When engineers investigate SQL queries, they normally think of index scans as a fast and efficient step in the query’s execution plan. When executed correctly, they fetch only the relevant rows from your table as opposed to sequential scans that read the entire table, reducing latency and query costs. However, just because an execution plan uses an index scan doesn’t mean that the scan is fast or performant.
In this blog, we’ll unravel a case of an expensive index scan that Datadog was using to query a PostgreSQL table in our production environment. We’ll walk you through why the execution plan was inefficient and slow despite being an index scan, and how we used a targeted index to cut average query latency from 300 ms to 38 μs.
We’ll also cover updates to Datadog Database Monitoring (DBM) that automatically detect suboptimal index scans across PostgreSQL and other databases. DBM flags these issues and recommends a fix so you can surface and resolve similar patterns without manual investigation.
Our PostgreSQL database includes a recommendations table that stores customer recommendations, such as long-running queries, missing indexes, query regressions, and more.
Table "public.recommendations"
Column | Type | Nullable | Default
------------+--------+----------+------------------------------------------------
id | bigint | not null | nextval('recommendations_id_seq'::regclass)
org_id | bigint | not null |
type | text | not null |
dbms | text | not null |
entity | text | not null |
severity | text | |
tags | jsonb | |
description | text | |
Indexes:
"recommendations_pkey" PRIMARY KEY, btree (id)
"unique_entity_dbms_org_type" UNIQUE, btree (entity, dbms, org_id, type)
One of the indexes for this table is unique_entity_dbms_org_type, a composite unique index that ensures no two rows share the same combination of entity, dbms, org_id, and type. The most frequently executed query joins recommendations with a separate mute table that tracks muted recommendations for each customer organization. Each time a user opens DBM, our frontend runs this query to determine which recommendations to show within the Datadog app.
SELECT r.id, r.entity, r.type, r.severity,
array_agg(m.id) AS mute_ids
FROM recommendations r
LEFT JOIN mute m ON m.recommendation_id = r.id
WHERE r.org_id = ?
AND r.dbms = ?
GROUP BY r.id;
Our engineers first flagged this query for investigation after noticing that its runtime seemed much longer than expected, especially given its frequency of execution. Upon inspecting its execution plan in DBM, they confirmed that the query was performing an index scan using unique_entity_dbms_org_type.
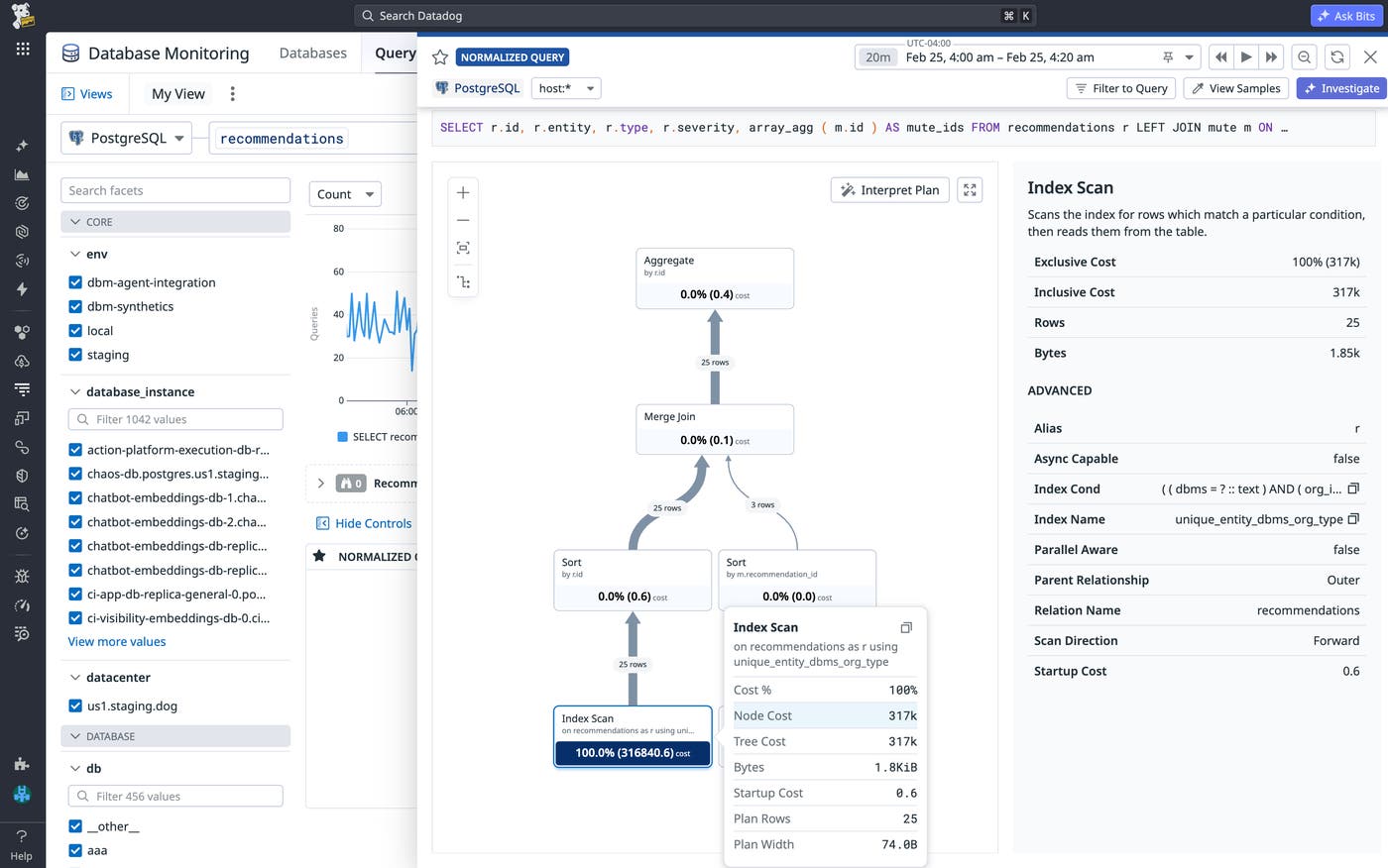
Normally, an engineer might conclude their investigation after confirming the correct index and scan type is being used. However, this query had a relative node cost of 317,000 and accounted for 100% of the total query cost, while returning only 25 rows. The mismatch between node cost and the number of rows returned was a huge red flag. It signaled that the query was indexing inefficiently and driving up the query’s latency.
The reason our index scan was so expensive was because of a mismatch between the column order of our index and the query’s predicates. unique_entity_dbms_org_type is defined as a B-tree index, which means its entries are ordered from left to right by column:
(entity, dbms, org_id, type)
However, our query filters the recommendations table using the following:
WHERE r.org_id = ? AND r.dbms = ?
The leading column of our index is entity. Because the query does not filter on entity, PostgreSQL cannot seek directly to the relevant portion of the index. Instead it has to scan a larger range of index entries—increasing disk I/O and node costs—and apply the dbms and org_id filters as it scans.
We still needed to keep the unique index and its columns to ensure that each entry in recommendations remained unique. To optimize for our query pattern, we added a second, targeted index:
CREATE INDEX idx_recommendations_org_dbms
ON recommendations (org_id, dbms);
Using this targeted index, PostgreSQL is able to directly seek rows by org_id, followed by dbms. After adding the targeted index, we reduced the node cost of our index scan to 104.9 from its previous cost of 317,000.
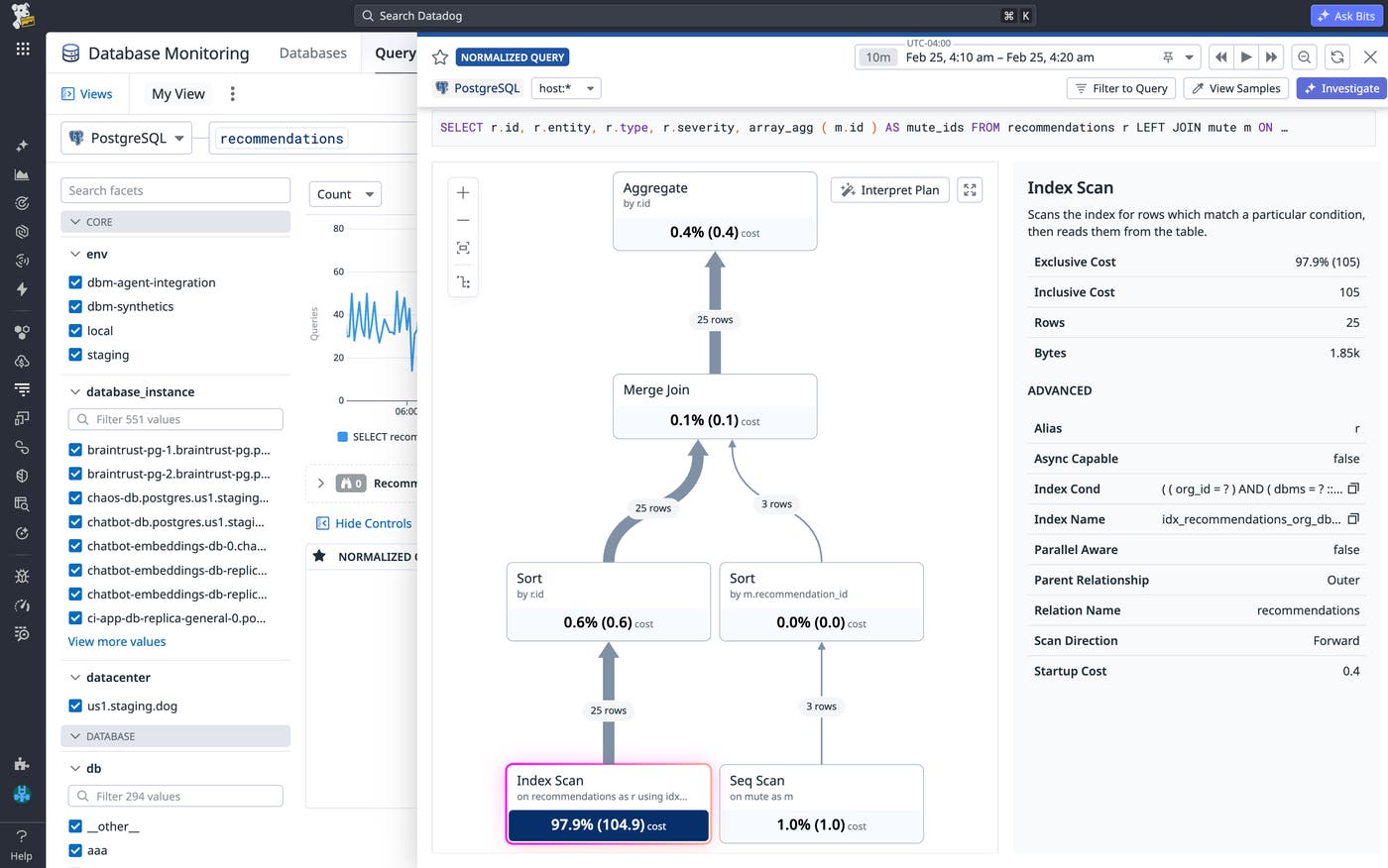
While node costs are relative, we can see how this affects the real-time performance of our database by viewing its runtime. Prior to creating the targeted index, the average latency for our query exceeded 300 ms. After applying the index, our average query latency decreased to 38 μs. Even though both execution plans used index scans, we were able to decrease latency by over 99% simply by ensuring that our indexes were aligned with the query’s predicates.
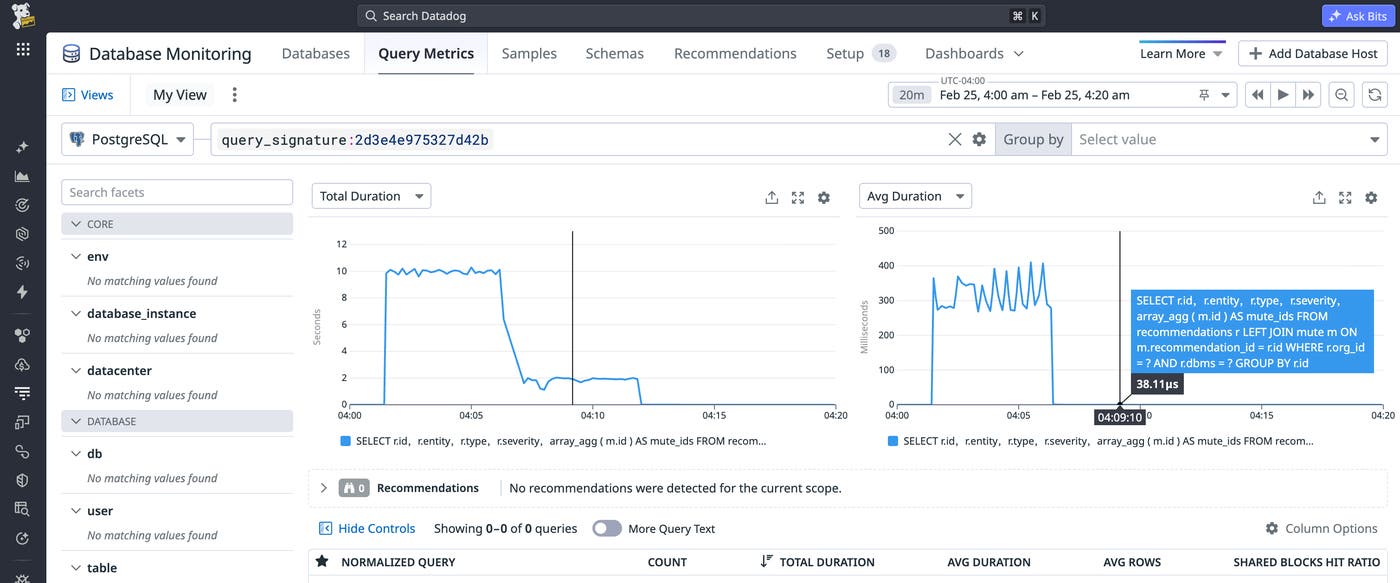
When investigating query performance in your databases, you can use the following checklist:
Identify your query’s most selective WHERE predicates.
Confirm that existing composite indexes start with these predicates.
Check for a large mismatch between rows returned and the plan’s node cost.
Create a targeted index to match predicate column order.
Use DBM metrics to validate changes in costs and runtime.
DBM Recommendations analyze these metrics and data to surface high-priority issues within your database instances and queries. We’ve expanded our recommendations to automatically detect suboptimal index scans similar to the pattern covered in this blog, enabling customers to surface and remediate these issues without manual investigation.
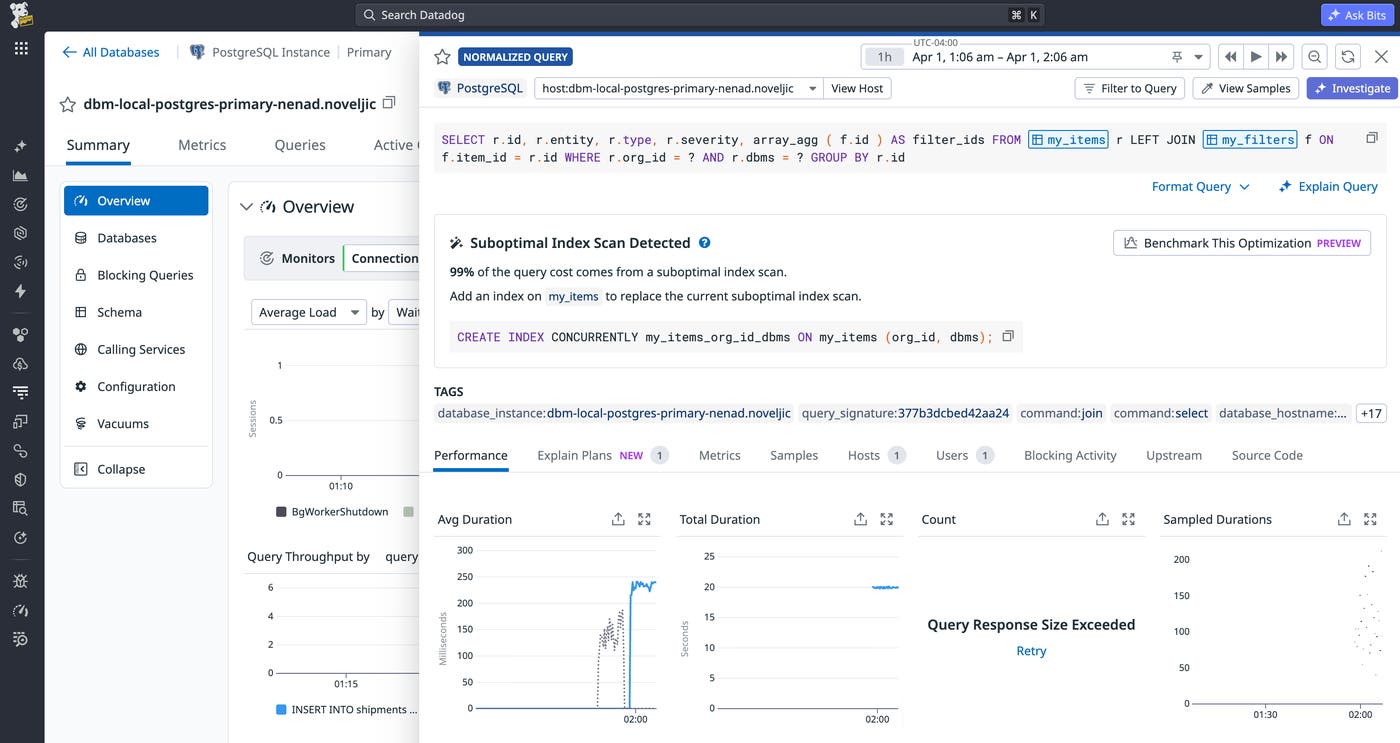
Recommendations is an included feature for all DBM customers. To see how you can use Datadog to detect and fix suboptimal index scans in your databases, sign up for a free 14-day trial today.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。