SREs and application developers rely on telemetry data to understand and improve their systems. As organizations scale and evolve, those systems generate an ever-growing volume of metrics, logs, and traces. But more data alone does not make it easier to improve performance or reliability: Identifying meaningful optimizations still requires careful investigation and analysis. Meanwhile, the rapid pace of software development leaves little time for this work, making it easy to fall behind on the fixes and improvements needed to run applications reliably and efficiently.
Datadog APM Recommendations addresses this problem by analyzing telemetry data from Datadog Application Performance Monitoring (APM), Continuous Profiler, Real User Monitoring (RUM), and Database Monitoring (DBM) and making specific, actionable recommendations. These recommendations highlight performance, reliability, and resource efficiency issues; explain why they matter; and provide guidance on how to address them before they escalate.
In this post, we’ll explore how APM Recommendations helps you:
Detect emerging performance and reliability issues
Triage recommendations and assign ownership with full context
Track ongoing recommendations across teams and environments
With no additional setup or configuration, APM Recommendations analyzes your underlying telemetry data for common anti-patterns such as N+1 database queries, repeated sequential API calls, and aggressive retries. It surfaces optimization opportunities on the APM home page, in context on APM Service pages, and on the new APM Recommendations Overview page, giving you a centralized view to assess recommendations across your system by team, service, and environment. You can see the full list of supported recommendations in our documentation.
Let’s say that you manage a service named inner-cart for a high-traffic ecommerce application. No alerts are firing, and there are no open incidents. However, during a routine performance review, you open the service page in Datadog. A new high-priority recommendation appears for the production environment and indicates a detected pattern that is slowing down cart operations. The issue could lead to cascading failures if it is left unaddressed.
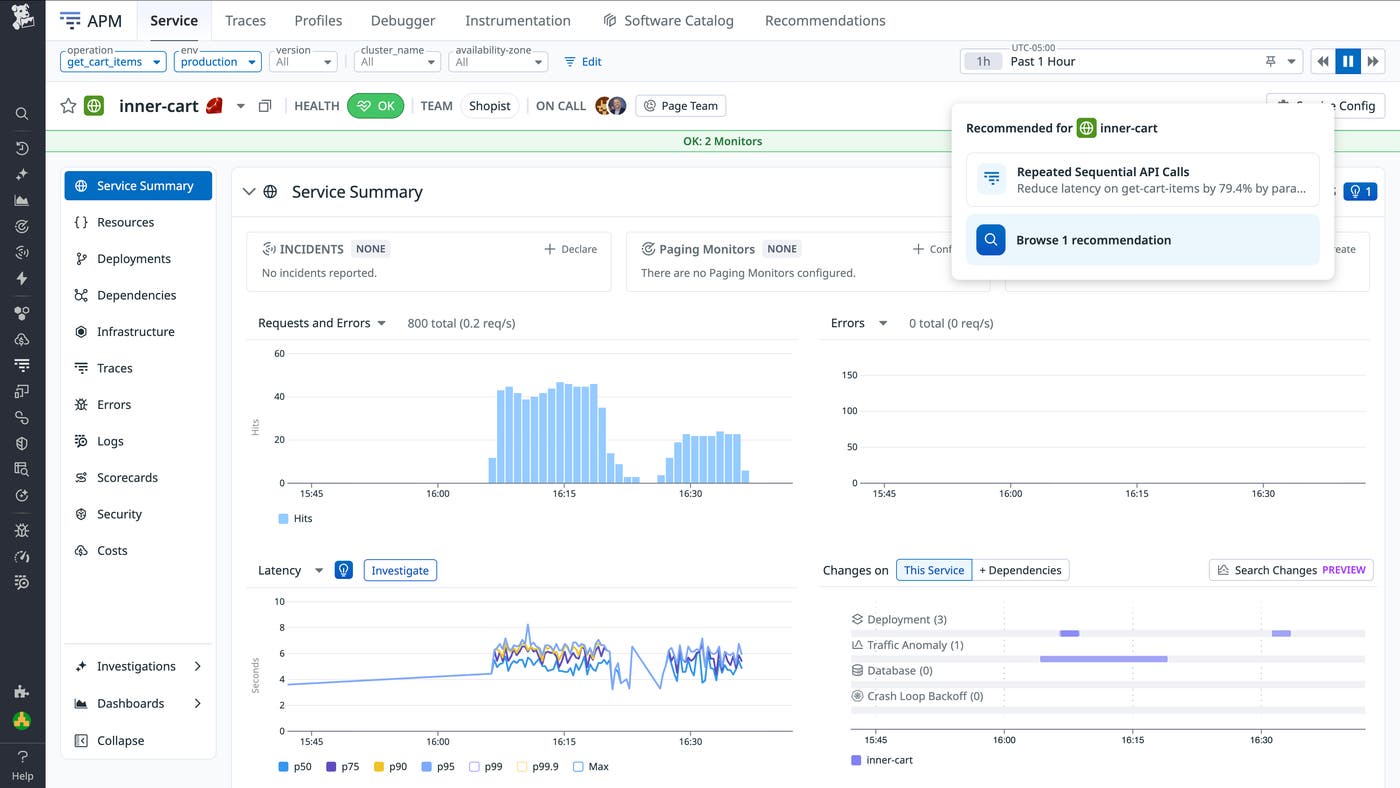
The priority score for the issue (in this case, high) is based on forecasted business impact and is automatically assigned on a scale of high, medium, and low. The score also reflects the impact of the potential improvement (in this case, reducing latency for this resource) and the relative importance of the service, which is inferred from traffic volume compared to peers.
To capture urgency accurately, APM Recommendations also considers recency and real-time spikes in activity. For teams that use APM and RUM, prioritization includes the detected user impact of the specific issue. The result is a ranked list that reflects where engineering effort is likely to deliver the most value.
Each recommendation summarizes the issue, its potential impact, and the supporting evidence behind the priority score, in addition to suggesting next steps. This context helps you understand why the recommendation matters.
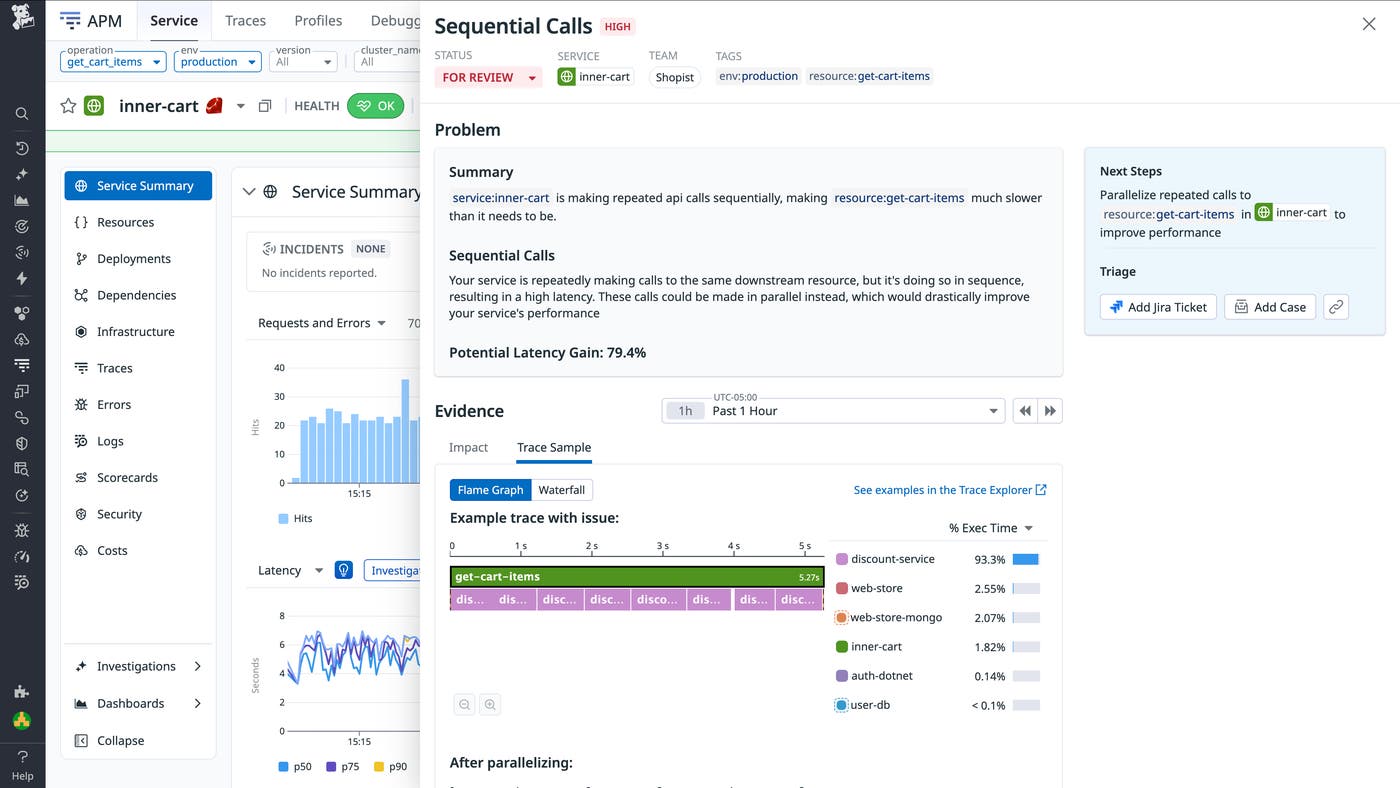
When you move into triage, the recommendation details help you evaluate the issue in depth. In this example of the inner-cart service, the recommendation identifies repeated sequential API calls. Each individual call is fast, but because the calls execute one after another, overall latency grows with cart size.
The Evidence section highlights an example trace where the get-cart-items span has a duration of several seconds, with downstream discount lookups nested beneath it and occurring sequentially. The bottleneck is the cumulative pattern, not a single slow call.
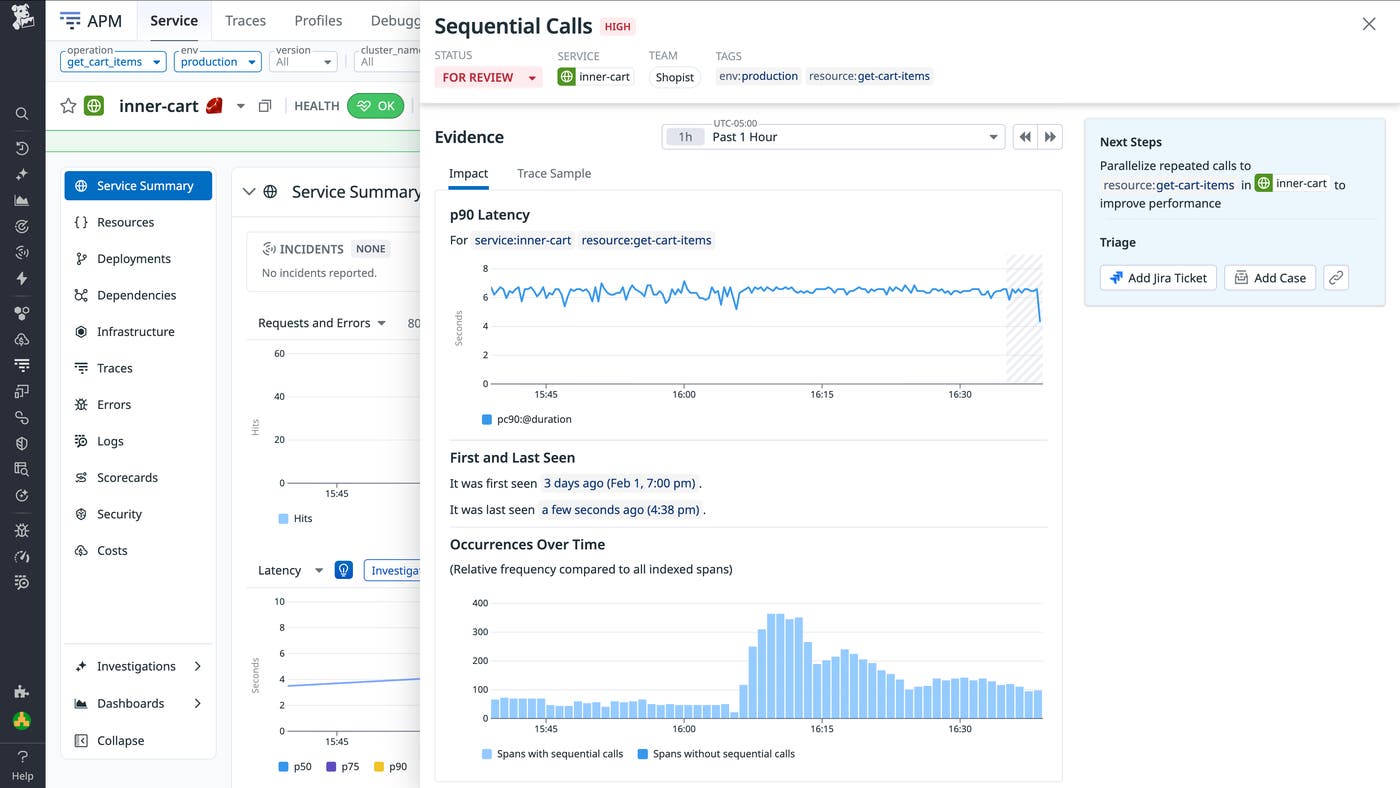
The Impact tab reveals occurrence data that shows when this behavior first appeared and how frequently it occurs relative to all indexed spans. In this case, the issue emerged 3 days ago and persists into the present, suggesting that addressing it proactively can prevent future user-facing impact.
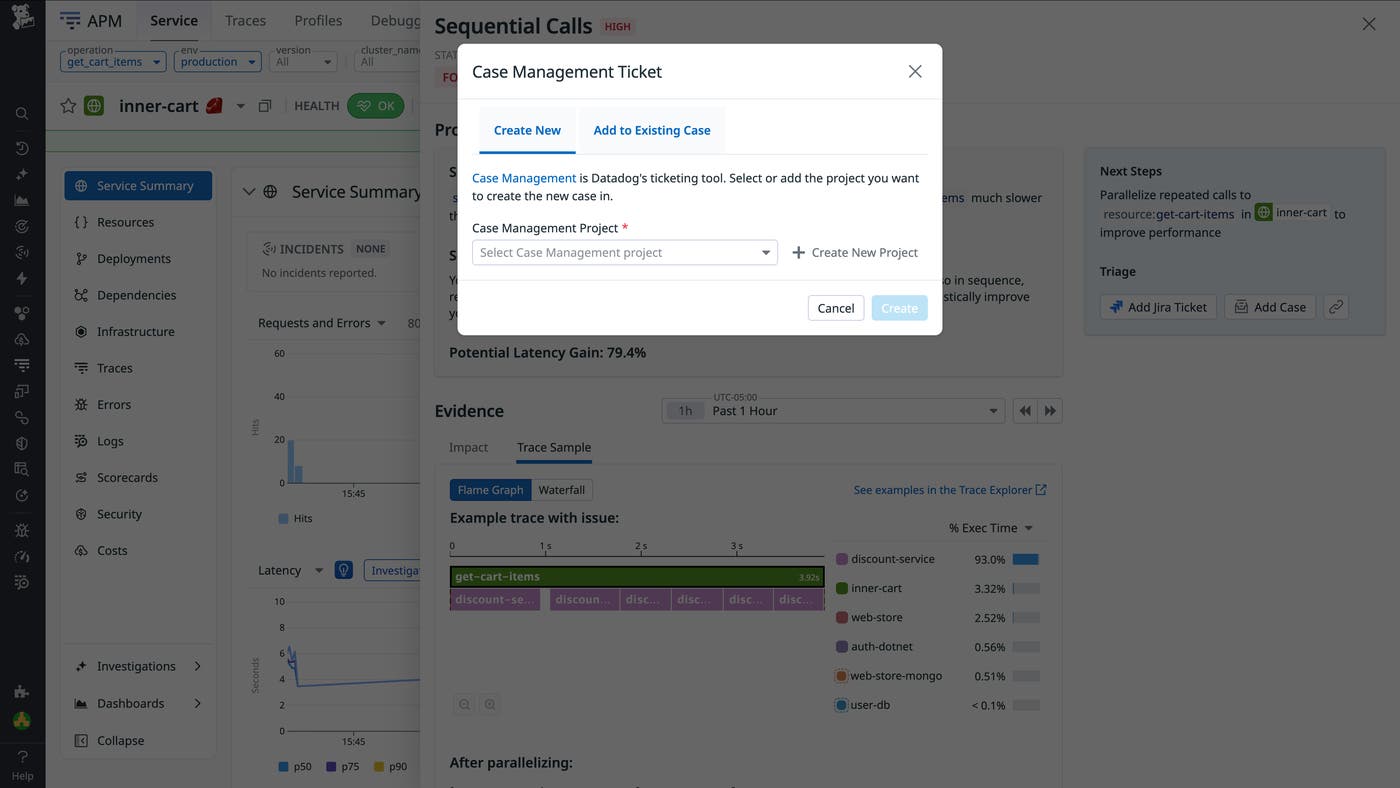
If your team already has a fix in progress, you can ignore a recommendation. Otherwise, you can assign it to a team member in Datadog Case Management or create a Jira issue for it and track progress there. The linked ticket is automatically populated with the problem summary, trace links, affected services, and suggested next steps.
For a broader perspective, the APM Recommendations Overview page provides a consolidated view of recommendations across all services and environments. This view helps teams spot recurring patterns, identify systemic inefficiencies, and track progress over time beyond a single service.
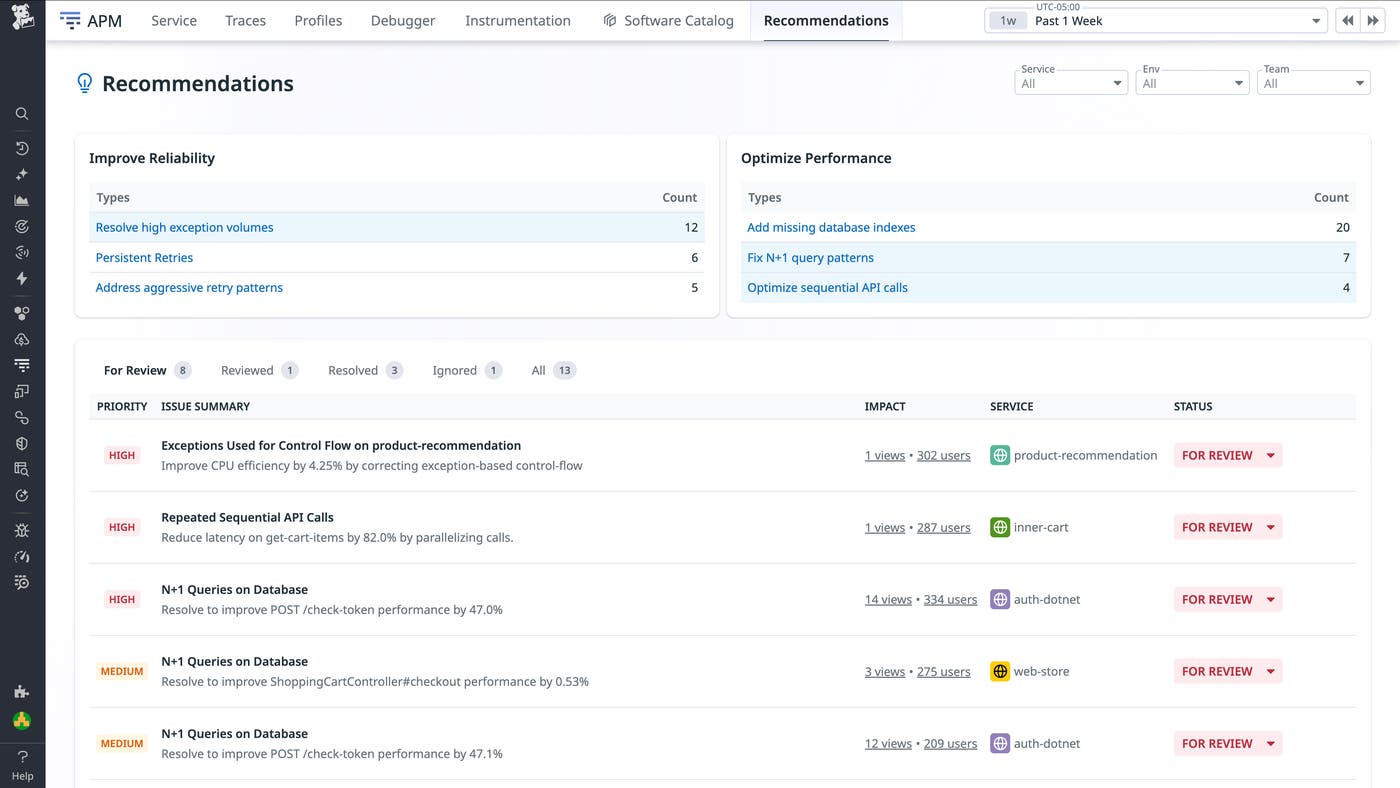
As fixes are implemented, whether that means batching requests, parallelizing calls, or implementing exponential backoff, Datadog continues to analyze the underlying symptoms. When telemetry data indicates that an issue has been addressed, the recommendation is automatically marked as resolved. By acting at this stage, before alerts fire or customers are affected, you can reduce the risk of incidents and prevent small inefficiencies from compounding into larger reliability or performance problems.
APM Recommendations helps teams move from reactive troubleshooting to proactive optimization. By identifying issues early, prioritizing them based on impact, and embedding guidance directly into existing workflows, it enables teams to improve performance, reliability, and efficiency without requiring them to have deep expertise in every service. To learn more, check out the APM Recommendations documentation.
If you’re new to Datadog, you can sign up for a 14-day free trial to get started.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。