This guest blog post is by Tohn Furutani, SRE Engineer at NTT DATA.
Over the past year, the conversation around generative AI has shifted from single-shot use cases—such as summarization, Q&A, and chat interfaces—to agentic AI systems that can make decisions based on context, plan multistep actions, invoke tools, and adapt as conditions change. As system integrators that collaborate with enterprise customers, we at NTT DATA have explored this shift by continuously validating agentic workflows in our internal AI testbed, GenAI Tech Hub.
Through this work, we quickly learned that the hardest part of agentic AI is making it dependable in production. Enterprises need more than accuracy and speed: They need security, visibility into system decisions, consistent system behavior, and a path to ongoing improvement.
We set out to develop and validate a reusable approach to meet those requirements, building an operational foundation for agentic AI by combining Amazon Bedrock AgentCore with Datadog LLM Observability. In this blog post, we’ll share the decisions that we made and the implementation insights that we gained along the way.
In the early stages of agentic AI development, it’s possible to get a proof of concept (PoC) working with a common approach: containerizing the application, exposing an API, and implementing IAM and tool integrations individually. We started there as well. However, as validation expanded and use cases became more complex, the challenges became clear.
Each time we added a new agentic workflow, we spent more time on the basics: how it runs, how it authenticates, how it connects to tools, and how it keeps session state. That left less time for what we wanted to improve: the agent’s reasoning and the end-user experience. In discussions with enterprise customers, we also consistently faced questions such as the following: Where does it run? How are tool calls controlled? How do we isolate environments? How do we manage versions? Answering these questions from scratch for every PoC doesn’t scale.
We therefore adopted Amazon Bedrock AgentCore to standardize the execution platform and help our teams focus on improving agentic logic. Amazon Bedrock AgentCore provides essential enterprise capabilities such as the Runtime execution environment where AI agents run, tool governance through Gateway, integration with Memory and Identity, and version management. It offered us a solid foundation that we could reuse across use cases.
The next problem we faced was different: Agentic AI behavior can be difficult to fully understand if you use traditional observability approaches alone. Issues in agentic systems do not always appear as clear failures like “it crashed” or “it’s slow.” In many cases, the system may look successful (for example, HTTP 200 responses, successful external API calls, and no exceptions), yet the user experience is still not what you intended.
This challenge stems from the fact that agentic workflows are not a single request followed by a response. They are built from layered steps, including LLM calls, tool invocations, and conditional branching. If decisions shift at any point, the outcome can change. And because LLM behavior is non-deterministic, the same input does not always guarantee identical behavior.
Traditional application performance monitoring is effective for identifying where errors occurred or what is slow. But for agentic AI, the core challenge often shifts from errors to decision quality. Without understanding which reasoning step led to which tool selection and what context influenced the decision, it becomes difficult to run a reliable improvement cycle.
At this point, we concluded that we needed observability that enables us to track agentic reasoning (LLM decisions) and agentic actions (tool execution) in the same context. Our goal was to achieve operationally useful visibility with minimal changes to our existing implementation.
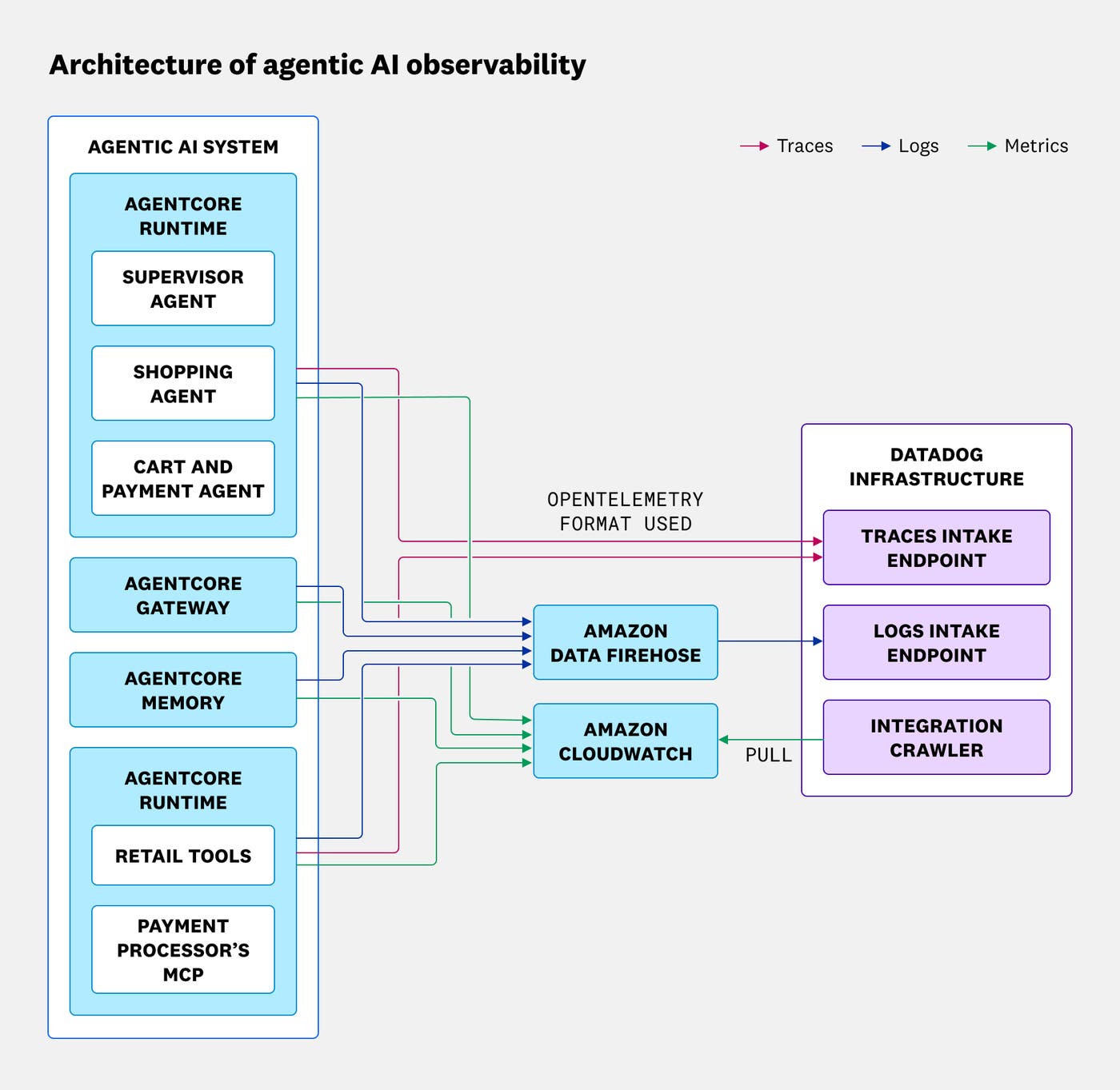
In our validation, we used the Strands Agents SDK, an agent framework that supports OpenTelemetry by default and can emit attributes aligned with GenAI semantic conventions (v1.37 or later) such as gen_ai.*. Datadog can automatically recognize these GenAI attributes and ingest them into LLM Observability, enabling simplified data integration without requiring custom formats or dedicated conversion layers. As a result, we were able to focus on operational essentials such as applying consistent metadata (for example, service.name, env, and version) and propagating trace context across boundaries so that we could analyze agentic behavior in Datadog.
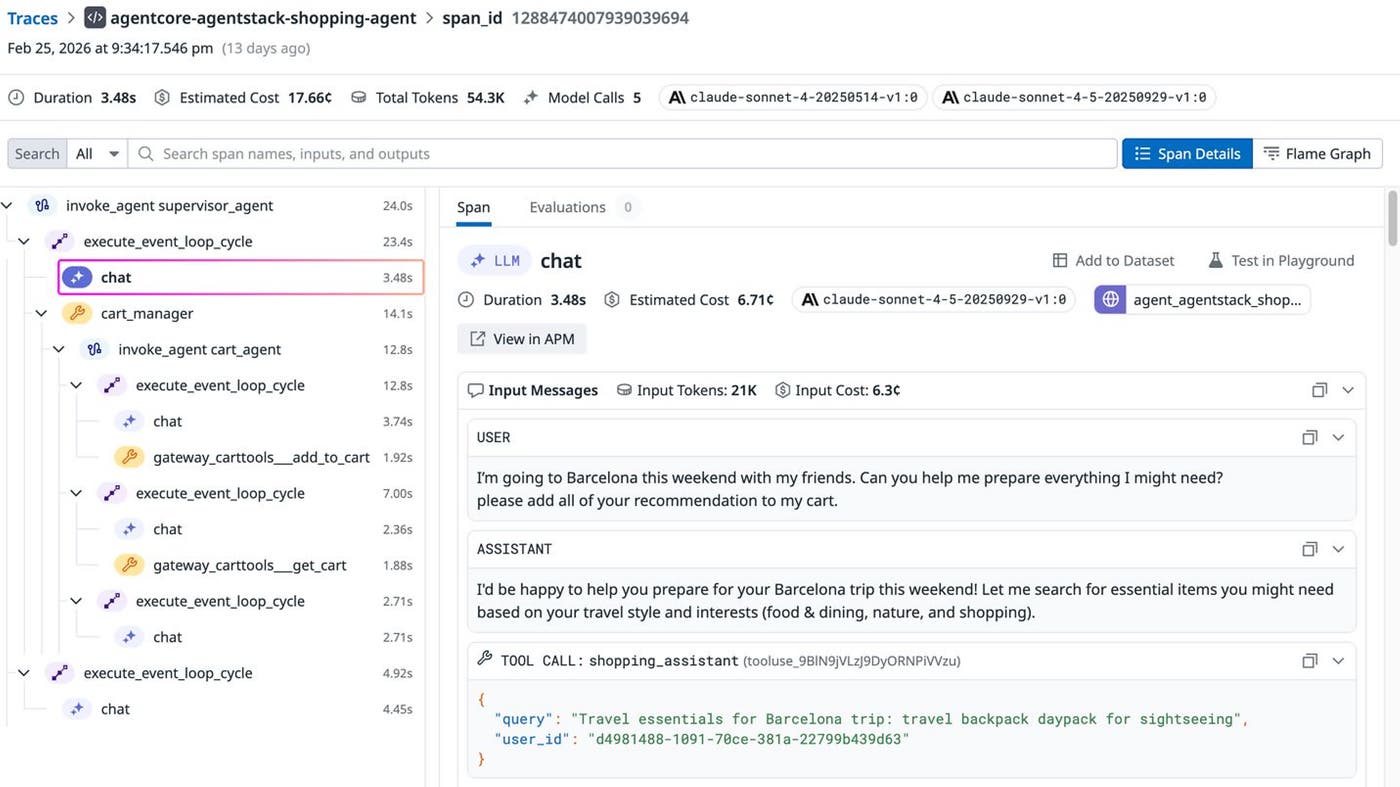
From an implementation perspective, three activities were especially important:
Aligning telemetry data with GenAI semantics
Integrating Amazon CloudWatch data with Datadog
Incorporating evaluation into operational workflows
First, we aligned our telemetry data with OpenTelemetry GenAI semantic conventions (v1.37 or later). Because we used Strands, we achieved this alignment by setting the OTEL_SEMCONV_STABILITY_OPT_IN environment variable. As with traditional application performance monitoring, metadata such as service.name and env must remain consistent. Otherwise, services and environments become fragmented in Datadog, making comparison and analysis difficult.
Agentic systems often span multiple components (for example, an orchestrator, the AgentCore Gateway, and MCP services), so we had to propagate trace context (trace IDs) consistently across boundaries. For observability of LLM-based systems, exporting telemetry data from individual components does not provide a complete picture. The traces and attributes must be structured so that the entire workflow appears as a single coherent trace.
When you run agent workflows on Amazon Bedrock AgentCore, its Runtime and Gateway components emit logs to CloudWatch. To analyze these signals alongside application and LLM telemetry data in Datadog, we integrated CloudWatch logs and CloudWatch metrics with Datadog by using the Datadog AWS integration. This integration makes it easier to investigate issues without switching tools and helps you correlate agentic behavior with platform-level signals.
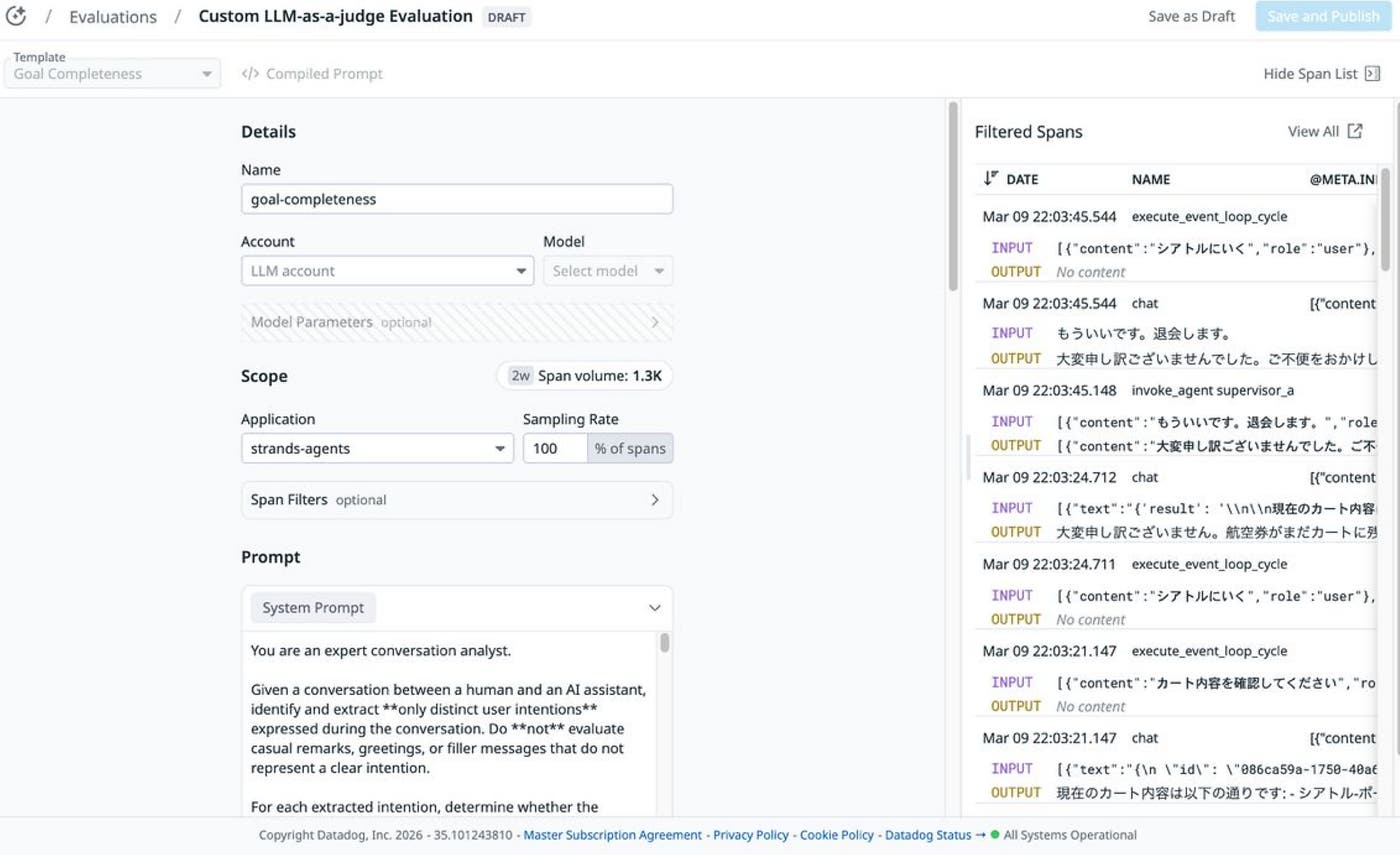
We found strong value in bringing evaluation into operations. For agentic AI, establishing visibility is not enough. To translate observations into operational decisions, it is important to define evaluation criteria and check them continuously in production-like workflows. Examples include:
Tool selection: Was the chosen tool appropriate?
Tool argument: Were tool arguments correct?
Prompt injection resilience: Is the system resilient to instruction injection?
Goal completeness: Did the workflow achieve the user’s goal?
These criteria help us avoid treating failures as isolated incidents and provide a consistent framework that we can use to define quality standards for continuous improvement. Datadog supports this approach because it enables us to manage observability (with Application Performance Monitoring (APM), Log Management, and LLM Observability) and operations (with monitors, notebooks, and Cloud Cost Management) in the same place. As a result, we can embed evaluation results into operational workflows more easily.
Standardizing the combination of Amazon Bedrock AgentCore and Datadog is important to us because it helps us move beyond one-off PoCs toward a reusable solution for customer deployments. Specifically, we are templating this integration as a standard demo so that new use cases don’t require us to rebuild everything from scratch. By continuously validating within GenAI Tech Hub and aligning both operational metadata and evaluation criteria, we support ongoing improvement and steadily increase speed from PoC to production.
We are also extending these lessons beyond our internal teams through community sharing and collaboration. In Japan, we have continued our external knowledge sharing through the publication of technical articles that include hands-on implementation details. We have also provided the Datadog and AWS teams with technical feedback based on our validation results and are collaborating with them on improvements. In addition, we held a joint webinar with AWS and Datadog in March 2026. Through these efforts, we aim to help build an ecosystem for operable and explainable agentic AI that enterprises can adopt with confidence.
In this post, we shared how NTT DATA is combining Amazon Bedrock AgentCore and Datadog to help make agentic AI ready for enterprises to use in production. In our experience, getting agentic AI to work isn’t enough. You also need to understand why agents made particular decisions—and keep improving the agentic system over time.
Amazon Bedrock AgentCore gives us a stable, repeatable way to run agentic workflows. Meanwhile, Datadog LLM Observability makes the system observable in everyday operations and helps us use evaluation to drive continuous improvement with minimal additional implementation. Going forward, we will continue standardizing this approach within GenAI Tech Hub as reusable templates to further accelerate the transition from PoC to production. We also plan to give back through collaboration with Datadog and AWS, and through broader community sharing.
Our conclusion is clear: The strategy of standardizing execution with Amazon Bedrock AgentCore and operationalizing observability and evaluation with Datadog has been effective for us. We believe that this division of roles is a practical path toward building agentic AI systems that enterprises can operate reliably and improve with confidence.
If you don’t already have a Datadog account, you can sign up for a 14-day free trial to get started.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。