
The Chips Got Faster. The Stack Didn't.
Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
All


Model fine-tuning is the process of adapting a pre-trained machine learning model to perform better on a specific task or dataset. This technique allows for improved performance and efficiency compared to training a model from scratch, as it leverages the knowledge already learned by the model.
Fine-tuning is ideal when you have limited data but want to enhance model performance. It is beneficial when the task differs significantly from the original training task of the model.
Fine-tuning is a subset of transfer learning, using knowledge an existing model already has as the starting point for learning new tasks. It’s easier and cheaper to hone an existing model’s capabilities rather than train a new model from scratch. For example, you can fine-tune an existing Large Language Model (LLM) to adjust its tone when responding to inquiries, or give it knowledge specific to your domain or business.
In this blog post you’ll learn how to:
You can fine-tune a model on Runpod using Axolotl, an open-source tool for fine-tuning AI models. Let’s deploy a pod that will fine-tune a model based on a dataset, and then run that model so we can test how it has changed.
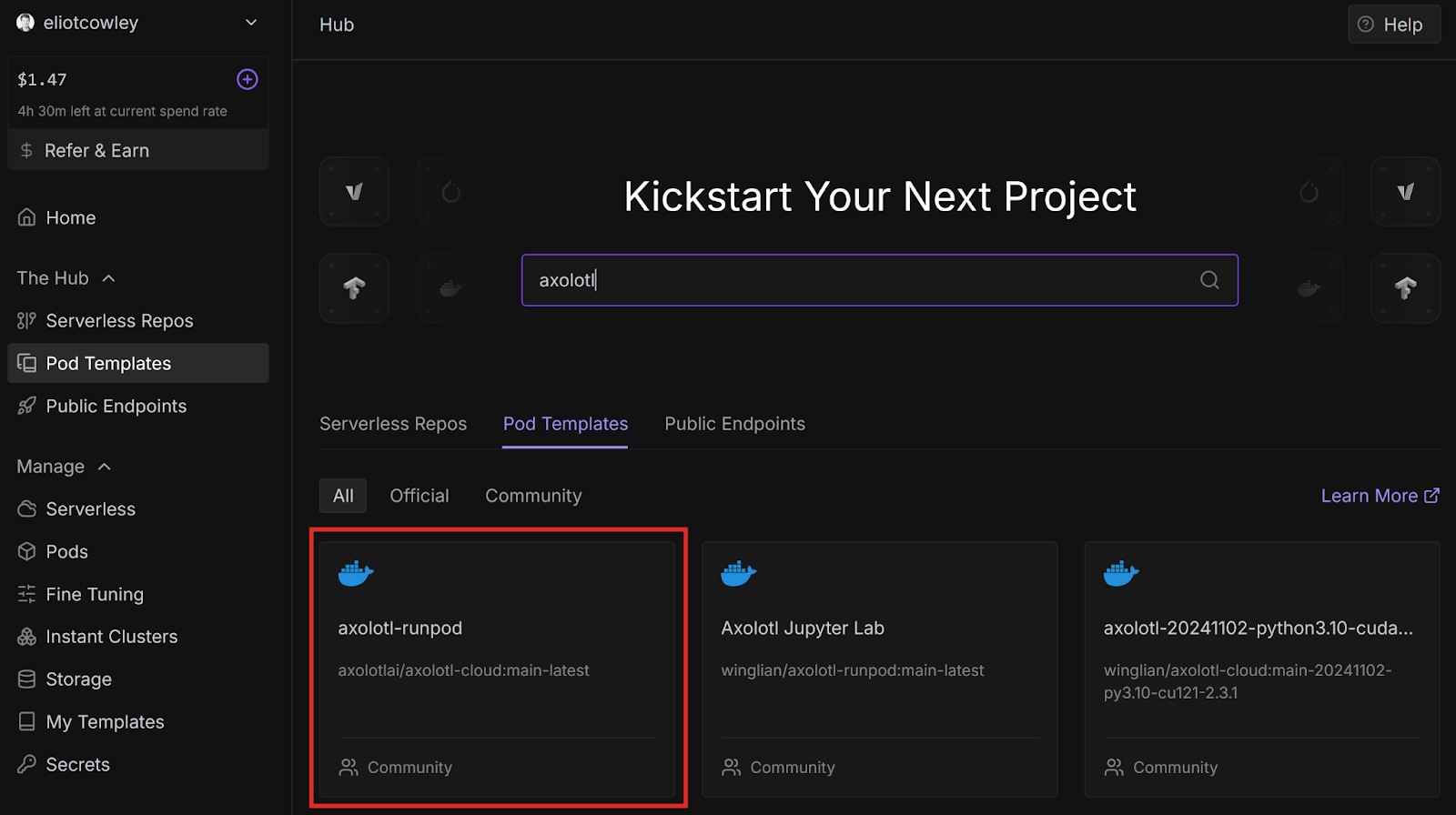

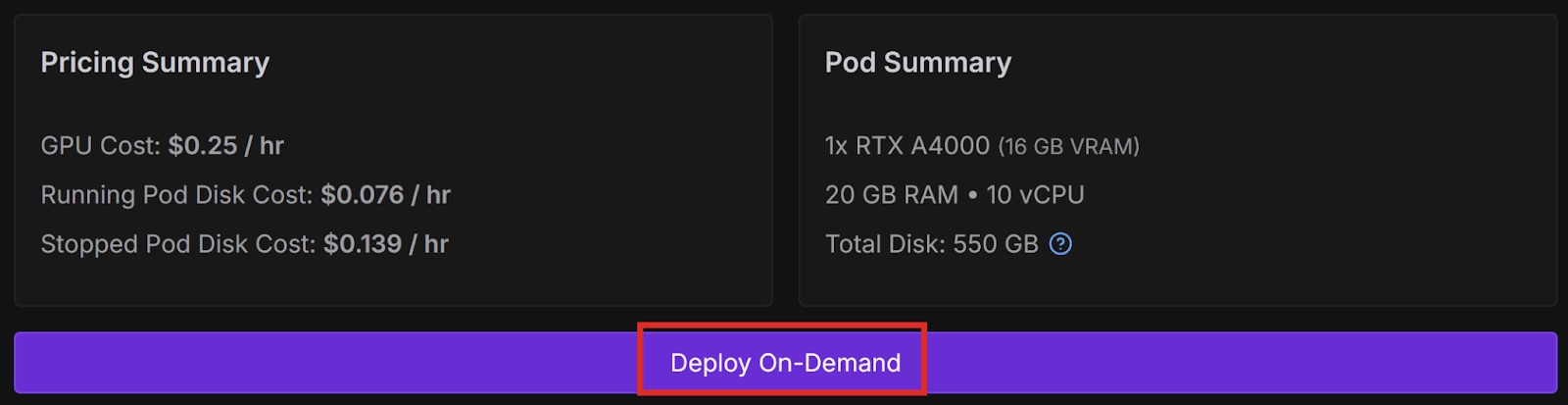

Now that we have a pod that has Axolotl up and running, let’s access the pod from a terminal on our local machine and see the files and directories in our workspace.

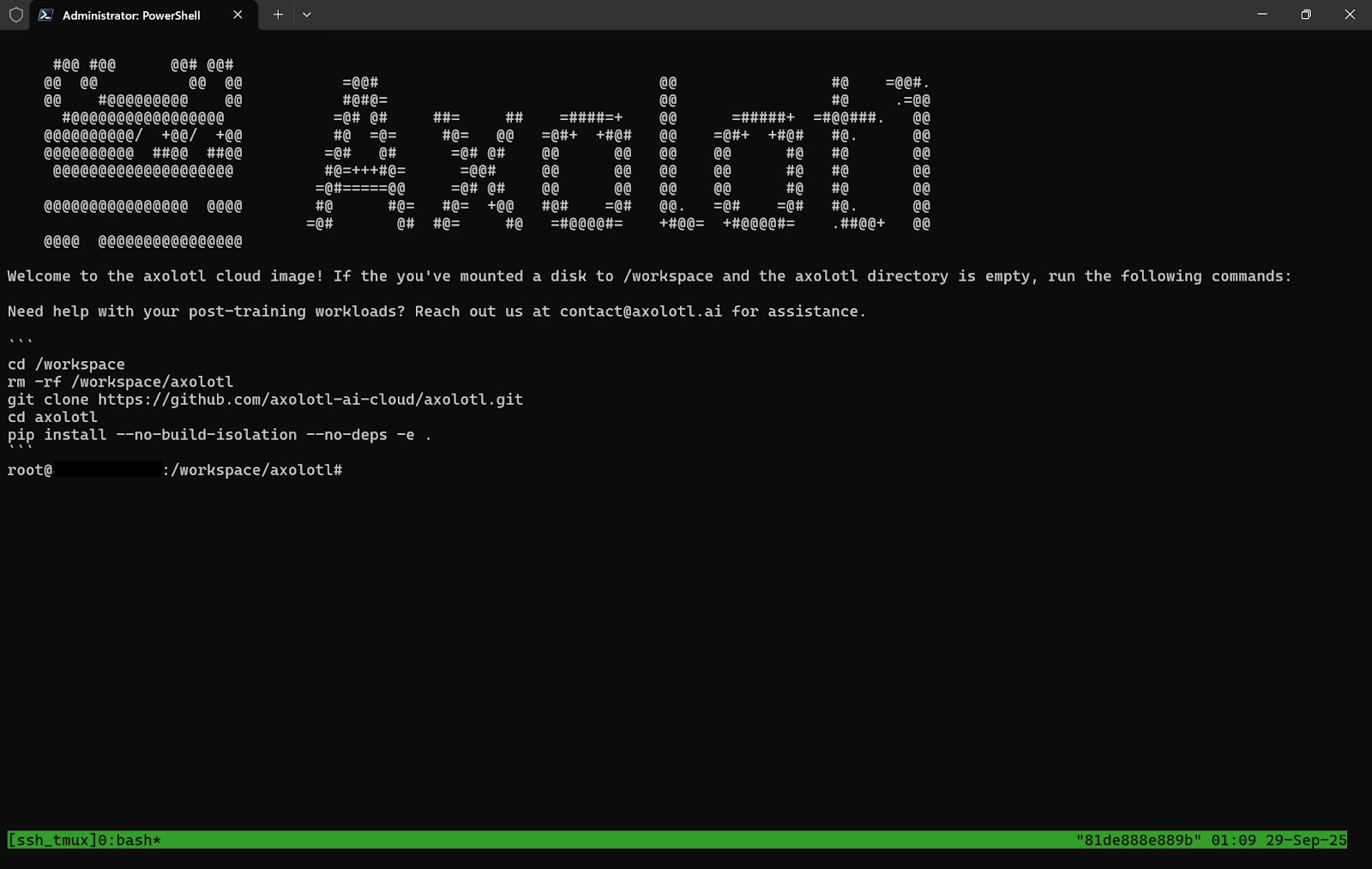



LoRA, which stands for Low-Rank Adaptation, is a technique used in fine-tuning that adapts models to new contexts in an efficient and performant way without requiring full retraining of the model. It will speed up our fine-tuning and be less costly than full retraining. The 1b in the filename means that the model has one billion parameters.
nano lora-1b.yml
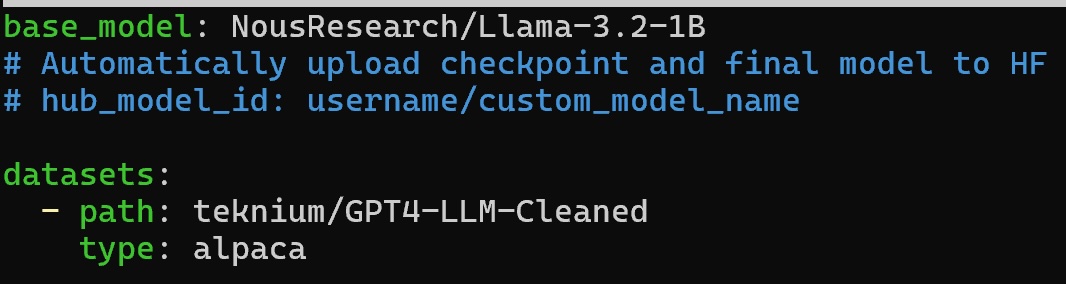
The model we will fine-tune is NousResearch/Llama-3.2-1B, a Llama 3.2 text model with one billion parameters that even lower-end hardware can run.
We will train it on the teknium/GPT4-LLM-Cleaned dataset, a GPT-4 LLM instruction dataset with OpenAI disclaimers and refusals filtered out.
Press Ctrl+X (Cmd+X on Mac) to exit the Nano text editor.
Okay, we familiarized ourselves with the pod’s workspace and chose a configuration file. Now let’s go ahead and fine-tune our model!
cd /workspace/axolotl to navigate back to the starting directory so that our model is saved in the correct place. Now enter the following command:axolotl train examples/llama-3/lora-1b.yml
Training completed! Saving trained model to ./outputs/lora-out.
axolotl inference examples/llama-3/lora-1b.yml
--lora-model-dir="./outputs/lora-out" --gradio
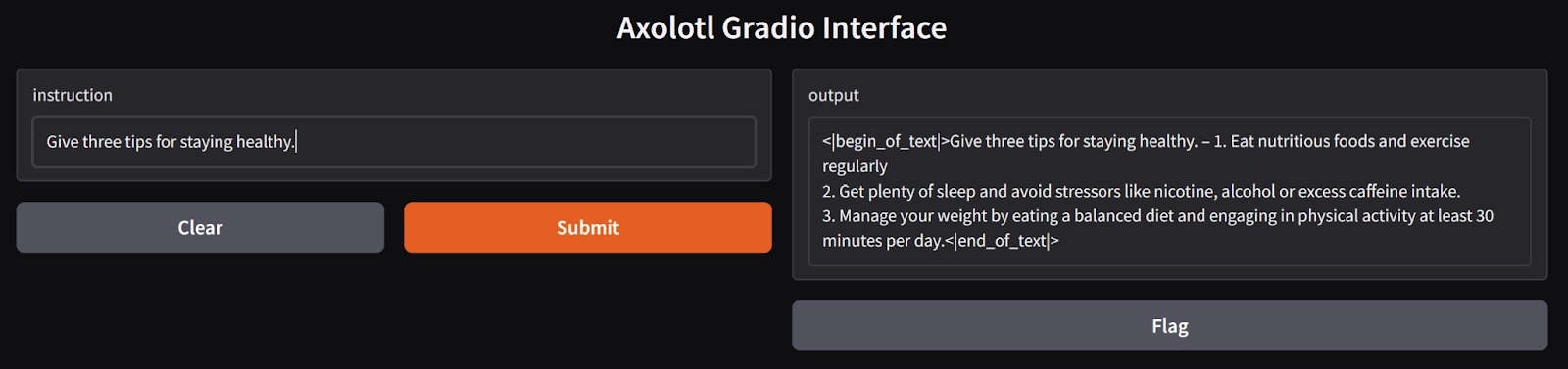
Give three tips for staying healthy.
1. Eat nutritious foods and exercise regularly
2. Get plenty of sleep and avoid stressors like nicotine, alcohol or excess caffeine intake.
3. Manage your weight by eating a balanced diet and engaging in physical activity at least 30 minutes per day.
Whereas the expected output from the dataset is:
1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases. It’s close, but not quite the same. This is one of the drawbacks of using LoRA - lower precision. But still pretty good!
2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week.
3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night.
Congratulations, you’ve fine-tuned a model based on a dataset! Runpod and Axolotl enable you to take existing models and adapt them to new contexts, without requiring you to create your own model from scratch. Here are some things you can do to take this further:
Note: When you’re done with your pod, don’t forget to terminate it, otherwise it will keep costing you money!
Author profile: Eliot Cowley
Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
All
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
All
.jpeg)
How 1,100 researchers beat OpenAI's own baseline with 16 megabytes and 10 minutes.
All
Build, train, and scale AI workloads on Runpod with cloud GPUs, Serverless, and Clusters.

此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。