This article is part of our series on how Datadog’s engineering teams use LLM Observability to build, monitor, and improve AI-powered systems.
Organizations are building AI agents that help users automate work, analyze data, and interact with complex systems through natural language. As these agents become more capable, they also become more complex and exposed to risks such as prompt injection, data leaks, and unsafe code execution.
To mitigate these risks, our Security team built AI Guard, a new application that detects and blocks unsafe model behavior from applications in real time. It serves as an in-line guardrail, analyzing every prompt, model output, and tool call to identify potentially harmful actions before they occur.
In this post, we’ll show how our Security team uses Datadog LLM Observability to evaluate, iterate on, and monitor AI Guard. Traces capture every model decision in context, while Experiments let us measure the impact of changes to models, prompts, and rules on statistically valid datasets. This enables fast, confident production updates within a consistent framework for strengthening AI Guard’s detection logic.
AI Guard secures Datadog’s Bits AI Agents, which can autonomously investigate alerts, suggest code fixes, and review security signals by monitoring the full life cycle of each request, from user prompt to model response and tool execution. Its purpose is to detect and block unsafe behavior before it reaches downstream systems.
If a prompt tries to steal credentials or run code in an unsafe environment, AI Guard blocks it. To tell the difference between normal and malicious behavior, we built detection models trained on real examples and tested AI Guard through consistent, repeatable evaluations.
We built a dataset that combines simulated and real agent activity to train and test AI Guard’s models. By including simulated activity and production traffic, we captured edge cases and avoided overfitting to ensure we had high confidence in any experiment results.
Simulated attacks provided scale, and security engineers developed red-team scenarios that reproduced prompt injection, indirect data leaks, and unsafe tool execution. Real traffic samples captured realism: Using LLM Observability, engineers used anonymized traces generated from internal Datadog Agents to surface edge cases that scripted attacks missed.
Each conversation was labeled as safe or unsafe, with annotations for false positives and false negatives. This dataset became the foundation for automated evaluation experiments.
Every agent we test is fully instrumented with LLM Observability and produces detailed traces that include:
User and system prompts
Model reasoning steps and completions
Tool inputs and outputs, along with latency and token usage
During development, we used agentless scanning, which required only an API key and environment variable for setup. In production, we enabled the Datadog Agent to collect LLM traces alongside APM, logs, and infrastructure telemetry data, giving us unified visibility into both model behavior and system performance. The same traces used for debugging also populate our evaluation datasets, keeping testing aligned with real production conditions.
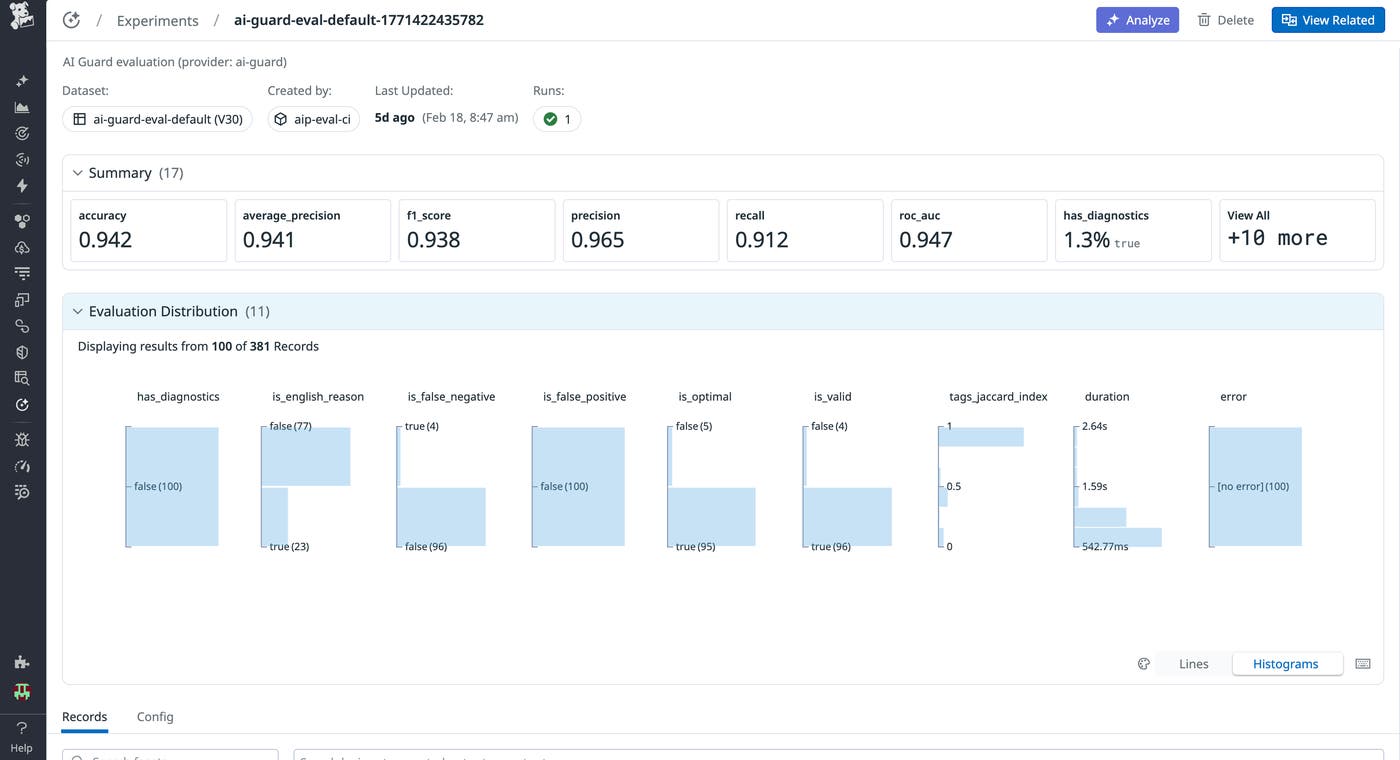
With instrumentation in place, we used LLM Observability Experiments to measure AI Guard’s accuracy and performance. Each time a developer updated a rule, classifier, or prompt, we recorded it as a new application version. Then, we ran these versions through structured experiments to see how they performed against our simulated and real datasets. This allowed us to benchmark performance and measure whether these configuration changes impacted our operational performance metrics and semantic evaluation results, bringing us closer to our ideal application behavior.
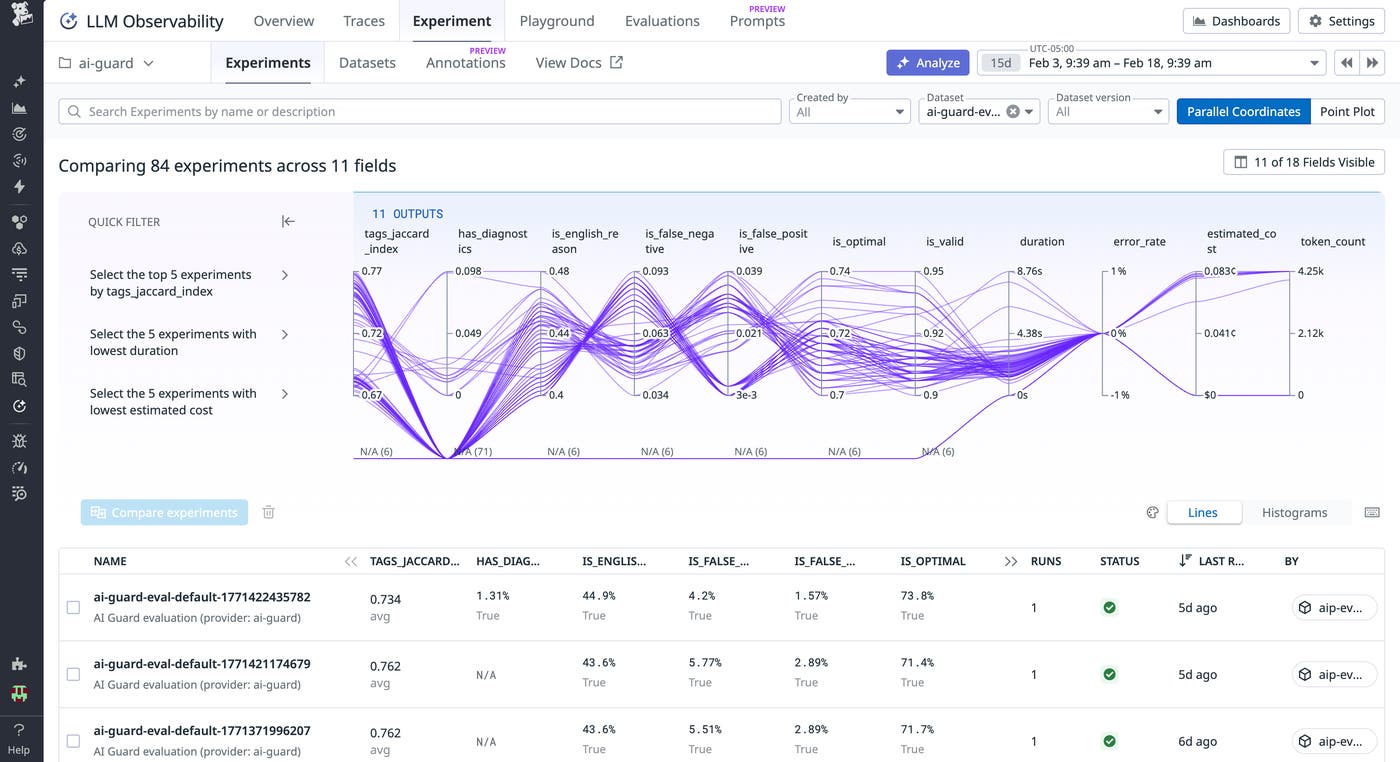
Each run measured:
Accuracy, precision, recall, and F1 score
Latency and token cost per evaluation
Differences between the previous and new versions
Results appeared as Experiment diffs with direct links to the affected traces. In one example, a math-help query was incorrectly flagged as unsafe. Reviewing the trace revealed that fenced Python code in the model’s explanation was being misclassified as a code injection attempt. Adjusting the classifier’s weighting corrected the issue without affecting recall.
Evaluation is integrated directly into development. When a developer modifies a rule, model, or prompt:
Experiments benchmark the change automatically.
A link to the experiment diff appears in the pull request.
Engineers review results and inspect regressions directly from the LLM Experiments result.
This workflow ensures every change is measurable, reviewed, and reproducible before deployment.
AI Guard currently runs on commercial OpenAI models as well as custom self-hosted models on Datadog infrastructure. We also continue to evaluate Anthropic Claude and Google Gemini commercial models for benchmarking within the same evaluation pipeline. This allows us to compare performance, accuracy, and latency across providers without changing the underlying observability or evaluation logic. We also used Datadog’s cost analytics to refine evaluation frequency and model selection.
We’re preparing support for frameworks such as LangChain, Pydantic AI, and Mastra through the same instrumentation. LLM Observability enables this consistency by standardizing how model behavior and evaluation data are collected.
In production, our Bits AI Agents send requests through Datadog’s AI gateway, our internal routing layer used by every AI application and agent at Datadog. Each request triggers a synchronous evaluation from AI Guard, and the full input–output pair is captured as an LLM span in LLM Observability. Because these spans correlate automatically with APM and log telemetry data, we can move directly from an LLM request to the related service and infrastructure signals.
We also maintain a set of continuous evaluations to detect issues such as prompt injections, hallucinations, or failures to answer. When anomalies appear, their traces are exported and added to the evaluation dataset, ensuring that new insights directly inform model improvements.
LLM Observability has reshaped how we build and maintain AI Guard. Regression detection runs automatically through Experiments, and debugging is faster, with trace-level visibility reducing investigation time from days to minutes. Collaboration also improved through shared experiment links in pull requests and Slack, while efficiency increased from our use of built-in Datadog tooling instead of custom scripts. We saved more than a month of initial development time and continue to see efficiency gains as AI Guard evolves.
For our Security team, AI Guard demonstrates how observability, evaluation, and security can reinforce one another to protect AI systems in production. Across Datadog, LLM Observability has become central to how teams measure, test, and improve AI reliability.
If you’re curious to try this new AI guardrail application for your AI apps and agents, you can join the Preview. And if you’re new to Datadog, get started with a 14-day free trial.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。