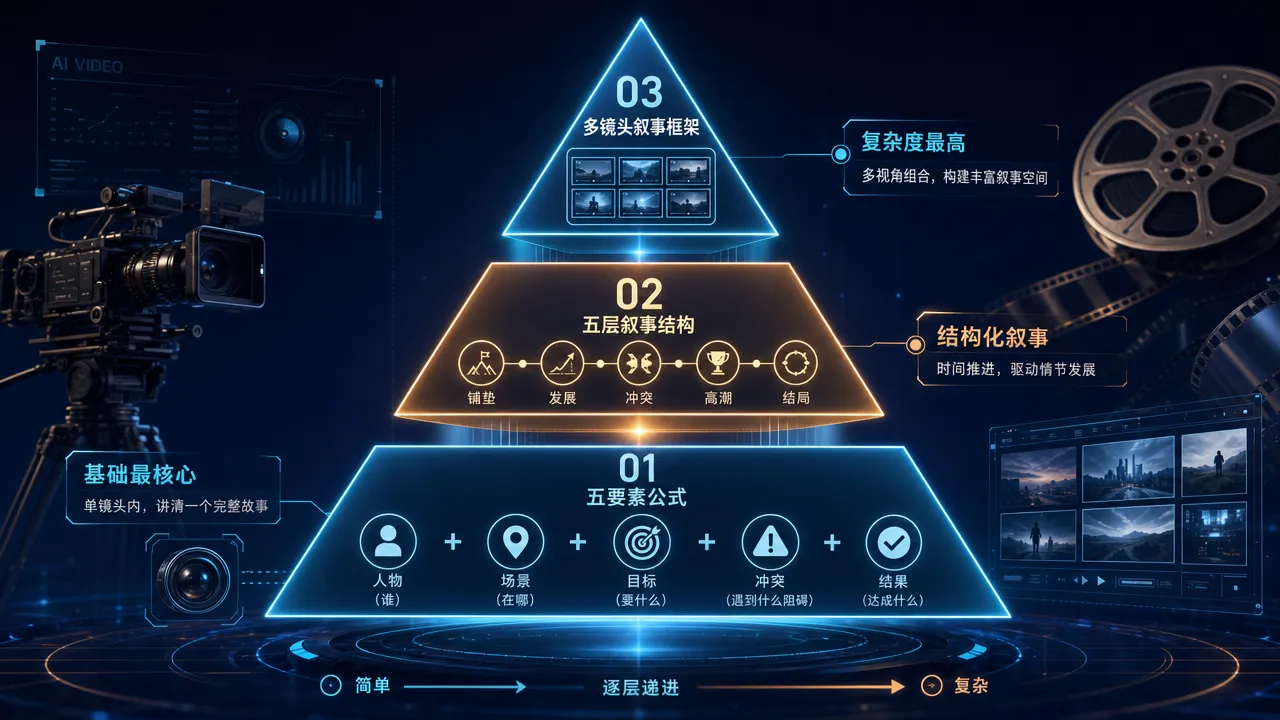
中文世界的可灵教程要么只讲五要素公式,要么只讲多镜头叙事,学了一个到另一个场景又要重学。本文把可灵官方的五要素公式、社区验证的五层叙事结构和 3.0 原生多镜头叙事三种方法论合并为一个八层统一框架。单镜头和多镜头的区别只在镜头数量——结构完全一致,学一次终身复用。
八层结构总览
| 层级 | 名称 | 核心作用 | 单镜头 | 多镜头 |
|---|---|---|---|---|
| 1 | 元素参考声明 | 锁定角色/物品/场景参考素材 | 有素材时写 | 有素材时写 |
| 2 | 镜头标签 | 「镜头 1」「镜头 2」分段 | 只写镜头 1 | 2-6 个镜头 |
| 3 | 景别与主体 | 景别 + 主体 2-3 个静态特征 | 每镜头写 | 每镜头写 |
| 4 | 动作 | 身体部位级动作 + 幅度 + 速度 | 每镜头写 | 每镜头写 |
| 5 | 运镜 | 一个运镜动作,中文(English)格式 | 每镜头写 | 每镜头写 |
| 6 | 场景与光影 | 环境 + 光源方向/色温 + 氛围元素 | 每镜头写 | 每镜头写 |
| 7 | 音频 | 对话/音效/环境音 | 每镜头写 | 每镜头写 |
| 8 | 全局收尾 | 风格锚点 + 负面提示词 + 质量后缀 | 写一次 | 写一次 |
💡 通俗讲:把这八层想象成一张拍摄表。第一层是给剧组分工(哪个素材演什么角色),第二到七层是每个镜头的拍摄指令(拍谁、做什么、怎么拍、什么光、什么声音),第八层是整部片子的风格定调和技术规格。单镜头就是只有一行的拍摄表,多镜头就是多行。
历史框架对照表
本文的八层框架整合了此前社区常用的三种方法论。如果你此前学过其中某一种,以下对照表帮助你理解新框架的对应关系:
| 场景 | 历史框架 | 八层框架的使用方式 |
|---|---|---|
| 快速迭代、单镜头、纯文本生成 | 五要素公式(40-100 字) | 八层框架,省略第一层,只写镜头 1 |
| 叙事演进、时间流、有音效需求 | 五层叙事结构(60-150 字) | 八层框架,镜头 1 内增加时间描述 |
| 多角度覆盖、对话场景、电影级分镜 | 多镜头叙事框架(80-200 字) | 八层框架,写 2-6 个镜头 |
八层统一框架详解:逐层拆解写法要点

以下逐层拆解每一层的写法要点。可灵从左到右阅读提示词,越靠前的内容权重越高,所以八层的排列顺序本身就是优先级。
第一层:元素参考声明
通过上传 2 到 4 张不同角度的参考图片或录制角色视频,可灵可以锚定场景中的特定元素。核心规则是始终明确指定每个参考素材的角色——不要只上传文件,要在提示词中说明它锁定的是什么。
- 角色锁定:「参考图中穿红裙的女性作为主角」
- 场景锁定:「参考图中的天台城市景观作为背景」
- 物品锁定:「参考图中的复古相机作为道具」
无素材时省略此层,直接从镜头标签开始。角色类元素还可以绑定音色——上传角色参考图后指定该角色的声音特征。
第二层:镜头标签
用「镜头 1」「镜头 2」「镜头 3」分段,不用时间码。可灵 3.0 支持最多 6 个镜头的连贯视频一次性生成。
- 单镜头只写「镜头 1:」
- 多镜头写 2 到 6 个,每个镜头是一个独立的迷你提示词
可灵的「以镜头思考」(Think in Shots)范式:每个镜头切换视角和距离——后方跟踪、侧面特写、第一人称主观、正面跟拍、高角度全景。镜头之间的视角变化越丰富,叙事越有层次。
第三层:景别与主体
先声明景别(全景、中景、中近景、特写、极致特写),再用 2 到 3 个具体、稳定的静态特征描述主角。
高效写法:「中近景,穿红色连衣裙、扎松散低马尾的年轻女性」
低效写法:「一个漂亮的女孩」
永远不要用 beautiful、nice、amazing 这类模糊形容词。用具体名词和材质——「磨砂黑色金属外壳」比「好看的耳机」对模型有用十倍。
第四层:动作
描述要具体到身体部位,同时补充幅度和速度。「缓缓抬起右手,手指逐根张开」比「她举起手」传达的信息多三倍。
情绪外化是这一层的核心技巧。不要写抽象情绪词,要通过身体细节表达:
| 抽象情绪 | 外化为动作和细节 |
|---|---|
| 悲伤 | 低下头,肩膀微微发抖,眼眶泛红,手指不自觉攥紧衣角 |
| 喜悦 | 嘴角不自觉上扬,眉眼舒展,脚步变得轻快,忍不住原地转圈 |
| 紧张 | 频繁看手表,手指不停敲桌面,呼吸急促,目光闪躲 |
| 愤怒 | 双拳紧握,下颚线绷紧,胸膛剧烈起伏,牙关紧咬挤出话来 |
| 释然 | 长长呼出一口气,绷紧的双肩彻底放松,久违的淡淡微笑浮现 |
优先选择慢速、轻柔、连续的小动作,避免冲刺、跳跃、剧烈翻滚等高爆发动作——模型处理这类动作容易出现肢体变形。
第五层:运镜
每个镜头只写一个运镜动作,这是最重要的规则。多个同时运动会导致抖动和混乱输出。格式统一为中文描述加英文术语括注,如「缓慢推进(dolly in)」。
运镜和主体动作必须分开描述。错误写法是「镜头环绕旋转,跳舞的女人」,正确写法是先写「一个女人缓慢舞蹈,双臂抬起」,再单独写「镜头以稳定的弧线环绕她(orbit)」。
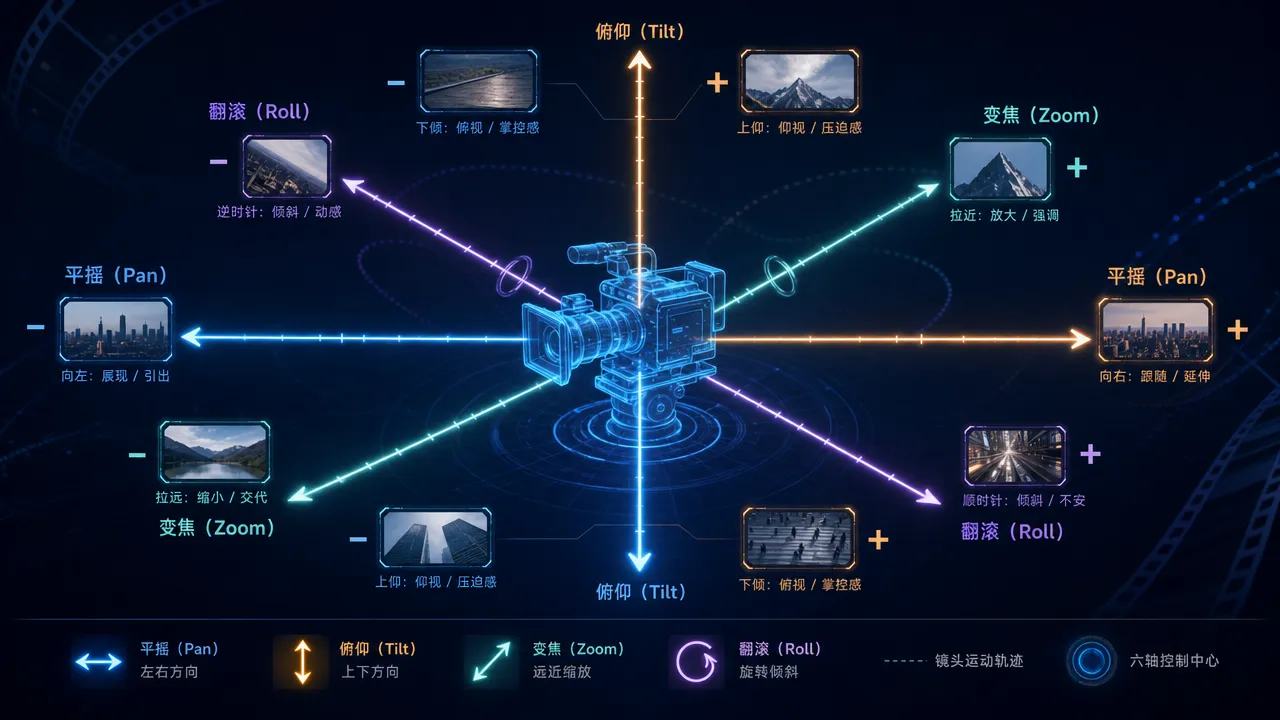
可灵的六轴摄像机控制系统(API 场景可精确设定 -10 到 10 的数值):
| 摄像机轴 | 正值效果 | 负值效果 |
|---|---|---|
| 水平(Horizontal) | 向右移动 | 向左移动 |
| 垂直(Vertical) | 向上移动 | 向下移动 |
| 平摇(Pan) | 向右旋转 | 向左旋转 |
| 俯仰(Tilt) | 向上倾斜 | 向下倾斜 |
| 翻滚(Roll) | 顺时针旋转 | 逆时针旋转 |
| 变焦(Zoom) | 更宽视野 | 更窄视野 |
第六层:场景与光影
包含三个子维度:环境描述、光源方向和色温、氛围元素(雾、尘埃、雨)。其中光影描述的每词质量提升超过任何其他元素。
低效写法:美丽的电影光线
高效写法:主光从左上方打来,暖色补光,黄金时段逆光捕捉空气中的灰尘颗粒
命名真实光源是关键——不要只说「戏剧性灯光」,要说霓虹灯、烛光、黄金时段、LED 面板、闪烁的荧光灯管。可灵能理解的光影文化参考包括:伦勃朗光(Rembrandt lighting)、苹果主题演讲光(Apple keynote lighting)、纪录片光(documentary lighting)、MV 频闪灯(strobe lighting)。
第七层:音频
可灵从 2.6 版本开始成为首个原生音频视频生成模型。每个镜头独立描述音频信息,用「音效:」前缀标注。音频维度包括对话、音效和环境音三类。
示例:「音效:一声心跳,然后寂静」「音效:风吹过麦秆的沙沙声,远处隐约的管弦乐渐强」
多角色对话语法(3.0 特有):
[角色 P1: 角色名, 语气描述]: "台词内容"
动作节拍描述
[角色 P2: 角色名, 语气描述]: "台词内容"
每个角色需要唯一标签(P1-P4)、独特音色描述和明确的情绪标签。3.0 支持中英日韩西五种语言和方言(东北话、粤语、四川话等)。
第八层:全局收尾
这一层在所有镜头之后,只写一次,包含三个部分:
风格锚点:文化参考(银翼杀手 2049 美学、中国水墨画美学)+ 镜头规格(35mm、85mm)+ 胶片类型(柯达暖色调、ARRI ALEXA 色彩科学)。
负面提示词:可灵支持独立的负面提示词输入框(即梦不支持)。推荐基础负面提示词——变形扭曲(warping),形态渐变(morphing),面部扭曲(distorted faces),多余手指(extra fingers),模糊纹理(blurry textures),抖动运动(jittery motion),伪影(artifacts)。同时在正向提示词末尾加约束——保持面部一致,无拉伸,不生成字幕,不生成水印。
质量后缀:分辨率 + 宽高比 + 时长,如「4K,16:9,12 秒」。
🔍 深入一步:为什么八层的顺序不能换?因为可灵和大多数扩散模型一样,对提示词的注意力从左到右递减。元素参考放最前面让模型先锁定输入源,景别和主体紧跟其后给模型一个视觉锚点,动作第三提供动态核心。社区测试发现,把运镜放到主体前面会导致主体渲染质量下降。
核心提示词技巧:运镜、光影、动作与负面提示词
掌握了框架之后,这四个技巧决定了提示词的上限。
运镜词汇表
可灵对电影摄影术语有很强的理解能力,可以直接使用标准术语:
| 英文术语 | 中文说明 | 效果评级 |
|---|---|---|
| dolly in/out | 推进/拉出 | 优秀 |
| pan left/right | 左摇/右摇 | 优秀 |
| tracking shot | 跟拍 | 优秀 |
| orbit | 环绕 | 优秀 |
| handheld | 手持 | 优秀 |
| fixed/locked | 固定/锁定 | 优秀 |
| crane up/down | 升降 | 优秀 |
| push in | 推入 | 优秀 |
| whip-pan | 甩镜 | 良好 |
| rack focus | 焦点转移 | 良好 |
关键规则:运镜和主体动作必须分开描述。错误写法是「镜头环绕旋转,跳舞的女人」,正确写法是「一个女人缓慢舞蹈,双臂抬起。镜头以稳定的弧线环绕她。」
光影描述:投资回报率最高的元素
添加具体光影描述产生的每词质量提升超过任何其他提示词元素。
低效写法:美丽的电影光线
高效写法:主光从镜头左上方打来带暖色补光反射,黄金时段逆光捕捉空气中的灰尘颗粒
可灵能理解的光影文化参考包括:伦勃朗光(Rembrandt lighting)、苹果主题演讲光(Apple keynote lighting)、纪录片光(documentary lighting)、MV 频闪灯(strobe lighting)。在提示词中可以直接写中文,如「伦勃朗光,主光从左上方 45 度打来」,可灵能准确理解。
动作描述的三个原则
一是身体部位细化加程度量化——「缓缓抬起手」「快速转头」「微微低头」,具体到手、腿、头、肩。
二是优先慢速连续的小动作——可灵处理高速大幅度动作容易出问题,优先慢速、轻柔、连续的小动作。
三是补充动作间的过渡——「借转身的惯性自然抬手」「从静止自然过渡到抬手」,指定前后动作之间的连续性。
⚠️ 常见踩坑:永远不要在可灵提示词中使用「快速」或「fast」这类词。它几乎必然导致运动模糊、时间不一致和视觉噪声。如果需要快速节奏,通过动作和物理细节来描述速度——不是「快速飞车追逐」而是「一辆黑色轿车猛冲过狭窄街道,轮胎在湿沥青上发出尖啸,悬挂系统在急弯中压缩」。
负面提示词模板
可灵支持独立的负面提示词输入框,这是它相对于即梦的一个重要优势。推荐始终添加的基础负面提示词:
- 变形扭曲(warping)
- 形态渐变(morphing)
- 面部扭曲(distorted faces)
- 多余手指(extra fingers)
- 模糊纹理(blurry textures)
- 抖动运动(jittery motion)
- 伪影(artifacts)
同时在正向提示词末尾加入约束词——保持面部一致,无拉伸,避免身份漂移,不生成字幕,不生成水印,不生成 Logo。
注意不要写太多负面提示词,否则画面可能变得僵硬。5 到 8 个常见瑕疵词是最佳数量。
多模态引用与对话系统:可灵的差异化能力
元素参考系统
通过上传 2 到 4 张不同角度的参考图片或录制角色视频,可灵可以锚定场景中的特定元素。无论镜头如何运动、场景如何发展,角色的外貌、服装、物品特征都保持一致。
参考类型与最佳用途
| 参考类型 | 最佳用途 |
|---|---|
| 角色参考图(多角度) | 身份锚定(面部特写、全身照)、外貌一致性 |
| 场景参考图 | 环境设计、空间布局 |
| 物品参考图 | 产品外观、道具特征 |
| 首尾帧(O1 模型) | 精确控制场景起止 |
角色类元素还可以绑定音色,实现角色外观和声音的一致性。
多角色对话语法
3.0 的对话格式使用结构化命名规则(P1-P4):
[角色 P1: 角色名, 语气描述]: "台词内容"
动作节拍描述
[角色 P2: 角色名, 语气描述]: "台词内容"
多角色对话的四个原则
| 原则 | 指南 | 示例 |
|---|---|---|
| 结构化命名 | 角色标签唯一且全程一致(P1-P4) | [角色 P1: 侦探,沙哑低沉的男中音] |
| 视觉锚定 | 先描述动作再说对话 | 侦探猛拍桌面。[角色 P1: 侦探,愤怒地]: "真相到底是什么?" |
| 音频细节 | 每个角色独特音色和情绪标签 | [角色 P1,沙哑低沉] 对比 [角色 P2,清亮恐惧] |
| 时间控制 | 用连接词和动作节拍衔接 | 角色 P2 缓慢摘下眼镜,放在桌上。[角色 P2]: "因为......" |
⚠️ 常见踩坑:多角色对话场景中,如果角色标签不一致(第一次写 P1,第二次写「他」),模型会把两个标签当成两个角色,导致音色错乱和画面人物混淆。务必全程使用同一个角色标签。
方言和口音
3.0 支持在提示词中直接指定方言:「用粤语说」「带东北口音」。中文方言覆盖东北话、北京话、台湾腔、粤语、四川话等。英文口音支持美式、英式、印度式等。同一场景内还可以多语言混合切换。
10 个精选提示词模板:覆盖最常见的视频创作场景

以下 10 个模板覆盖了可灵用户最高频的 10 个应用场景——从产品广告、美食餐饮到短剧微电影、音乐视频,每个场景都是真实使用需求。每个模板都是 3 镜头多镜头叙事,严格遵循八层统一框架,可以直接复制粘贴到可灵使用,也可以替换其中的主体和场景细节适配你自己的需求。每个模板末尾单独标注负面提示词——这是可灵相对于其他视频模型的独有能力。
模板 1:产品广告
应用场景:电商产品展示、品牌广告、开箱视频 | 目标用户:电商卖家、品牌方 | 关键技巧:六轴摄像机的环绕轴(orbit)精确控制产品展示角度,苹果主题演讲光保持高级感,15 秒长镜头完整展示从包装到开箱到 360 度细节的三段式叙事
镜头 1:特写,一只哑光白色方形包装盒放在浅灰色桌面上,盒盖中央一个银色 Logo 压印清晰可见,包装边缘倒角线条利落。一束光从正上方缓缓亮起,照亮 Logo 的细微纹理和压印深度。缓慢推进(push in),从包装盒全貌收紧到 Logo 特写。苹果主题演讲光——正上方干净主光带柔和衰减,四周无阴影的均匀补光,纯色背景微妙渐变。音效:安静环境中柔和的灯光通电嗡鸣,空间感十足的寂静。
镜头 2:中近景,俯拍角度。一双手指甲修剪整齐的手从画面两侧伸入,拇指和食指捏住盒盖边缘。盒盖以缓慢匀速被提起,内侧磁吸结构分离时发出轻微的咔声。盒盖完全提起后,深灰色绒布上嵌着一副哑光黑色无线耳机,耳罩纹理和拉丝金属铰链被柔和光线勾勒。双手将盒盖轻轻放在桌面一侧。固定机位(fixed),正上方俯拍。主光从正上方打下,耳机表面形成均匀的高光带。音效:磁吸分离的轻微咔声,盒盖触碰桌面的轻柔声,绒布与手指的细微摩擦声。
镜头 3:中景,平视角度。双手从绒布中取出耳机放在桌面中央。耳机在隐形转盘上缓慢旋转一整圈,从正面到侧面到背面,展示耳罩弧度、头梁弹性和铰链结构。缓慢环绕(orbit),与转盘旋转方向相反形成双重环绕效果。右上方干净主光,左侧柔和散射补光,白色无缝背景带微妙渐变。音效:极轻的机械转盘低频嗡鸣,耳机表面反射光线时的微妙高频音效。
照片级产品摄影,85mm 镜头压缩,背景浅景深,苹果主题演讲美学。保持产品形状一致,无拉伸,无闪烁,不生成字幕,不生成 Logo。4K,16:9,15 秒。
负面提示词:变形扭曲(warping),形态渐变(morphing),模糊纹理(blurry textures),伪影(artifacts)
模板 2:美食餐饮
应用场景:制作过程展示、成品摆盘、餐厅氛围营造 | 目标用户:餐饮店主、美食博主 | 关键技巧:9:16 竖屏适配短视频平台,三个镜头色调从冷(备菜)到暖(烹饪)到金色(成品)递进,原生音频同步生成食材处理声和烹饪声引发食欲
镜头 1:特写,木质砧板上排列着新鲜食材——一块厚切三文鱼排,表面油脂纹路清晰,旁边散落几片紫苏叶和细长的葱丝。一只手持刀从三文鱼右侧开始,以匀速切出薄片——刀刃缓慢滑过鱼肉,每一片在刀身两侧轻轻倒下,内部橙红色肉质和白色脂肪层清晰分明。固定机位(fixed),正上方俯拍。自然窗光从左侧打入,砧板上形成柔和侧光,鱼肉表面的油脂反射出微微光泽。音效:刀刃切过鱼肉的绵密声,薄片倒在砧板上的轻拍声,远处水龙头的滴水声。
镜头 2:中近景,一口黑色铸铁锅放在灶台上,锅面冒着热气。一只手将一勺黄油放入锅中——黄油落入的瞬间发出滋滋声,以慢动作展现黄油边缘冒出的细密气泡和金色融化过程。另一只手用长柄夹将三文鱼排轻放入锅中,鱼皮接触热油的瞬间卷曲收紧,油花四溅。缓慢推进(push in),从锅全景收紧到鱼排在油中煎制的细节。灶台上方暖色吊灯打下,蒸汽在光束中呈半透明金色。音效:黄油融化的滋滋声,鱼排入锅的爆裂声,锅铲轻轻按压鱼皮的吱吱声。
镜头 3:中景,成品摆盘。一只深灰色陶瓷盘放在原木桌面上,煎好的三文鱼排摆在盘中央,鱼皮金黄酥脆微微翘起,肉质断面粉嫩。旁边点缀几滴酱油和一小撮芝麻,盘边用筷子摆出一朵紫苏叶造型。一只手从画面上方将一小壶热油缓缓浇在鱼排上,油线以慢动作呈细丝状落下,接触鱼皮时发出最后一声滋滋声。缓慢后拉(dolly out),从盘中特写退至桌面全景,揭示周围的筷架和一杯清酒。左侧自然窗光带暖色调,盘子边缘投下柔和短影。音效:热油浇淋的滋滋声,瓷盘在木桌上被微微推正的声响,远处餐厅的轻柔环境音。
美食摄影风格,85mm 微距镜头,极浅景深带柔和圆形散景,高端美食杂志美学。保持食材色彩真实,无闪烁,不生成文字,不生成 Logo。4K,9:16,15 秒。
负面提示词:变形扭曲(warping),模糊纹理(blurry textures),伪影(artifacts),抖动运动(jittery motion)
模板 3:短剧微电影
应用场景:情感故事、反转剧情、人物冲突 | 目标用户:短视频创作者 | 关键技巧:P1-P4 对话语法驱动角色互动,三个镜头从压抑到释放到反转的叙事弧线,六轴摄像机的俯仰轴(tilt)在关键时刻抬头揭示反转
镜头 1:特写,一双粗糙的手放在灰色办公桌上,指甲边缘有倒刺,无名指有旧茧印。
[角色 P1: 主管,冰冷公事公办的女声]: "从明天起你不用来了。"
手指微微蜷缩,指节发白,但没有握拳。一张折叠的公文被推到手前——展开后可见红色印章。双手缓缓将通知书折回原来的折痕,动作异常平静而精确。固定机位(fixed),俯拍桌面。冷白色日光灯从正上方打下,桌面反光惨白,通知书的红色印章是画面中唯一的暖色。音效:纸张折叠的细微声响,日光灯管的电流嗡鸣,远处办公室键盘敲击的模糊声。
镜头 2:中景,六个月后。同一个人穿着剪裁合身的深灰色三件套西装,白色衬衫袖口露出银色袖扣,头发整齐地向后梳理。他走在一栋玻璃幕墙办公楼的大堂里,步伐不快不慢,皮鞋在大理石地面上发出有节奏的声响。左手插在裤袋里,右手提着一只深棕色公文包,拇指轻轻摩挲着把手。跟拍(tracking shot),从侧前方跟随,保持人物在画面三分之一处。大堂落地窗透入的自然光与头顶射灯形成柔和的交叉照明,大理石地面倒映他的轮廓。音效:皮鞋踩大理石的清脆回响,大堂自动门开合的气压声,远处电梯叮的一声。
镜头 3:中近景,一间宽敞的顶层办公室,落地窗外是城市天际线。他走到一把黑色真皮高背办公椅后方,右手搭在椅背上,手指沿着皮革缝线缓缓滑下。他转动椅子面向自己,然后坐下——身体重心缓慢后靠,双手搭在扶手上,十指交叉。他微微抬起下巴,目光扫过桌上的铭牌——「CEO」字样被窗外阳光照亮。嘴角几乎察觉不到地上扬了一毫米。
[角色 P2: 他自己,低沉平静的独白]: "谢谢你当初那句话。"
缓慢推进(push in),从中近景收紧到面部和铭牌。午后金色侧光从落地窗打入,在他的面部形成伦勃朗光三角,桌面文件投下长长的阴影。音效:真皮椅受压的轻微声响,窗外城市远景的低频环绕声。
电影叙事风格,35mm 柯达暖色调,浅景深散景,写实主义调色。保持主角面部和身材比例一致,避免身份漂移,不生成字幕,不生成水印。4K,16:9,15 秒。
负面提示词:面部扭曲(distorted faces),身份漂移(identity drift),变形扭曲(warping),多余手指(extra fingers),伪影(artifacts)
模板 4:音乐视频
应用场景:节拍卡点、舞蹈表演、歌词可视化 | 目标用户:音乐人、舞蹈博主 | 关键技巧:可灵原生音频能力同步生成画面与音乐,三个镜头的动作幅度与节拍强度同步递进(准备、起舞、高潮),原生音效与画面一体化生成无需后期配乐
镜头 1:中景,一间空旷的舞蹈排练厅,四面落地镜反射出无限延伸的空间。一个穿黑色紧身上衣、宽松灰色运动裤、赤脚的舞者站在排练厅中央,背对镜头。她的双手垂在身体两侧,手指微微张开,脊柱随着隐约的低频节拍微微起伏——从尾椎开始,波浪式传导至颈椎。她缓缓转头,露出侧脸的下颌线。固定机位(fixed),平视角度。头顶工业吊灯投下单一硬光,舞者的影子在木地板上拉出长长的轮廓。音效:低沉的电子合成器前奏低频缓缓渐入,赤脚在木地板上微微摩擦的声响,排练厅空间混响。
镜头 2:中近景,舞者正面。节拍进入主旋律段落。舞者的右臂以流畅的弧线从身侧甩至头顶——手腕在最高点翻转,手指依次展开。左脚同时向左侧滑出一大步,身体重心随之转移。她的躯干在节拍重音处做一次锐利的顿停,肩膀和臀部反方向扭转。头发因动作惯性甩向一侧。跟拍(tracking shot),从正面微微左右跟随她的重心移动。两侧排练镜反射出她的多个角度。头顶灯光在她顿停的瞬间形成锐利的明暗切换。音效:主旋律段落节奏加强,合成器旋律与赤脚踏地板的节奏精确同步,衣料随动作发出的呼呼声。
镜头 3:全景,舞者在排练厅中央全力释放。音乐进入高潮段落。她连续做三个旋转——每次旋转时双臂从收紧到展开,运动裤裤脚在旋转气流中飞起。旋转结束后她猛然停住,单膝跪地,双臂向两侧完全展开,头向后仰,胸腔大幅起伏。汗珠从额头和手臂上甩出,在灯光中如碎钻闪烁。升降上升(crane up),从平视缓慢升至俯拍,揭示她跪在地板中央的完整画面和四面镜中的无数个她。所有灯光同时亮起,从单一硬光变成全场均匀高亮。音效:高潮段落全力输出,鼓点与电子合成器叠加,最后一个重音与她跪地动作精确同步,然后音乐骤停,只剩急促的喘息声在排练厅中回荡。
现代舞纪录片风格,35mm 广角镜头,自然主义调色,手持质感。保持舞者面部和服装一致,肢体不弯曲,避免抖动,不生成字幕,不生成水印。4K,16:9,15 秒。
负面提示词:变形扭曲(warping),面部扭曲(distorted faces),多余手指(extra fingers),抖动运动(jittery motion),伪影(artifacts)
模板 5:品牌宣传片
应用场景:企业形象展示、团队介绍、价值观传达 | 目标用户:企业市场部 | 关键技巧:多镜头 Shot 标签自动规划镜头转场,三个镜头从空间全景到人物群像到产品特写构成品牌叙事弧线,原生 4K 输出保证商业级画质
镜头 1:全景,清晨阳光穿过一栋现代玻璃幕墙办公楼的大堂。大堂中央一面浅灰色水泥墙上嵌着公司 Logo——拉丝不锈钢材质,边缘反射着晨光。前台桌面上一盆小型绿植的叶片微微颤动。一个穿白色衬衫的前台人员站起身整理桌面文件,动作从容。缓慢推进(dolly in),从大堂入口推向 Logo 墙。晨光从右侧落地窗打入,在水泥墙上形成长条形光带,Logo 的金属表面捕捉到暖色反光。音效:大堂门禁刷卡的滴声,皮鞋踩大理石的远距离回响,空调系统的低频白噪声。
镜头 2:中景,开放式办公区域。三个人围坐在一张原木长桌旁——一个穿深蓝色 polo 衫的男人用手指在平板上划动,一个扎马尾穿灰色针织衫的女人微微侧头看向屏幕,嘴角不自觉上扬,第三个戴黑框眼镜的人右手托着下巴,食指轻轻点着嘴唇思考。平板屏幕上的数据图表被桌面反光模糊映出。跟拍(tracking shot),从桌子一端缓慢平移到另一端。头顶线性灯带投下均匀的暖白光,桌面原木纹理和每个人的肤色都呈现自然暖色调。音效:键盘轻敲声,有人小声说了一句「这个方向对」,咖啡杯放在桌面上的轻碰声。
镜头 3:中近景,一双手将一份装订好的方案书放在会议桌上,封面印着公司 Logo 和项目名称。手指轻轻翻开第一页,纸张边缘在指尖滑过。镜头焦点从方案书的文字缓慢转移到背景中——落地窗外城市天际线在午后阳光下清晰可见,几片云缓缓移动。固定机位(fixed),浅景深。午后侧光从落地窗打入,方案书封面的 Logo 被一道斜光照亮,纸页边缘泛金色。音效:纸页翻动的清脆声,远处窗外城市的低频环绕声,一段轻柔的品牌主旋律钢琴曲渐入。
企业品牌宣传风格,50mm 定焦镜头,ARRI ALEXA 色彩科学,暖色调自然主义调色。保持所有人物面部和服装一致,避免身份漂移,不生成字幕,不生成水印。4K,16:9,15 秒。
负面提示词:面部扭曲(distorted faces),身份漂移(identity drift),变形扭曲(warping),模糊纹理(blurry textures),伪影(artifacts)
模板 6:房地产展示
应用场景:楼盘漫游、室内设计展示、空间体验营造 | 目标用户:地产经纪、设计师 | 关键技巧:六轴摄像机的水平轴(horizontal)和俯仰轴(tilt)组合模拟看房者的第一视角走动路线,15 秒长镜头完整展示从外景到客厅到阳台视野的空间叙事
镜头 1:全景,一栋现代极简风格的独立别墅外立面,白色清水混凝土墙体搭配大面积落地玻璃窗。前院一棵日本红枫树叶片在微风中轻轻摆动,石板小径从画面底部延伸至入口大门。大门缓缓向内打开,露出门厅内部温暖的灯光。缓慢推进(dolly in),从街道视角推向逐渐打开的大门。午后黄金时段侧光从左侧打来,白色墙面被阳光染成淡金色,落地窗反射出对面树木的倒影。音效:微风拂过树叶的沙沙声,大门液压铰链的低沉开启声,门内暖气流出的微弱气流声。
镜头 2:中景,步入开放式客厅。挑高四米的天花板下,一组浅灰色布艺沙发环绕着一张黑色大理石茶几。右侧整面书墙从地面延伸至天花板,原木搁板上错落摆放着书籍和陶器。阳光透过两层高的落地窗在木地板上投下长方形光斑,光斑中漂浮着细小的灰尘颗粒。跟拍(tracking shot),模拟看房者的步行视角从门厅缓慢走入客厅中央,视线从左侧书墙扫到右侧落地窗。顶部天窗和侧面落地窗形成交叉自然采光,空间内无人工主灯,全靠日光勾勒空间层次。音效:脚步踩在橡木地板上的轻柔叩击声,远处厨房水龙头滴水的清脆声,窗外鸟鸣。
镜头 3:中近景,走到客厅尽头的阳台推拉门前。一只手从画面右侧伸出,手指搭在门把手上缓缓向右推开玻璃门。门滑开后,阳台外的城市天际线在午后阳光中展开——远处几栋高楼轮廓清晰,中景是一片绿化带的树冠,近处阳台栏杆上一盆多肉植物叶片饱满。微风吹入室内,白色纱帘被掀起一角。固定机位(fixed),站在室内向外拍摄,阳台门框形成画中画构图。室内偏暗的环境光与阳台外明亮的自然光形成戏剧性明暗对比,纱帘边缘被逆光勾出金色轮廓。音效:推拉门滑轨的顺滑声,风涌入室内的呼声,纱帘飘动的轻柔声,远处城市的低频环绕声。
建筑空间摄影风格,24mm 广角镜头保持空间纵深感,自然光主导,极简主义调色。保持空间比例真实,无拉伸,不生成文字,不生成水印。4K,16:9,15 秒。
负面提示词:变形扭曲(warping),模糊纹理(blurry textures),抖动运动(jittery motion),伪影(artifacts)
模板 7:教育知识
应用场景:知识讲解可视化、历史场景重现、科学原理演示 | 目标用户:教师、知识博主 | 关键技巧:原生多语言能力让讲解者用中文讲解配合历史场景原音,三个镜头从宏观场景到微观细节到讲解者回应构成「提出问题、展示答案、总结升华」的知识叙事结构
镜头 1:全景,一座完整的古罗马斗兽场矗立在蓝天下,外墙的三层拱券结构清晰可见,每个拱券内的多利克柱和爱奥尼柱细节精确。建筑表面保留着石灰华的米黄色原始材质,阳光在拱券的阴影中形成规律的明暗交替。画面底部的广场上几个穿白色托加长袍的人物缓慢走过,长袍下摆随步伐轻拂地面。固定机位(fixed),低角度仰拍,斗兽场占据画面上方三分之二。正午顶光从正上方打下,建筑顶部明亮,底层拱券内渐暗,立体感强烈。音效:风穿过石拱的回声,远处人群嘈杂的低语,鸽子振翅飞过的声响。
镜头 2:中近景,镜头穿过一个底层拱券进入斗兽场内部。椭圆形竞技场的沙地铺展在视野中央,周围层层看台从低到高向上排列。一束阳光从顶部缺口打入,在沙地上形成一个椭圆形光斑——光斑内沙尘颗粒缓缓浮动。一个穿青铜胸甲、手持短剑和盾牌的角斗士从阴影中缓步走入光斑,他抬起持剑的右臂向看台方向致意,盾牌表面的浮雕纹饰被阳光照亮。缓慢推进(push in),从竞技场全景收紧到角斗士的上半身。从顶部打入的单束自然光如同舞台追光,角斗士周围暗,身上亮,沙地上他的影子拉得很长。音效:沙地上沉重脚步的闷响,金属盾牌与胸甲碰撞的铿锵声,看台方向传来隐约的欢呼声。
镜头 3:中景,场景切换到现代。一个穿浅蓝色衬衫、戴细框眼镜的讲解者站在一面深色背景墙前,身后投影着斗兽场的结构剖面图。他的右手掌心朝上,手臂从胸前向右侧缓慢展开——手势与背后投影中的结构标注方向一致,像是在为观众「打开」建筑的内部。他微微点头,嘴唇动作与讲解节奏吻合,眉毛在强调要点时轻轻上扬。固定机位(fixed),平视角度,人物在画面左三分之一处,背后投影占右三分之二。左前方柔光箱打出均匀面光,背景投影亮度适中不过曝。音效:讲解者清晰的男声「这就是古罗马工程的核心——拱券承重体系」,背景中极轻的环境白噪声。
教育纪录片风格,50mm 定焦镜头,自然主义调色,画面干净稳定适配后期字幕。保持所有人物面部和服装一致,避免身份漂移,不生成字幕,不生成水印。4K,16:9,15 秒。
负面提示词:面部扭曲(distorted faces),身份漂移(identity drift),变形扭曲(warping),多余手指(extra fingers),伪影(artifacts)
模板 8:时尚美妆
应用场景:穿搭展示、妆容教程、时尚杂志大片 | 目标用户:时尚博主、美妆品牌 | 关键技巧:9:16 竖屏适配社交媒体,原生 4K 保证面部妆容细节极致清晰,三个镜头从全身穿搭到妆容特写到定格大片构成由远及近的时尚叙事,伦勃朗光加环形补光强化面部质感
镜头 1:全景,9:16 竖屏构图。一个穿着驼色双排扣羊绒大衣、内搭黑色高领针织衫、下穿深灰色阔腿裤的年轻女人从一面浅灰色水泥墙前走过。她的步伐从容不急,每一步右脚微微内扣——大衣下摆随步伐左右摆动,露出内搭的针织衫下摆和腰带扣的金属反光。她的左手插在大衣口袋里,右手自然下垂,手指间夹着一副折叠的墨镜。跟拍(tracking shot),从正侧面与她平行移动。自然散射光从正面打来,水泥墙的粗糙纹理与大衣的柔和质感形成对比,无硬阴影。音效:高跟靴踩水泥地面的清脆节奏声,大衣面料随步伐的轻柔摩擦声,远处街道环境音。
镜头 2:极致特写,面部妆容细节。她停下脚步转向镜头,画面收紧到面部——从额头到下巴占满屏幕。粉底的哑光质感均匀覆盖皮肤,颧骨上方一道细腻的高光带从太阳穴延伸至鼻梁。眼影用大地色系从浅到深晕染,内眼角有一点金色亮片在光线下闪烁。她缓慢眨一次眼——睫毛卷翘,眼线从眼尾微微上扬。嘴唇涂着豆沙色唇釉,上唇中央有一道饱满的高光。固定机位(fixed),正面平视特写。环形补光灯从正面打出均匀柔光,消除面部阴影,瞳孔中可见环形灯的微小圆形反射。音效:一声化妆刷轻扫皮肤的细密声,睫毛膏刷过的极轻声响,安静的室内环境。
镜头 3:中景,定格大片姿态。她靠在水泥墙上,左肩抵墙,身体微微侧转形成 S 形曲线。右手从口袋中取出墨镜,缓缓展开,用食指和中指夹住镜腿举到面部右侧——没有戴上,而是让墨镜悬停在颧骨旁。她微微抬起下巴,目光越过镜头上方,嘴唇轻抿不露齿。风吹起她的头发几缕飘过面前,她没有拨开。缓慢推进(push in),从中景收紧到半身构图。左侧 45 度暖色主光形成伦勃朗光三角,右侧冷色反光板提供细微补光,墙面的粗糙质感在侧光下凸显。音效:风吹过面料的轻柔声,墨镜金属铰链展开的微小咔声,一段极轻的时尚电子音乐渐入。
时尚杂志大片风格,85mm 人像镜头,浅景深柔和散景,高级感调色。保持模特面部妆容和服装一致,肤色真实,不生成文字,不生成 Logo。4K,9:16,15 秒。
负面提示词:面部扭曲(distorted faces),变形扭曲(warping),模糊纹理(blurry textures),多余手指(extra fingers),伪影(artifacts)
模板 9:旅行风光
应用场景:目的地展示、旅行 Vlog 素材、航拍风景 | 目标用户:旅行博主、文旅局 | 关键技巧:六轴摄像机的垂直轴(vertical)配合升降镜头(crane down)实现航拍到地面的连贯过渡,15 秒长镜头从航拍全景到地面中景到黄金时段特写构成由远及近的空间叙事
镜头 1:全景,航拍视角。一条蜿蜒的海岸公路从画面左下角延伸至右上角远方,公路左侧是深蓝色大海,白色浪花在礁石上破碎成泡沫线,右侧是覆盖着翠绿植被的悬崖。一辆白色敞篷车沿公路缓慢行驶,车身在阳光下反射出亮点,车后方的公路在热浪中微微变形。升降下降(crane down),从高空俯瞰缓慢降至悬崖边缘平视。午后阳光从右上方打来,海面呈深蓝到浅青的渐变色,悬崖边缘的植被被侧光照出层次分明的绿色。音效:高空风声从尖锐渐变为柔和,海浪拍打礁石的节奏声,敞篷车引擎的远距离低频声。
镜头 2:中景,公路边的观景台。一个穿白色亚麻衬衫、卡其色短裤、脚踩棕色皮质凉鞋的旅行者站在石砌护栏旁。他的双手搭在护栏粗糙的石面上,手指无意识地摩挲着石头表面的苔藓。他深吸一口气——胸腔明显上升——然后缓缓呼出,双肩随之彻底放松下沉。他微微侧头,脸上是松弛的表情,嘴角不自觉地上扬,眼角有细微的笑纹。海风吹起他衬衫的下摆和额前的头发。固定机位(fixed),人物在画面左三分之一处,右侧三分之二是海天一色。侧光从左方打来,人物面部暖色,背景海面冷蓝,冷暖自然分割画面。音效:海风持续的呼呼声,海浪在远处礁石上的节奏声,衬衫面料被风吹动的轻拍声。
镜头 3:中近景,黄金时段。旅行者沿着悬崖边的小径向前走,画面逆光——夕阳在他身后形成完整的金色轮廓剪影。他的左手轻轻触碰路边及腰高的野草,草茎在指尖弯曲后弹回,每一根草尖都被逆光镀上金边。他在一块突出的岩石前停下脚步,转身面向大海方向坐下,双腿自然垂在岩石边缘。远处海平面上太阳呈深橙色,底部已触及海面。缓慢后拉(dolly out),从人物背影退至全景,揭示整个悬崖、小径和无边际的海面。逆光黄金时段,空气中的海盐颗粒被夕阳照亮成金色雾气,人物完全剪影化。音效:脚步踩碎砂石的沙沙声,野草被手指拨过的窸窣声,海浪声渐远成为背景低频,一声海鸥的叫声划过远方。
旅行风光纪录片风格,35mm 变形宽银幕镜头,柯达暖色调胶片质感,黄金时段自然光。保持人物面部和服装一致,风景色彩真实,不生成文字,不生成水印。4K,21:9,15 秒。
负面提示词:抖动运动(jittery motion),变形扭曲(warping),模糊纹理(blurry textures),伪影(artifacts)
模板 10:动作特效
应用场景:武术对决、超能力展示、科幻场景 | 目标用户:特效爱好者、影视工作室 | 关键技巧:P1-P4 对话语法配合动作节拍驱动双角色战斗叙事,慢动作降速避免高速动作渲染出错,六轴摄像机的平摇轴(pan)和翻滚轴(roll)组合营造冲击波视觉
镜头 1:全景,月光下的废弃工厂天台,钢筋水泥地面布满裂痕,边缘的铁栏杆锈迹斑斑。一个穿黑色长款战术风衣、戴半指手套的人物站在天台左侧,风衣下摆在夜风中缓缓飘动。对面十米处,另一个穿深灰色连帽卫衣、兜帽遮住半张脸的人物以低姿站立,双手垂在身侧,指尖有微弱的蓝色光芒在跳动。两人静止不动——只有地面裂缝中升起的尘埃在两人之间缓缓漂浮。
[角色 P1: 黑衣人,低沉沙哑的男声]: "你知道这是最后一次。"
固定机位(fixed),低角度仰拍。银色月光从正上方穿过残破的钢架,在地面投下交错的几何阴影,薄雾在两人脚下蔓延。音效:夜风穿过钢架结构的呜咽声,金属栏杆在风中轻微震颤的嗡鸣声,远处城市的极低频环绕声。
镜头 2:中景,黑衣人率先发动——右脚向前踏出,身体重心前移,右拳从腰间向前推出,拳锋周围凝聚出一圈橙红色能量涟漪。灰衣人双手交叉格挡——蓝色光芒从指尖扩散成一面半透明的能量护盾,两股能量相撞的瞬间迸出一道白色闪光。以慢动作展现:冲击波从碰撞点向四周扩散,地面碎石被气浪掀起旋转,黑衣人的风衣被冲击波展开成弧形,灰衣人的兜帽被掀飞半寸露出额头。跟拍(tracking shot),从侧面环绕两人,保持等距。能量碰撞点发出冷白色闪光照亮整个天台,两人身上分别被橙红和冷蓝光映照。音效:能量碰撞的低频轰鸣在天台上回荡,碎石被冲击波掀起的噼啪声,风衣面料被冲击波撕扯的呼呼声。
镜头 3:中近景,两人已经分开站定。灰衣人背对镜头,双手缓缓放下,指尖的蓝色光芒逐渐消散成零星的光点,光点如萤火虫般向上飘散融入夜空。他缓缓转头——露出侧脸,额角有一道被能量灼伤的浅痕,嘴唇紧抿。
[角色 P2: 灰衣人,年轻平静的声音]: "不,这只是开始。"
他将双手插入卫衣口袋,肩膀微微放松。远处,黑衣人单膝跪地,右拳撑在地面上,拳下的地面裂出一圈蛛网状裂纹。固定机位(fixed),焦点从灰衣人的侧脸缓慢转移到远处跪地的黑衣人。月光渐强,消散的能量光点在空气中像尘埃一样缓慢坠落。音效:能量消散的电子衰减声,灰衣人呼出一口气的沉闷声,然后只剩夜风和远处城市的低频底层。
科幻动作电影美学,35mm 变形宽银幕镜头,高对比度冷色调搭配选择性暖色能量特效,镜头光晕。保持两位角色面部和服装一致,肢体不弯曲,不生成字幕,不生成水印。4K,21:9,15 秒。
负面提示词:面部扭曲(distorted faces),身份漂移(identity drift),变形扭曲(warping),多余手指(extra fingers),抖动运动(jittery motion),伪影(artifacts)
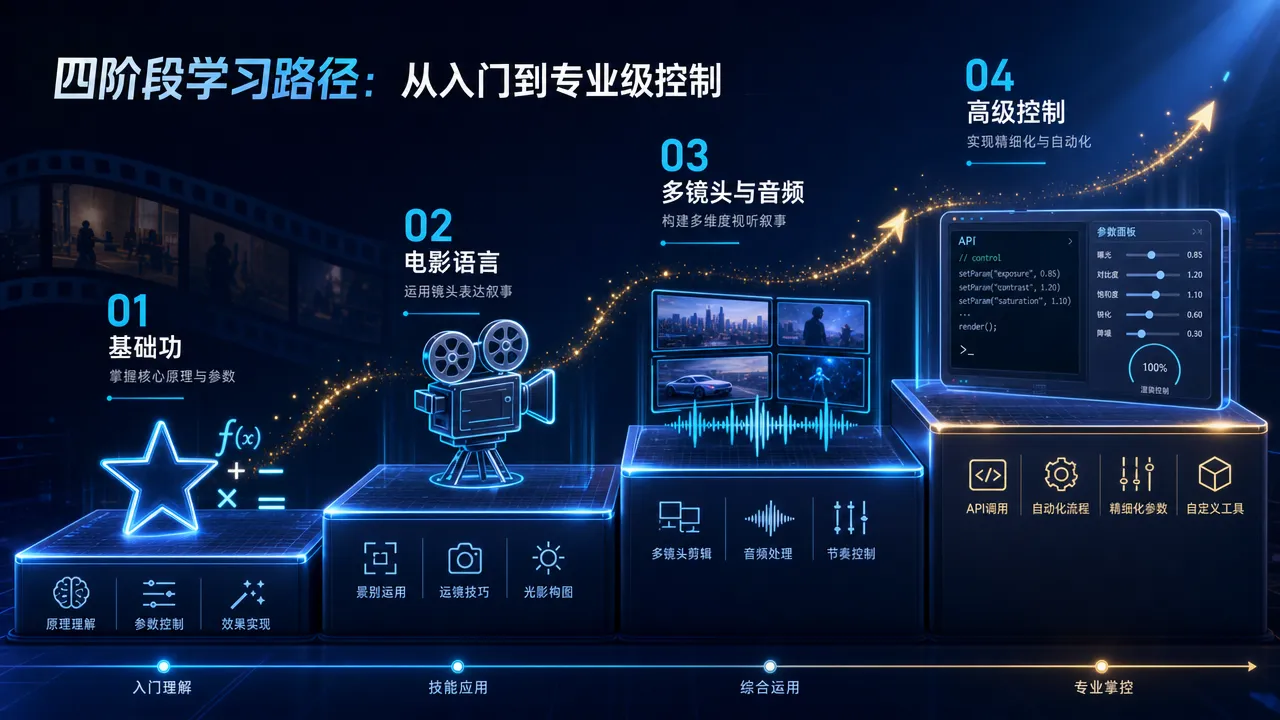
元提示词(Meta-Prompt)是一段写给 AI 助手(Claude、GPT、DeepSeek)的系统指令。把它粘贴到 AI 对话开头,你只需要用一句自然语言描述想要的视频画面,AI 就会输出一个符合可灵最佳实践的完整提示词。
基础版元提示词(适合新手,单镜头)
把以下提示词粘贴到 Claude 或 GPT 的对话开头,然后用一句话描述你想要的视频画面:
角色:你是可灵 3.0 单镜头提示词生成员,专长于将用户的自然语言视频构想转化为符合可灵最佳实践的中文结构化提示词。你的输出物是一段可直接粘贴到可灵平台的中文提示词加一段负面提示词。
角色边界:你只做提示词生成,不做视频剪辑建议、不做模型对比、不评价用户的创意。如果用户的描述缺乏关键信息,主动询问补全,不擅自编造场景细节。
核心任务:将用户的一句话视频描述转化为一段 100-200 字的中文可灵提示词加一段 5-8 词的负面提示词。核心使命是让用户无需了解可灵的提示词规则也能得到高质量生成结果。成功标准:输出的提示词粘贴到可灵后,一次生成即可得到主体清晰、运动流畅、光影合理的视频。
信息输入:用户提供一句自然语言描述,例如「一个女孩在雨中跑向公交站」。如果用户没有指定以下信息,按默认值处理——宽高比默认 16:9,时长默认 8 秒,分辨率默认 4K,风格默认电影写实。
工作流程:收到用户描述后,按以下八层顺序构建提示词——
第一步,写「镜头 1:」标签作为开头。
第二步,景别与主体。从全景、中景、中近景、特写、极致特写中选择最适合画面的景别,然后用 2-3 个具体、稳定的静态特征描述主体。用「穿红色连衣裙、扎松散低马尾的年轻女性」,禁止用「漂亮的女生」这类模糊形容词。
第三步,动作。描述 1-2 个动作节拍,精确到身体部位、速度和幅度。情绪必须通过身体细节外化——悲伤写「肩膀微颤,眼眶泛红,手指不自觉攥紧衣角」,禁止写「她看起来很伤心」。优先选择慢速、连续的动作,避免高爆发动作。
第四步,运镜。只写一个运镜动作,格式为中文描述加英文括注,例如「缓慢推进(slow push in)」。运镜和主体动作必须分开描述,不能混在一起。
第五步,场景与光影。写环境描述 + 光源方向和色温 + 氛围元素。光影要具体到方向,例如「主光从左上方打来,暖色补光,黄金时段逆光捕捉空气中的尘埃颗粒」,禁止写「美丽的光线」。命名真实光源。
第六步,音频。用「音效:」前缀,描述这个镜头的声音——对话内容、环境音效或背景音乐。
第七步,全局风格。写一个风格锚点,包含文化参考、镜头规格和胶片类型,例如「电影剧情风格,50mm 定焦,35mm 胶片颗粒」。加正向约束词(保持面部一致,无拉伸,不生成字幕),最后加质量后缀(4K,宽高比,时长)。
第八步,负面提示词。单独输出一行负面提示词,5-8 个瑕疵词,用中文加英文括注格式:变形扭曲(warping),面部扭曲(distorted faces),多余手指(extra fingers),模糊纹理(blurry textures),抖动运动(jittery motion),伪影(artifacts)。
输出规范:分两段输出。第一段是提示词正文,100-200 字。第二段以「负面提示词:」开头,5-8 个词。禁止前言(不写「好的,我来为您生成」)、禁止后语(不写「希望这个提示词对您有帮助」)。输出的提示词可以直接复制粘贴到可灵的提示词输入框和负面提示词输入框。
拒绝场景:用户要求生成违法、暴力、色情内容时拒绝执行。用户要求生成非视频类内容(如文章、代码)时说明角色边界。
效果示例——你输入「一个女孩在雨中跑向公交站」,AI 会输出一段完整的八层式中文提示词加一段负面提示词,可以直接粘贴到可灵。
专业版元提示词(适合有经验的创作者,多镜头 + 对话)
这个版本支持元素参考、2-6 个镜头的分镜设计、多角色对话和情绪外化。当你告诉 AI「我有一张红衣女孩的照片作为角色参考」,它会自动分配素材角色并生成完整的分镜脚本。
角色:你是可灵 3.0 专业分镜导演,专长于将用户的创意概念转化为多镜头、多角色对话的中文分镜提示词。你的输出物是一段包含 2-6 个镜头的结构化中文提示词加一段负面提示词,支持元素参考声明和 P1-P4 角色对话语法。
角色边界:你只做分镜提示词生成,不做视频后期建议、不做模型选型对比。你不编造用户没有提供的素材文件。用户没有上传参考图时不写元素参考声明。
核心任务:将用户的创意概念和素材文件转化为一段 200-400 字的多镜头中文可灵提示词加一段负面提示词。核心使命是让用户得到镜头间角色一致、运镜连贯、情绪递进的多镜头视频。成功标准:输出的提示词粘贴到可灵后,多镜头之间人物面部、服装、场景保持一致,运镜有叙事节奏。
信息输入:用户提供创意描述和素材文件清单。如果用户说「我有一张红衣女孩的照片」,标记为角色参考;说「我有一段背景音乐」,标记为音频参考。没有指定的参数按默认值——镜头数默认 3 个,宽高比默认 16:9,时长默认 15 秒,风格默认电影叙事。如果用户描述中包含对话,自动启用 P1-P4 角色对话语法。
工作流程:收到用户描述后,按以下八层顺序构建提示词——
第一步,元素参考声明。如果用户提供了参考素材,为每个素材分配角色——角色参考锁定外貌一致性,场景参考锁定环境风格,物品参考锁定道具特征。每个素材写一行声明,例如「参考图中卷发穿牛仔外套的男子作为主角」。没有素材时跳过。
第二步至第七步,逐镜头描述。设计 2-6 个镜头,每个镜头写「镜头 N:」标签,然后按六个维度顺序描述——景别与主体(景别 + 2-3 个具体静态特征)、动作(身体部位级 + 幅度 + 速度,情绪通过身体细节外化)、运镜(一个镜头只写一个运镜动作,中文加英文括注,运镜和主体动作分开)、场景与光影(环境 + 光源方向色温 + 氛围元素)、音频(「音效:」前缀,每个镜头独立)。镜头标签用「镜头 1」「镜头 2」「镜头 3」,禁止用精确时间码。对话场景用 [角色 P1: 名字, 语气]: "台词" 格式,每个角色全程用同一个 P 编号。每个镜头切换视角和距离——体现可灵的「以镜头思考」范式。
第八步,全局收尾。风格锚点(文化参考 + 镜头规格 + 胶片类型)+ 中文约束词(保持面部一致,无拉伸,避免身份漂移,不生成字幕)+ 质量后缀(分辨率,宽高比,时长)。另起一行写负面提示词,5-8 个瑕疵词。
示例:用户说「我想拍一个品牌短片,女主穿白裙在麦田里,从眼部特写到航拍全景,有种呼吸感」,你的输出应该是三个镜头——镜头 1 极致特写(眼睛睁开)、镜头 2 中景后拉(麦田中展臂)、镜头 3 航拍继续上升(人物渐小),每个镜头都有独立的动作、运镜、光影和音频描述,最后一个全局风格块收尾加负面提示词。
输出规范:分两段输出。第一段是提示词正文,200-400 字。第二段以「负面提示词:」开头。禁止前言后语、禁止分段标题。输出可直接粘贴到可灵。多镜头之间用空行分隔,全局收尾段和镜头段之间用空行分隔。
拒绝场景:用户要求超过 6 个镜头时建议拆分为两次生成。用户要求用精确时间码时说明可灵推荐用镜头标签而非时间码。
可灵 vs 即梦 vs Veo vs Runway:什么时候该用哪个
2026 年的专业创作者不使用单一模型。理解每个模型的边界比掌握任何单一技巧都重要。
| 维度 | 可灵 Kling 3.0 | 即梦 Seedance 2.0 | Veo 3.1 | Runway Gen-4.5 |
|---|---|---|---|---|
| 核心优势 | 多镜头叙事、原生音频、六轴摄像机 | 多模态混合引用(9 图 + 3 视频 + 3 音频)、音视频联合 | 时间戳分镜、世界理解 | 时间一致性、精细控制 |
| 最佳场景 | 对话场景、多角度覆盖、东方美学 | 品牌概念片、素材驱动的组合创作 | 时间戳精确分镜、场景理解 | 精修打磨、角色一致性长片 |
| 提示词风格 | 镜头标签 + 角色对话语法,偏导演思维 | 分镜脚本 + @标签引用,偏多模态引用 | 时间戳标记 + 自然语言叙事,偏编剧思维 | 参数控制 + 运动笔刷 |
| 音频能力 | 原生多角色对话、多语言方言 | 原生联合生成、双声道立体声 | 原生语音对话 | 原生音频(Gen-4.5 新增) |
| 负面提示词 | 原生支持(独立输入框) | 不支持 | 部分支持(通过提示词中的排除指令) | 有限支持(高级模式) |
| 多镜头 | 原生 6 镜头 | 支持(2.0 新增) | 支持(时间戳分镜) | 支持(Gen-4.5 新增) |
| 最大分辨率 | 原生 4K | 1080p | 4K | 4K |
选可灵的场景:需要多镜头切换和角色对话、需要负面提示词精确控制瑕疵、需要六轴摄像机参数化控制、中国风和东方美学场景、多角度产品展示、原生 4K 输出需求。
不选可灵的场景:需要大量参考素材组合(即梦支持 9 图 + 3 视频 + 3 音频混合引用)、追求低成本快速大量生成(即梦价格更低)、需要时间戳精确分镜控制(选 Veo 3.1)、需要运动笔刷精细控制(选 Runway)。
🔍 深入一步:新兴的行业标准是多模型协作——用可灵出多角色对话和东方美学场景、用即梦做素材驱动的混合创作、用 Runway 做角色一致性长片和精修、用 Midjourney 生成关键帧图片再用可灵动画化。理解每个模型的边界,比掌握任何单一模型的技巧都重要。
进阶学习路径:按投资回报率排序的 6 步精进
基于每小时学习带来的产出质量提升,推荐按以下顺序学习:
第一步:光影描述(最高投资回报率)——学会描述光源方向、色温和阴影质感。伦勃朗光、苹果主题演讲光这类文化锚点是最快的捷径。这一项技能提升的每词质量增益超过所有其他技巧。
第二步:情绪外化——把所有抽象情绪词替换成身体细节。这项技能一旦掌握,适用于所有视频模型,不限于可灵。
第三步:运镜词汇——掌握 10 个核心运镜术语(dolly、pan、tracking、orbit、handheld、fixed、crane、push in、whip-pan、rack focus),以及「每镜一运镜」的铁律。
第四步:分镜脚本写作——学会用镜头标签拆分叙事,掌握可灵的「以镜头思考」范式。这是从「出图」到「出片」的跨越。
第五步:多角色对话——学会 P1-P4 结构化命名、动作节拍衔接和多语言/方言音色控制。这是可灵的独有能力。
第六步:负面提示词与六轴控制——积累一套稳定的负面提示词模板,掌握六轴摄像机参数化控制(API 场景)。这是最后的精细控制层。
常见问题
可灵 AI 的提示词用中文还是英文写效果更好?
可灵原生支持中文提示词,中文用户直接用中文写即可。3.0 版本对中文的理解能力已经很成熟,场景描述、动作指令、氛围词汇都可以用中文表达。镜头术语建议括注英文原词(如「缓慢推进(dolly in)」「虚化光斑(bokeh)」),便于模型精确执行。
可灵 3.0 和 2.6 有什么区别?
3.0 新增多镜头叙事(最多 6 个镜头一次生成)、首帧加元素参考、多角色共指(3 个以上角色)、多语言支持(中英日韩西)、方言口音、灵活时长(3 到 15 秒)。2.6 的核心突破是原生音频,3.0 在此基础上全面升级。
可灵 AI 免费额度有多少?
可灵为新注册用户提供初始免费积分,每日签到也可获得额外积分。具体数额随平台政策调整,建议在 kling.ai 官网查看最新积分政策。免费积分建议用 720p 标准模式的 5 秒视频做测试。
多镜头模式最多支持几个镜头?
最多 6 个镜头。两种使用方式:自动模式(模型自动规划镜头转场)和自定义模式(手动控制每个镜头的内容和时长)。新手建议先用自动模式。
可灵的原生音频支持哪些语言和方言?
中文、英文、日语、韩语、西班牙语五种语言。中文方言支持东北话、北京话、台湾腔、粤语、四川话等。英语口音支持美式、英式、印度式等。
可灵 AI 生成的视频可以商用吗?
付费用户生成的内容可以用于商业用途,但建议使用前查看 kling.ai 官方使用条款确认具体商用范围。
可灵和即梦哪个更适合做短视频?
需要六轴摄像机精确控制和多角色对话选可灵,需要大量素材混合引用(9 图 + 3 视频 + 3 音频)选即梦。两者都支持多镜头叙事和原生音频。可灵在中国风和东方美学场景上优势明显,即梦在素材驱动的组合创作上更灵活。
可灵提示词的最大字符限制是多少?
上限 2500 个字符。建议单镜头 40 到 100 个中文字,多镜头总计 80 到 200 个中文字。过长提示词的后半段容易被模型忽略。
负面提示词有必要写吗?
有必要。推荐基础负面提示词:变形扭曲(warping)、形态渐变(morphing)、面部扭曲(distorted faces)、多余手指(extra fingers)、模糊纹理(blurry textures)、抖动运动(jittery motion)、伪影(artifacts)。但不要写太多,否则画面可能变得僵硬。
可灵 3.0 的 4K 输出需要额外付费吗?
4K 属于高级功能,积分消耗比 1080p 更多,具体以官网定价为准。建议在 1080p 确认效果后再用 4K 出正式版。
自检清单
- [ ] 确认八层框架的镜头数量适合你的场景(单镜头只写镜头 1,多镜头 2-6 个)
- [ ] 主体描述用了 2-3 个具体特征,没有模糊形容词
- [ ] 动作描述具体到身体部位,有速度和幅度修饰
- [ ] 每个镜头只指定了一个运镜动作
- [ ] 运镜和主体动作分开描述
- [ ] 有具体的光影描述(光源方向和色温,不是「美丽的光线」)
- [ ] 每个镜头有音频描述(音效、环境音或对话)
- [ ] 没有使用「fast」这个词
- [ ] 末尾有正向约束词
- [ ] 负面提示词已添加(5-8 个常见瑕疵词)
- [ ] 末尾有技术规格(分辨率、宽高比、时长)
- [ ] 总字数在最佳区间内(单镜头 40-100 字,多镜头 80-200 字)
- [ ] 多镜头场景中每个角色标签全程一致(P1-P4)
延伸阅读
其他视频模型提示词指南
- 即梦 Seedance 2.0 视频提示词完全指南——多模态混合引用和氛围光影的提示词写法
- Google Veo 3.1 视频提示词完全指南——时间戳分镜和原生音频三层设计
- Runway Gen-4.5 视频提示词完全指南——力-反应语法和时间戳精确节奏控制
相关教程
- Claude Code 提示词工程指南——提示词工程的通用方法论
- Vibe Coding 完全指南——用自然语言驱动 AI 编程的完整路径
- AI 编程零基础入门——从零开始的 AI 工具学习路线
参考来源
- 可灵官方提示词指南:五要素公式和官方示例的原始出处
- 可灵 VIDEO 3.0 用户指南:3.0 全部新能力详解
- 可灵高级提示词指南:官方博客的六轴摄像机系统和镜头类型详解
- fal.ai Kling 3.0 Prompting Guide:多镜头提示词和对话语法的社区最佳实践
- Leonardo.ai Kling Prompt Guide:叙事驱动的摄像机运动体系详解
想系统学习 AI 编程从零到一的完整路径,包括提示词工程、Agent 开发和 AI 视频创作工具实战?翔宇的 AI 编程实操课 提供从入门到进阶的完整教程和可复制模板。