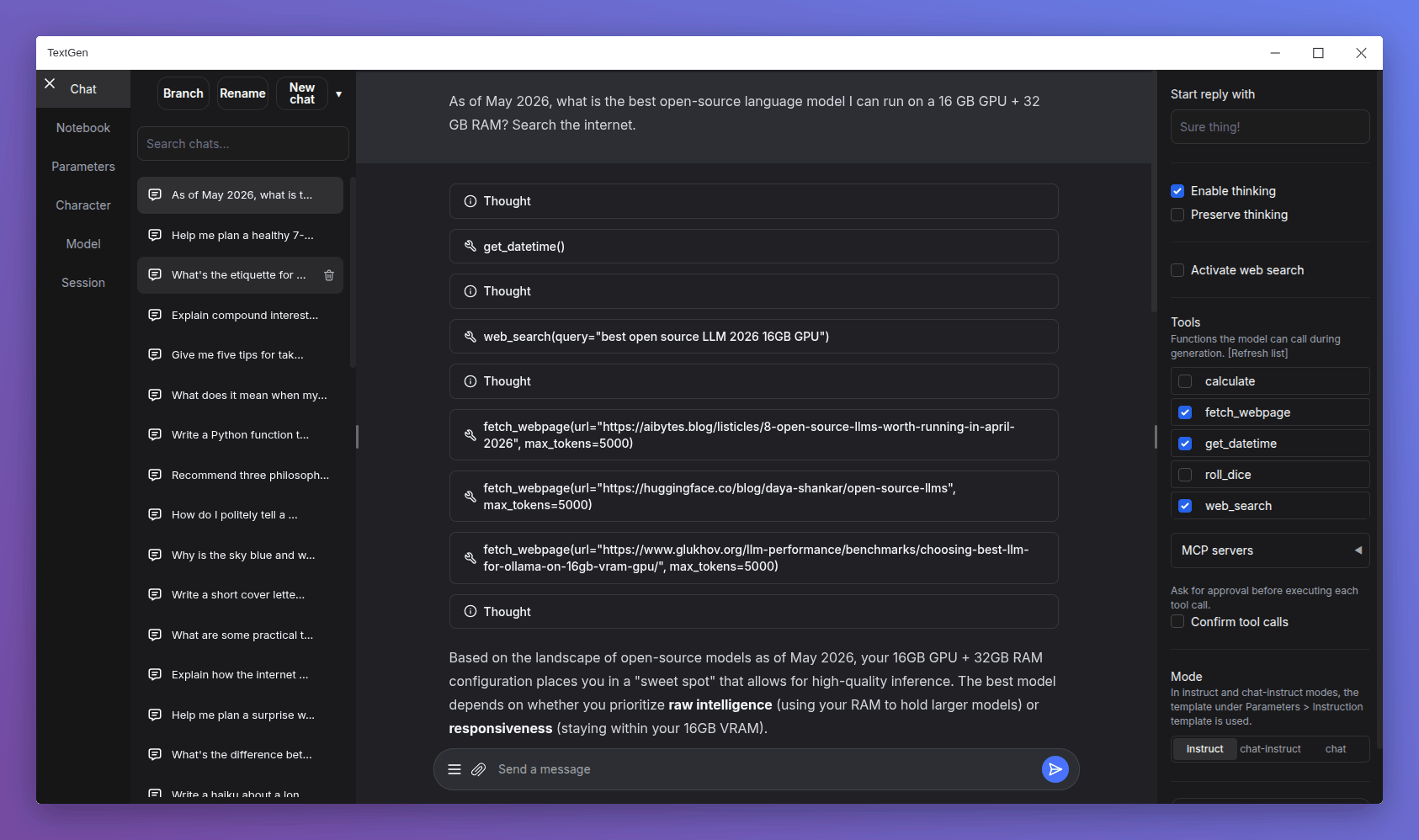
textgen / textgen.bat instead of the previous start scripts. Pass --listen or --nowebui to skip the window and run the server directly.--split-mode flag (replacing --row-split) with a tensor option that can make multi-GPU inference 60%+ faster. On the ik_llama.cpp backend, tensor and row fall back to graph..jinja/.jinja2 instruction template files in the UI, in addition to the existing .yaml format (#7517).user_data/extensions (#7525).TextGen is now a desktop app for local LLMs. Download, unzip, double-click.
Note
NVIDIA GPU: If nvidia-smi reports CUDA Version >= 13.1, use the cuda13.1 build. Otherwise, use cuda12.4.
ik_llama.cpp is a llama.cpp fork with new quant types. If unsure, use the llama.cpp column.
| GPU/Platform | llama.cpp | ik_llama.cpp |
|---|---|---|
| NVIDIA (CUDA 12.4) | Download (891 MB) | Download (1.23 GB) |
| NVIDIA (CUDA 13.1) | Download (816 MB) | Download (1.33 GB) |
| AMD/Intel (Vulkan) | Download (336 MB) | — |
| AMD (ROCm 7.2) | Download (604 MB) | — |
| CPU only | Download (318 MB) | Download (334 MB) |
| GPU/Platform | llama.cpp | ik_llama.cpp |
|---|---|---|
| NVIDIA (CUDA 12.4) | Download (848 MB) | Download (1.20 GB) |
| NVIDIA (CUDA 13.1) | Download (803 MB) | Download (1.32 GB) |
| AMD/Intel (Vulkan) | Download (324 MB) | — |
| AMD (ROCm 7.2) | Download (395 MB) | — |
| CPU only | Download (306 MB) | Download (334 MB) |
| Architecture | llama.cpp |
|---|---|
| Apple Silicon (arm64) | Download (271 MB) |
| Intel (x86_64) | Download (283 MB) |
user_data folder with the one in your existing install. All your settings and models will be moved.Starting with 4.0, you can also move user_data one folder up, next to the install folder. It will be detected automatically, making updates easier:
textgen-4.6/ textgen-4.7/ user_data/ <-- shared by both installs
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。