For many organizations, ServiceNow operates as the system of record for governance, auditability, and compliance. But when incidents occur, engineers often need to consult external tools to identify and resolve the root cause. When investigations are siloed from the system of record, engineers must return to ServiceNow to manually update work notes, incident statuses, and mandatory resolution fields before closing tickets.
Datadog’s bidirectional integration with ServiceNow addresses this context switching. Engineers can investigate in Datadog while updates sync automatically between the platforms, keeping ServiceNow records complete and accurate. ServiceNow remains your system of record while Datadog becomes your system of resolution. Datadog uses AI and automation at every stage of the incident response life cycle to help engineers investigate, resolve issues efficiently, and learn from past incidents to prevent recurrence.
In this post, we’ll discuss how Datadog’s ServiceNow integration and incident management capabilities help reduce context switching and mean time to resolution (MTTR) by providing:
Automatic event correlation and paging with full context
Real-time investigation, collaboration, and automated remediation
AI-generated postmortems and telemetry-focused incident analytics
Most incidents start as scattered signals, such as spikes in error rates, slow queries, or alerts triggering from different parts of the stack. Datadog Event Management detects these seemingly disparate signals and uses pattern-based and intelligent correlation to identify their connection to the same underlying issue. Datadog aggregates the signals and groups them into a single case, which prompts the integration to create a corresponding ServiceNow record. With the signals consolidated into a case, you can thoroughly understand how a failure is propagating across your services.
In the screenshot below, Event Management identifies four alerts that triggered as a result of a payment service issue. After consolidating them into a case, Event Management evaluated the impact against the user’s defined criteria and assigned the priority to P1, meaning “Critical.” A ServiceNow record has been automatically created and linked. The ServiceNow record will sync bidirectionally as engineers update case details, so support teams can communicate status and impact without needing to replicate the investigative work.
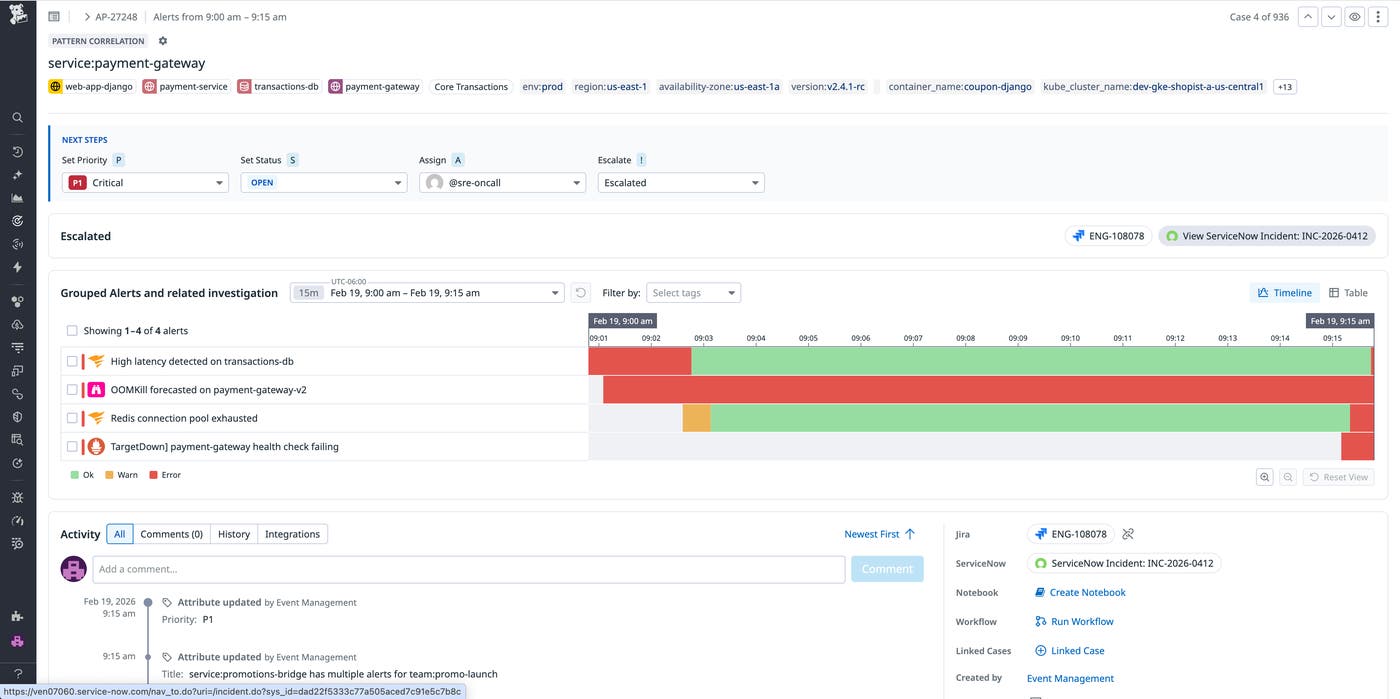
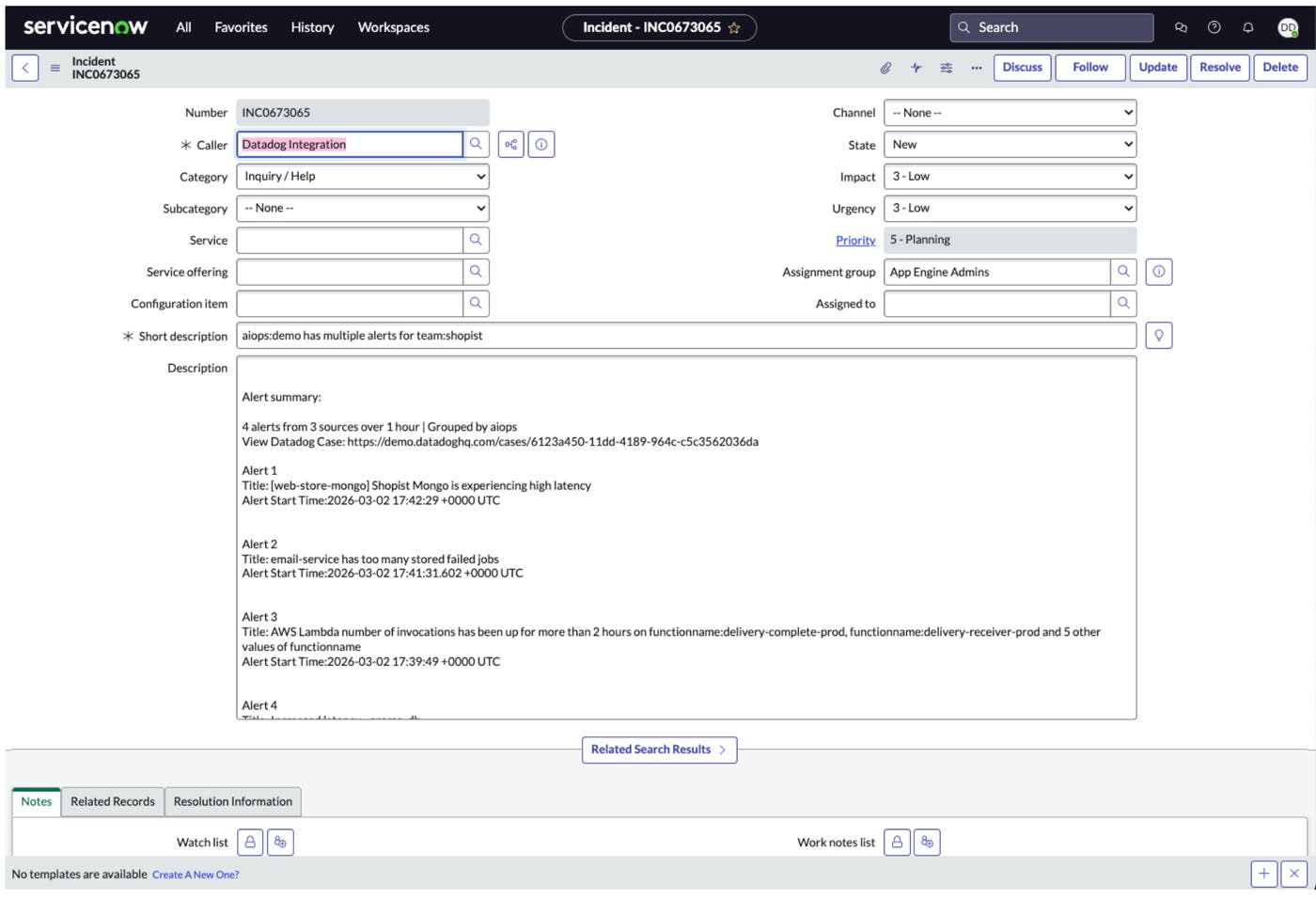
The next screenshot shows a ServiceNow record created in response to a Datadog case. The Caller field identifies the creator as Datadog Integration, confirming that no manual intervention was required. The description field is pre-populated with an alert summary that includes the total number of alerts grouped, a link to the corresponding Datadog case, and the title and start time of each individual alert.
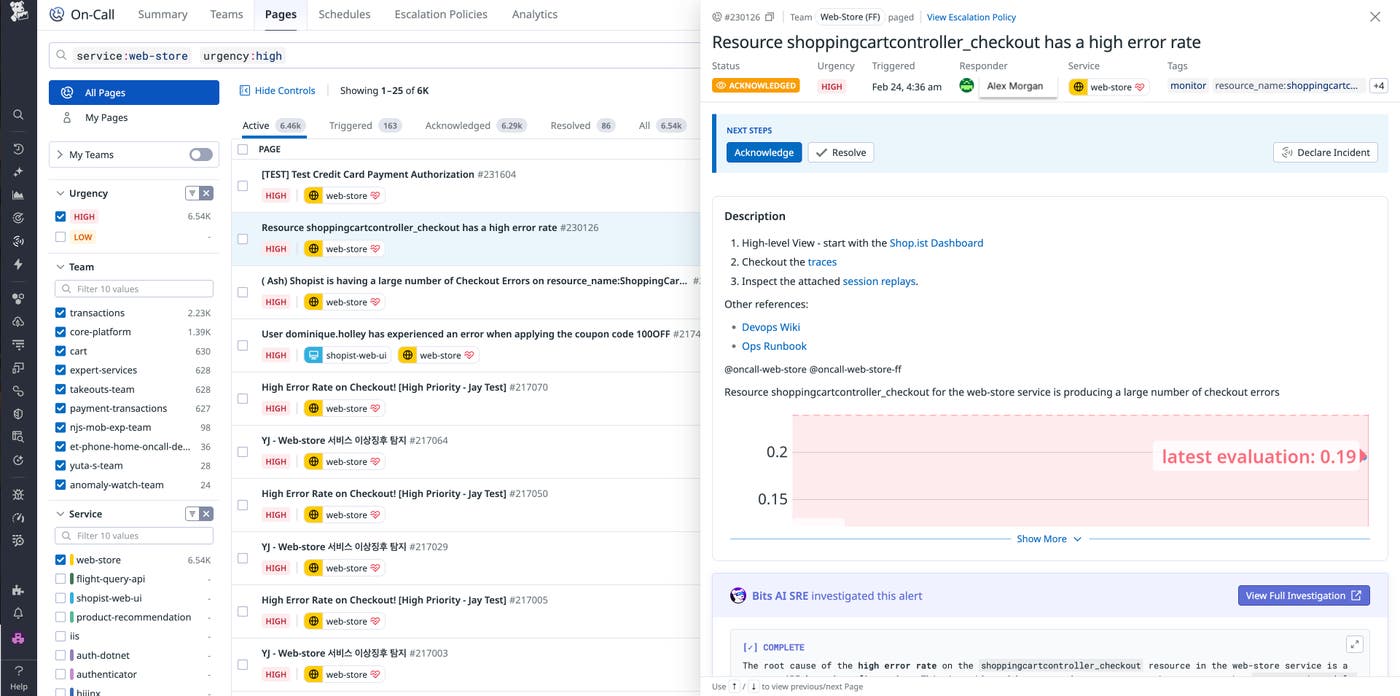
When a case crosses your defined priority threshold, Datadog On-Call triggers a page via push notification. On-Call notifications conveniently include context for the correlated case, specifying which services are affected, the team that owns the impacted system, and related observability data, such as logs and traces. To keep service ownership information accurate, Datadog’s Software Catalog syncs with ServiceNow CMDB service metadata.
The screenshot below displays a Datadog On-Call page that was triggered by a high error rate in the ecommerce checkout process. The page includes the alert description, links to relevant runbooks, and a live metric graph showing the latest evaluation. Bits AI SRE has automatically investigated the alert, identified a root cause, and provided an option to view the full investigation.
If an issue escalates, on-call engineers can declare an incident. Engineers can declare an incident from multiple locations, including cases, the On-Call page, or directly from alerts on their mobile devices.
Just like with cases, a ServiceNow record is automatically created when you declare an incident in Datadog. An incident includes a centralized workspace with a live timeline, the runbook for the affected service, and the response team’s contact information. Throughout the incident response life cycle, Bits AI SRE synthesizes investigation information, identifies potential root causes, and recommends strategies for remediation. With these resources on hand, engineers know what steps to take to coordinate and execute their response, eliminating the need to search for documentation or dashboards.
If your team uses Slack or Microsoft Teams, engineers can update incident severity, page on-call responders, and push messages to the incident timeline using commands or AI prompts, keeping the investigation moving without switching to the Datadog UI. The following screenshot shows a Datadog incident that includes links to the dedicated Slack channel and the corresponding ServiceNow record.
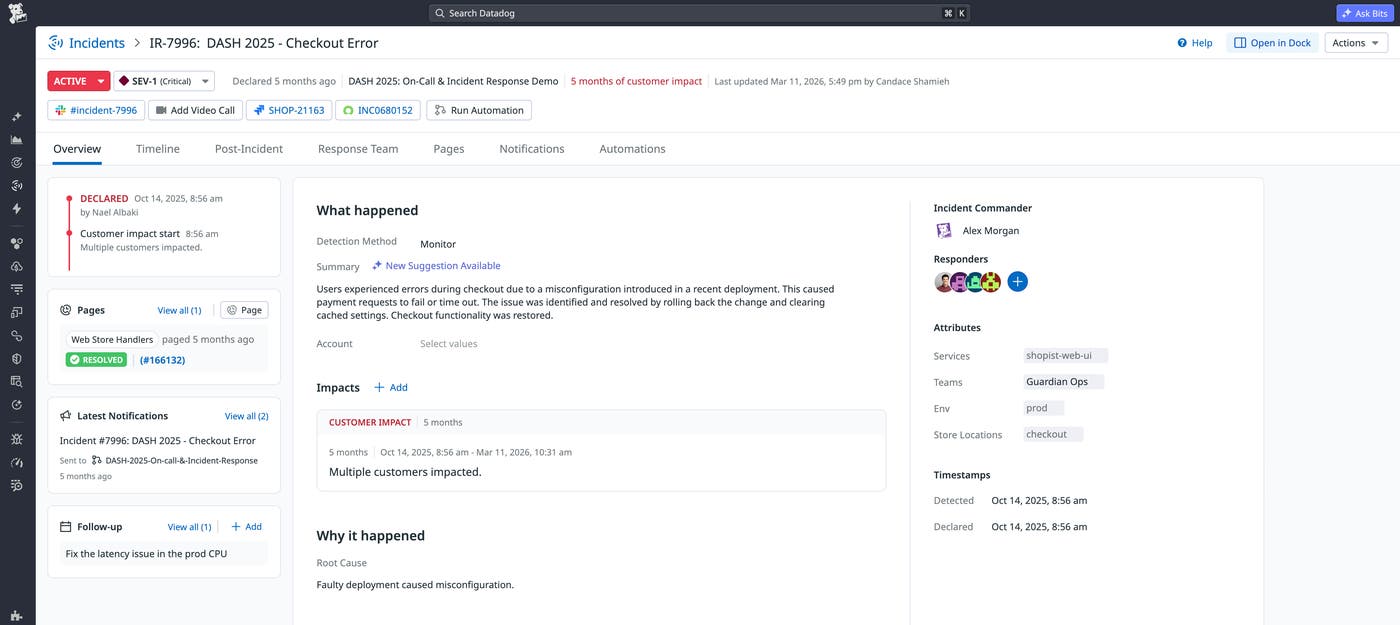
As the investigation progresses, impact, urgency, and state will sync bidirectionally between Datadog and ServiceNow. Real-time syncing lets business stakeholders track progress in ServiceNow without interrupting engineers for status updates. For incidents with external impact, Datadog Status Pages enables teams to publish real-time updates to internal and public stakeholders directly from the incident. Up-to-date information about the incident means customers are aware of the ongoing outage, and customer-facing teams can respond to inquiries without pulling engineers away from the investigation.
To help engineers execute the fix, Datadog Workflow Automation can perform remediation steps, including rolling back a deployment, restarting a Kubernetes pod, scaling infrastructure, or toggling a feature flag. Workflows trigger based on your team’s defined criteria, effectively minimizing the amount of manual steps between diagnosis and resolution. Workflows can also trigger custom AI agents to perform nondeterministic tasks—like analyzing logs, traces, and Real User Monitoring (RUM) data—then compile and post structured findings in Slack.
The screenshot below shows a GitHub Actions workflow that can be executed during an incident. Workflow Automation restarts the service, notifies the team via Slack, and updates the incident severity.
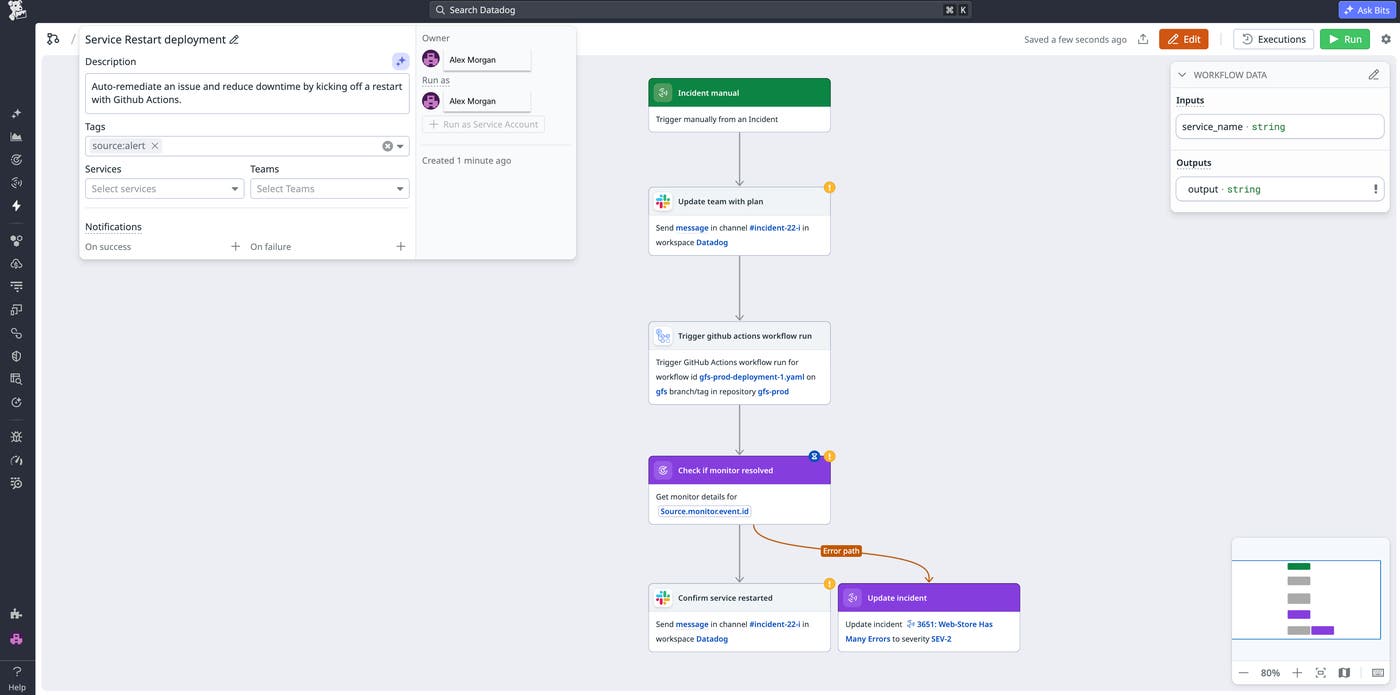
Once you resolve the incident, Datadog automatically updates the resolution state, resolution code, and resolution notes in the ServiceNow record, creating a verified audit trail to support your compliance requirements. If you’ve defined any follow-up tasks from your incident, exporting them to a Datadog case triggers a sync to ServiceNow.
Major incidents usually require completing a ServiceNow problem record to document the root cause, contributing factors, and steps to prevent recurrence. Datadog uses AI to automatically generate this information for you in a postmortem. Postmortems are structured documents that include an incident summary, root cause analysis, customer impact assessment, and defined next steps. Once you resolve the incident, the AI-generated postmortem can populate in Datadog Notebooks, Confluence, or Google Docs. Since the postmortem pulls data directly from the incident timeline, it is nearly complete. Engineers only need to review and refine it before presenting to leadership or customers.
Because every event related to an incident is logged, teams can analyze data across incidents to track key metrics, including MTTR and customer impact duration. The following screenshot shows our preconfigured Incident Management Overview dashboard.
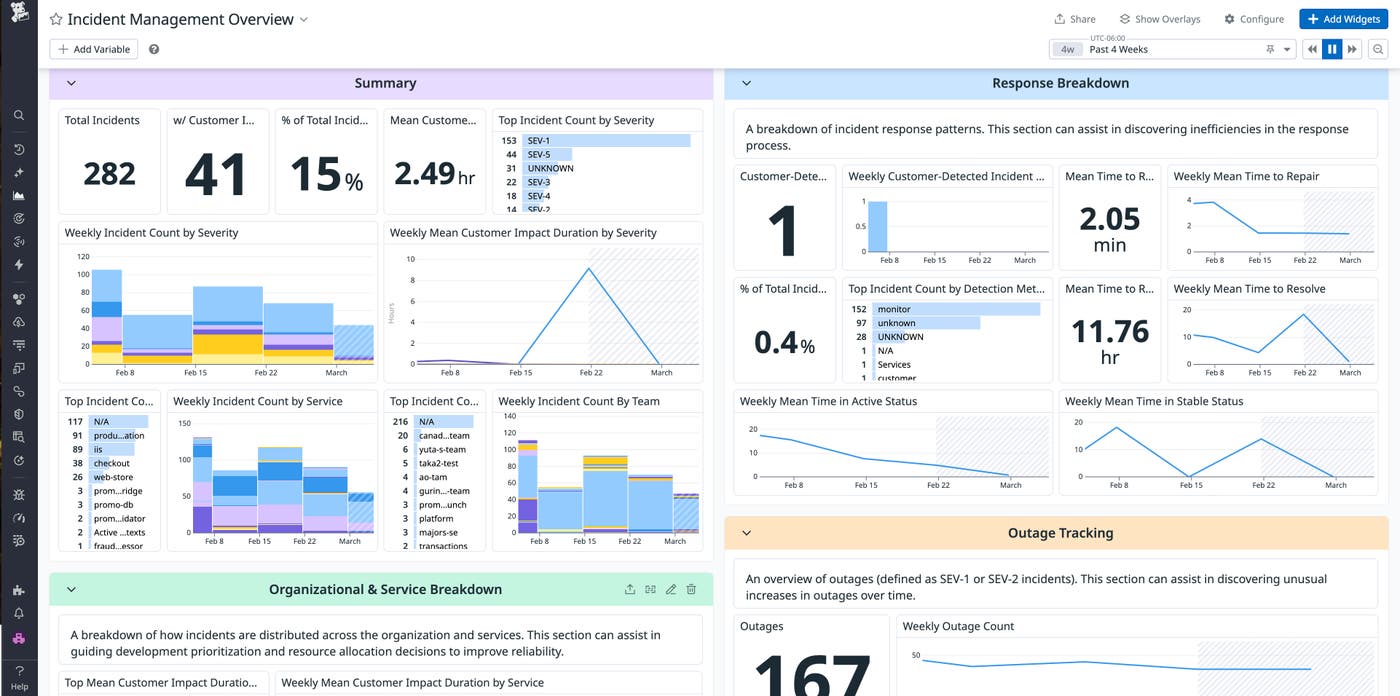
Teams can filter and categorize incident data by service, severity, or custom properties to identify systemic weaknesses and prioritize reliability investments. With access to organization-wide and On-Call analytics, you can discover opportunities for improvement.
Using ServiceNow as the system of record and Datadog as the system of resolution creates an operating model that balances governance and velocity. Datadog’s bidirectional integration with ServiceNow lowers administrative overhead for both engineers and support teams, keeping stakeholders up to date as they monitor accountability and compliance. Datadog’s incident response capabilities give engineers access to the tools and telemetry data they need to resolve issues quickly, reducing MTTR and minimizing downtime.
If you’re already using Datadog, configure the ServiceNow integration to start syncing data between the platforms. To learn more, visit the ServiceNow integration documentation and the Datadog Incident Management documentation. If you’re new to Datadog, get started with a 14-day free trial.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。