Modern cloud environments include thousands of resources across providers, teams, and accounts. Organizations need the ability to quickly locate the right resources so that they can manage resource compliance and troubleshoot issues. When engineers need to answer questions such as which databases are still on extended support or which storage buckets lack encryption, they often have to switch consoles, use provider-specific query languages, and know obscure version strings or configuration flags.
With its latest enhancements, Datadog Resource Catalog helps solve these challenges. Resource Catalog gives you a complete inventory of your cloud infrastructure and offers natural language querying (NLQ) that provides an accessible way to learn about your cloud resources. Instead of building complex queries, simply ask questions in plain English and let NLQ translate your intent into a query to explore your infrastructure.
In this post, we’ll show how you can use Resource Catalog to:
Explore your inventory of cloud resources across providers
Search resources by using natural language
Resource Catalog helps you govern your infrastructure resources and cloud services across providers so that you can manage resource compliance, track ownership, identify security risks, troubleshoot incidents, and optimize costs. Rather than stitching together views from AWS, Microsoft Azure, Google Cloud, Oracle Cloud Infrastructure (OCI), and Kubernetes consoles, you can explore a shared catalog that pulls in resource metadata, configuration details, and relationships.
Resource Catalog now supports more than 1,000 resource types, over 5 times as many as before. New additions include Amazon Route 53 record sets, Amazon API Gateway APIs, and AWS Transit Gateways, along with support for OCI resources, including Oracle Autonomous AI Databases. As Datadog cloud integrations and the Datadog Agent collect information from your environments, Resource Catalog organizes that telemetry data in a unified format.
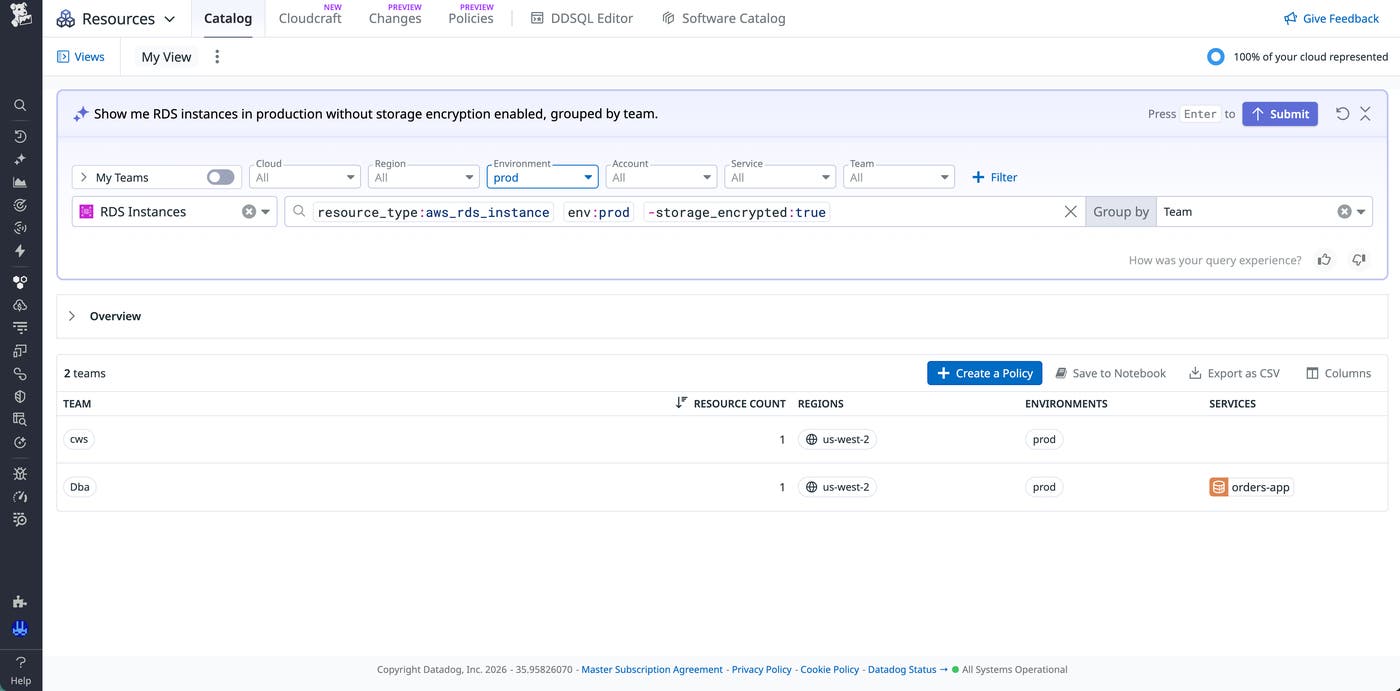
Engineers often need to slice the catalog by multiple dimensions, such as “RDS instances in production without storage encryption enabled, grouped by team.” Without NLQ, identifying those kinds of resources requires precise knowledge of attribute names, possible values, and how to express them in provider-specific or catalog-specific query syntax.
Resource Catalog already supported structured search with key-value pairs as well as clickable filters for attributes such as account, region, and engine version. NLQ lets you express your intent in plain English. When you type a query, Resource Catalog translates that sentence into a structured query that filters on resource type, environment, and encryption configuration. The resulting view automatically gives you relevant columns, such as the resource count and linked service.
NLQ can also help with more specialized questions that depend on domain knowledge. For example, you might want to audit databases that are running on extended support engine versions, but you might not remember the exact version numbers that qualify. With NLQ, you can submit a query such as “List all the RDS instances with extended support engine versions by engine.” NLQ then uses AI to interpret which versions fall into extended support and apply the appropriate filters.
NLQ, structured search, and clickable filters work together rather than in isolation. You can start with a broad query in natural language to capture intent, refine the resulting key-value expression directly, add filters from the sidebar, and group the table by attributes such as team or region. When you arrive at a useful view, you can save it so that you and your collaborators can reuse it for repeat workflows such as quarterly compliance checks or weekly cost reviews. This capability makes the Resource Catalog infrastructure inventory more accessible to nontechnical members of your team.
With more than 1,000 resource types across AWS, Azure, Google Cloud, and OCI, Resource Catalog provides a complete, centralized inventory that you can use to browse and learn about your infrastructure. NLQ gives you a practical and accessible way to answer questions about your infrastructure without memorizing attributes, values, or version strings. These new features are available for all Datadog sites, including US1-FED.
To start using NLQ, use the search bar in Resource Catalog to make your natural language requests. As you go, you can share feedback about NLQ responses by using the thumbs-up or thumbs-down controls to help us improve future responses.
To learn more about Resource Catalog and its capabilities, check out the Resource Catalog documentation. If you’re new to Datadog, you can sign up for a 14-day free trial to get started.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。