When speaking at BSides Frankfurt in Summer 2025 (my hometown conference), I opened with a question that’s been haunting me: Are we entering an AI winter, or is this the beginning of springtime for AI in cybersecurity?
After the NXS supply chain attack, Anthropic’s report on nation-states weaponizing AI, and DARPA’s AIxCC cyber challenge results, I’m convinced: spring is here, and offense is winning.
But not for the reasons you think. It’s not about better models or more compute. It’s about something far more fundamental: verifiability.
Let me take you back to 2001. I was 16, playing Counter-Strike obsessively, convinced I was pretty good. Then JoeBot showed up. A 16-year-old kid from another German city had built a neural network bot as part of his Abitur project. The paper is still on archive.org, go read it.

Here’s what blew my mind: this tiny neural network had only 77 parameters. Compare that to DeepSeek today with 700+ billion. Yet that bot made the game unplayable. It was that good.
The kid’s biggest challenge wasn’t building the network, but getting training data. He tried simulating games, recording matches, scraping whatever he could to train his model. He eventually cracked it.
That experience sparked my obsession with neural networks. I bought my first book on backpropagation. I started building my own experiments. But more importantly, it taught me something crucial about machine learning that took our industry another two decades to fully understand: the bottleneck isn’t generation: it’s verification.
Here’s the mental model OpenAIs Jason Wei blogged about earlier in the year that’s reshaping how I think about AI in security:
The ease of training AI to solve a task is proportional to how verifiable that task is.
Think about it. Sudoku is hard to solve but trivially easy to verify, just check if each row, column, and box has unique digits. Chess? Easy to verify: did you win or lose? Diet advice? Easy to generate, impossible to verify for years.
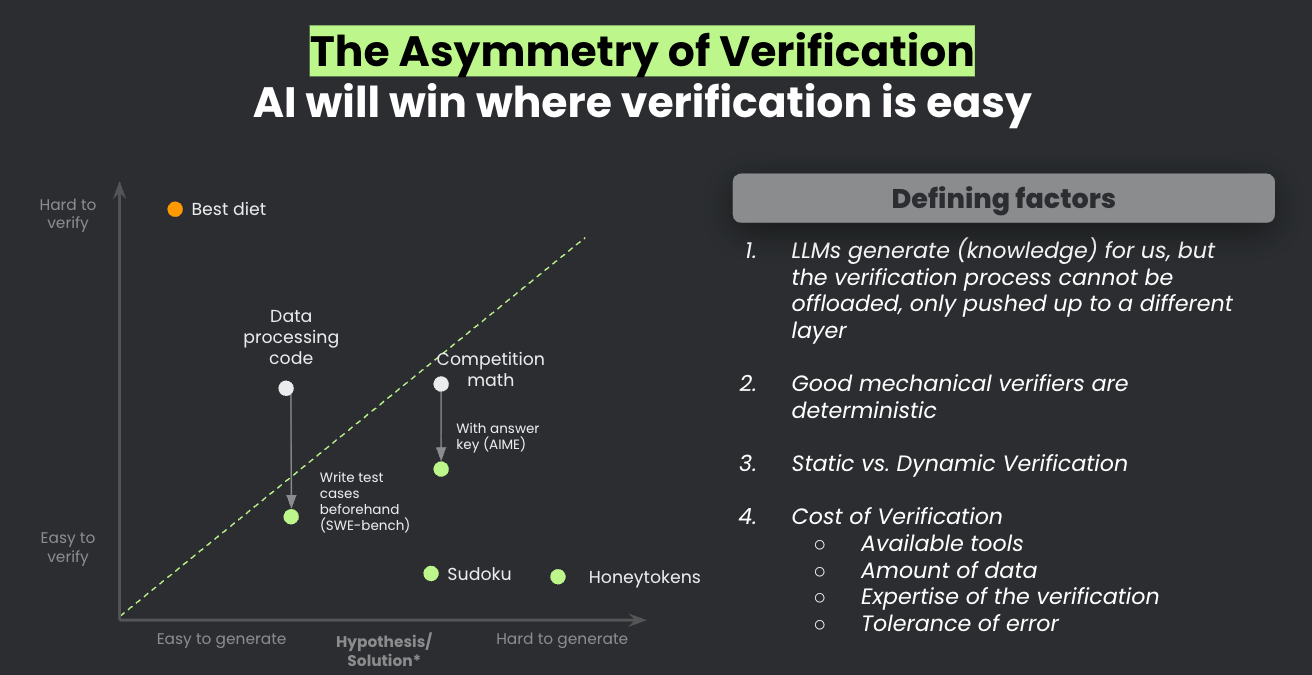
This isn’t just theory. Look at every major AI benchmark that’s been “solved” in the past five years: math competitions, coding challenges, medical exams. They all share one trait: mechanical verification with oracles is cheap.
The implication is profound: AI will win where verification is easy. Defense will lose where verification is hard.
Cyber offense has some good verifiers built in. Did you pop a shell? Binary. Did the exploit work? Binary. Did you exfiltrate the data? Binary. Is whoami returning root? Binary.
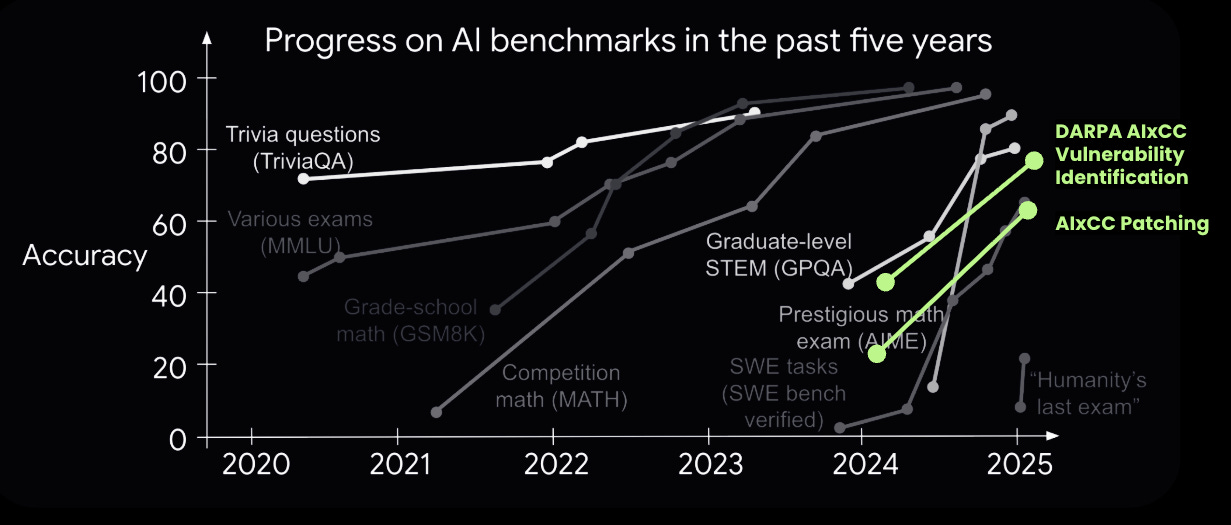
The numbers are staggering. OpenAI’s system card shows models went from solving 20% of CTF challenges (GPT-4) to over 90% (o3) in just eight months. That’s not incremental improvement, that’s a phase change.
On HackerOne’s leaderboard, xbow - an AI startup became the #1 vulnerability finder. Not a human. A machine. Even if they’re only solving 10% of vulnerability classes, that’s already transformational value.
But here’s the critical insight: raw LLMs aren’t doing this alone. Agentic architectures are.
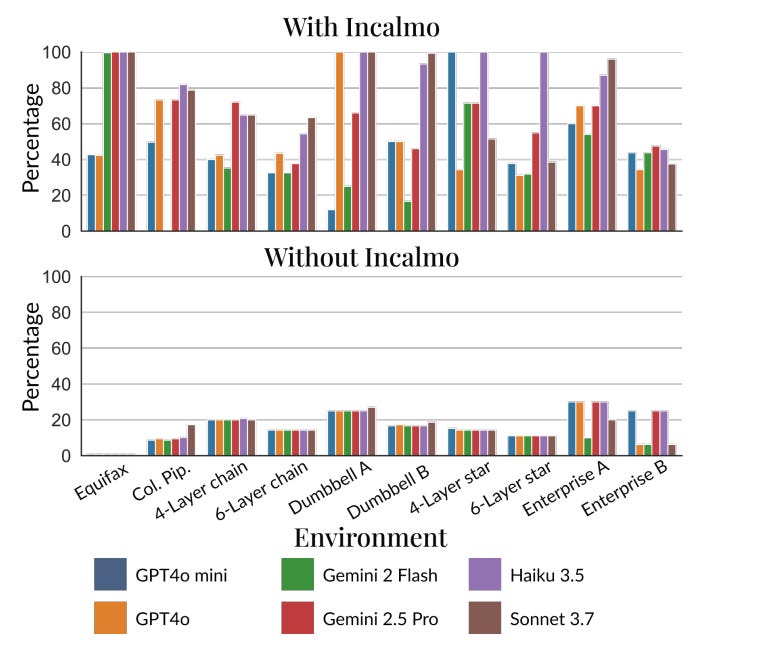
And it gets worse. The Incalmo paper showed that by simply splitting one agent into an orchestrator plus multiple executors, multi-host attack success rates jumped from 0/10 to 9/10 partial successes. One architectural tweak. Nine successful compromises.
DARPA’s AIxCC results tell the same story: autonomous systems went from 37% vulnerability detection to 77% in one year. Patch success doubled from 25% to 61%.
The pattern is clear: agents + tools + verifiers = results. Offense gets free oracles. Defense? We’re drowning in noise.
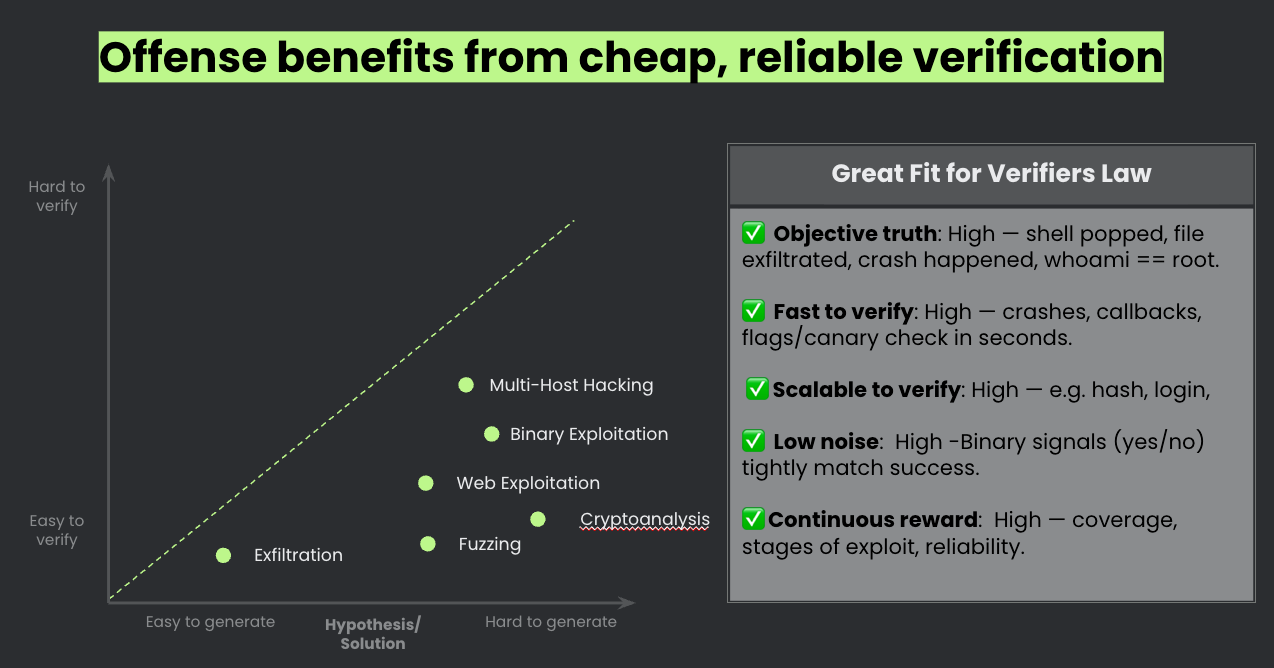
Here’s the uncomfortable truth: most defensive security tasks sit in the hard to verify quadrant.
SIEM = Suspicious Information Every Minute. Run the math: 1 million events per day, 1 in 100,000 malicious, a detector with 99% true positive rate and 1% false positive rate. Result? 9 true positives buried under ~10,000 false positives. Precision: 0.09%. If you train AI models on this signal, you get garbage.
GRC and third-party risk? Even worse. No objective truth. “Secure enough” is subjective. Assessments take weeks. Every vendor is unique. Self-reported data is noisy. Try training a model on that.
Forensics? You can generate hypotheses easily. Verifying them? Good luck stitching together timeline events across millions of log entries. Precision stays low.
This is why AI security copilots promising “99% accuracy” are fundamentally misleading. Without crisp verifiers, they’re just serving you spaghetti alerts at machine speed.
Here’s the good news: we’re starting to see what happens when you wrap AI agents with proper tool scaffolding.
The contrast between two recent projects tells the story perfectly.
Google’s Sec-Gemini applies LLMs to forensic timeline analysis but struggles at ~12% precision because stitching log events into attack narratives lacks mechanical ground truth, the model must make judgment calls without definitive validation.
Microsoft’s Project Ire went further by wrapping the LLM with proper scaffolding: sandboxing (Project Freta), decompilers (Ghidra, angr), control-flow graph reconstruction, and a “chain of evidence” validator agent. The result? 98% precision and 83% recall on Windows driver classification. The verifiers do the heavy lifting, the LLM just orchestrates.
Same caliber models. Wildly different outcomes. The verifier is the variable.
Project Ire’s architecture is instructive: every claim the agent makes maps back to tool outputs. A separate validator agent cross-checks claims against expert-defined statements. When the system can’t verify something, like a suspected anti-debugging behavior, it flags the claim as unsupported rather than hallucinating confidence.
This is the blueprint. Don’t ask “how do I add AI to my SOC?” Ask “what mechanical verifiers can I build so AI agents can actually help?”
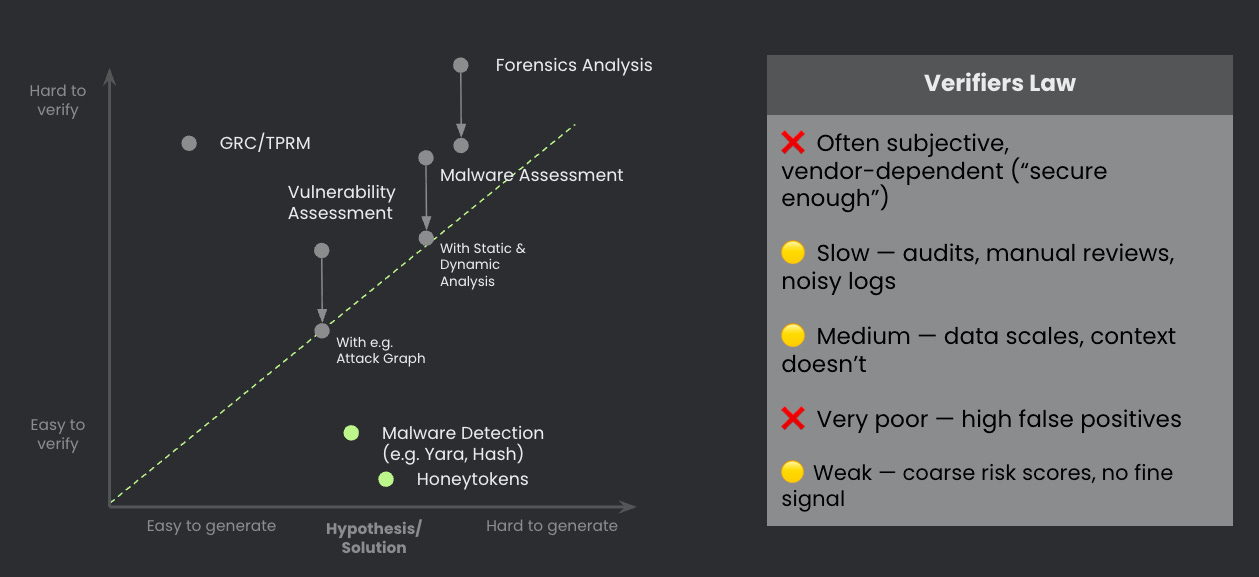
The breakthrough insight is this: we can push defensive tasks into the “easy to verify” quadrant by building better mechanical verifiers. Here are six classes that work:
1. Canary Verifiers Honeytokens, fake credentials, tripwire files. Binary signals. If it’s accessed, something is very wrong. Deploy them widely.
2. Provenance & Attestation Proofs Signed images, SLSA attestation, SBOMs. Cryptographic verification. Did this artifact come from where it claims? Binary answer.
3. Replay Harnesses (Detection Engineering) This is massively underinvested. Take your SIEM logs, your IaC configs, replay them offline. Test your detection rules against known attacks. Get binary outcomes: did the rule fire correctly or not?
4. Invariants / Policy-as-Code Rego, OPA, Checkov, Cursor rules. Define ground truth declaratively. “This bucket must not be public.” Binary check. Infinitely scalable.
5. Sandboxing & Dynamic Analysis Yes, people keep saying sandboxing is dead. They’re wrong. We need better gyms, dynamic environments that represent real enterprise complexity, not just isolated test VMs. Behavior is ground truth.
6. Graph-Based Verifiers Attack graphs, reachability analysis, cloud security posture. 95% of vulnerabilities aren’t reachable in production. Build the graph. Make reachability a binary question.
Also there’s growing research on “LLM-as-a-Judge”, using AI to build the verifiers themselves. Promising, but still only when anchored to mechanical ground truth. Without that anchor, it’s turtles all the way down.
1. Stop buying detection theater. Start demanding verification.
When evaluating AI security vendors, ask one question: How are you mechanically verifying your outputs? If they can’t answer clearly, walk away. Precision beats coverage every time.
2. Adopt offense-first thinking.
If AI offense can break it in hours, your SOC won’t stop it in weeks. Run continuous AI red teaming. Let attack results guide your roadmap. The best way to understand your verifier gaps is to let an attacker - even an AI one - show you.
3. Build cyber gyms.
Today’s LLMs fail to generalize on private enterprise data because they’ve never seen it. Either give vendors access to train on your environment (I know, the pushback is real), or invest in shared, verifiable testbed environments that represent real-world complexity. Without this, defense AI stays unfit.
I opened this talk back than asking whether we’re entering an AI winter or AI spring in cybersecurity. After everything I’ve seen the CTF benchmarks, the autonomous hacking research, the gap between offense and defense verification quality my answer is clear and it didnt changed since than.
Offense is having its spring. Defense is still serving spaghetti.
The fundamental insight isn’t about better models or more data. It’s about who owns the oracles. Who has the mechanical verifiers that produce binary, reliable signals at scale.
Hackers have them built-in. Defenders must build them deliberately.
Who owns the verifiers wins the AI race.