
The Chips Got Faster. The Stack Didn't.
Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
All


In a previous blog post, we explored Runpod Serverless, a pay-as-you-go cloud computing solution that doesn’t require managing servers to scale and maintain your applications. We deployed some basic code from templates that just printed some text to the console, but now let’s do something more performance-intensive.
ComfyUI is an open-source, node-based application for generative AI workflows. You can deploy ComfyUI as an API endpoint on Runpod Serverless, send workflows via API calls, and receive AI-generated images in response.
In this blog post you’ll learn how to:
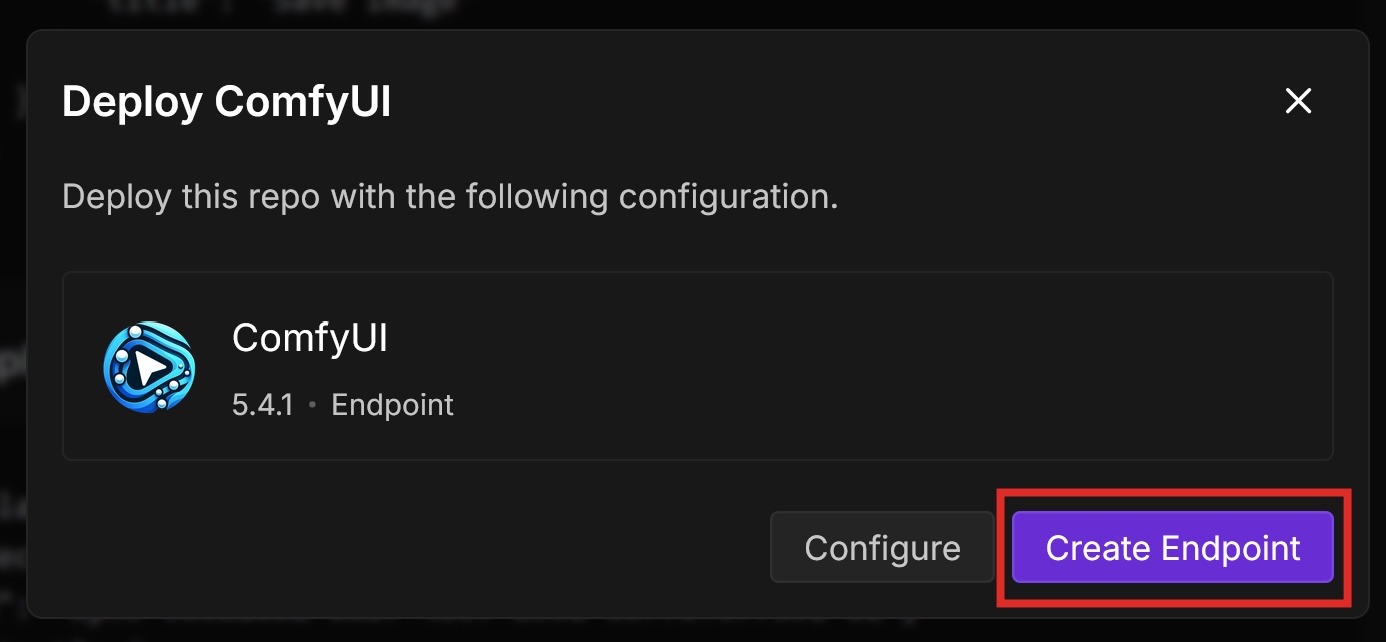
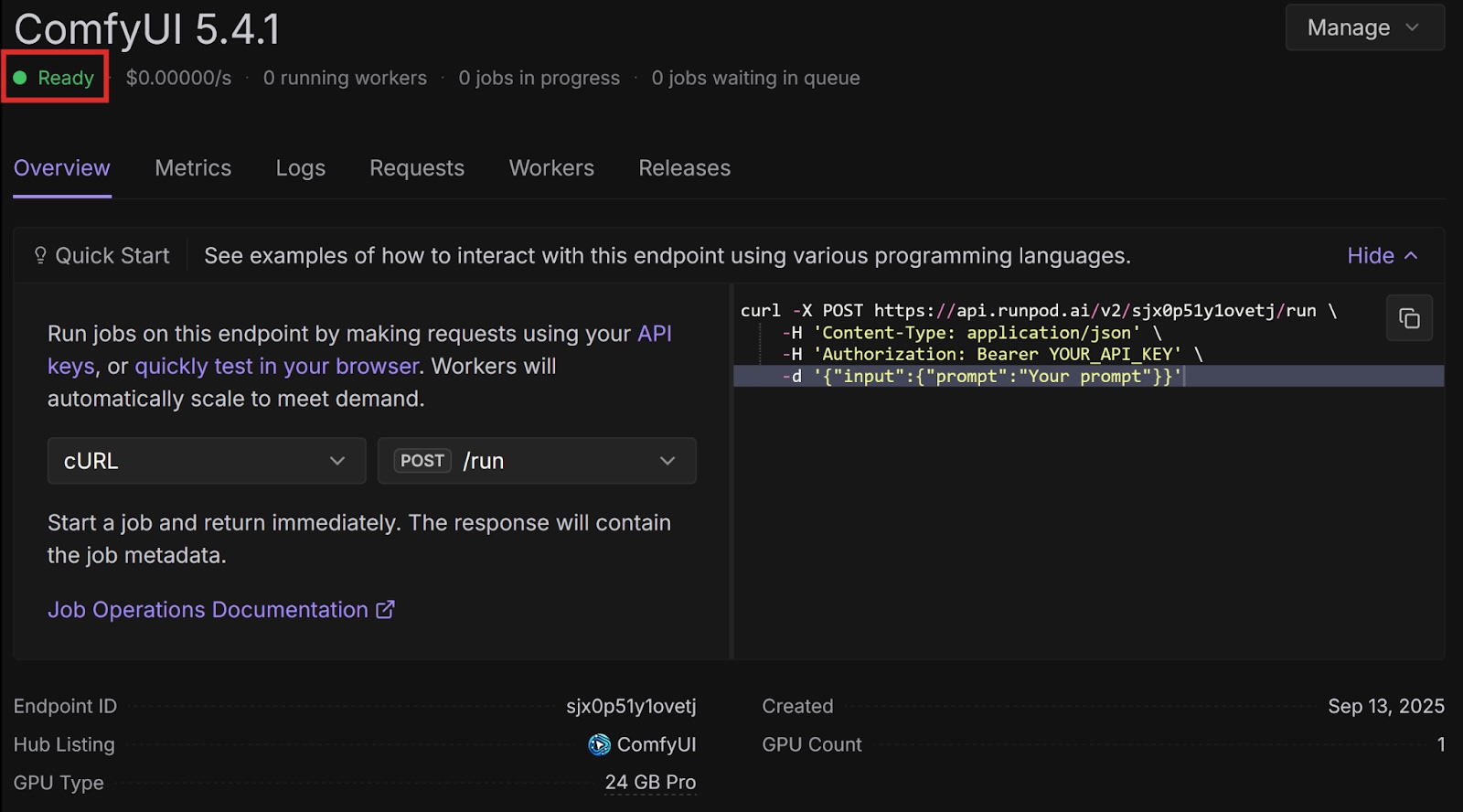
Runpod Hub provides convenient repositories that you can quickly deploy to Runpod Serverless without much setup. Let’s deploy the ComfyUI repo from Runpod Hub to a serverless endpoint, which will allow us to make requests to it from code.
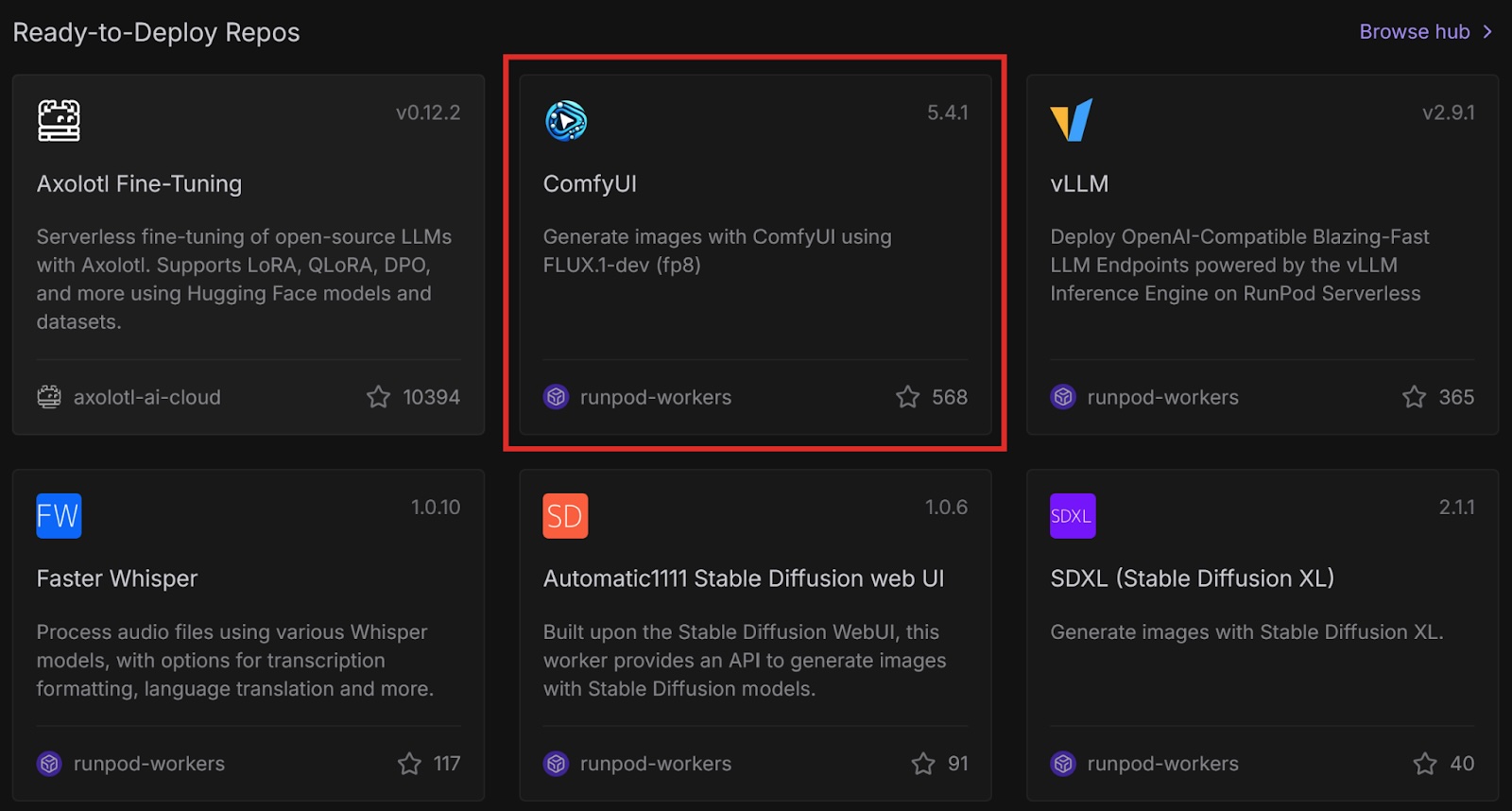
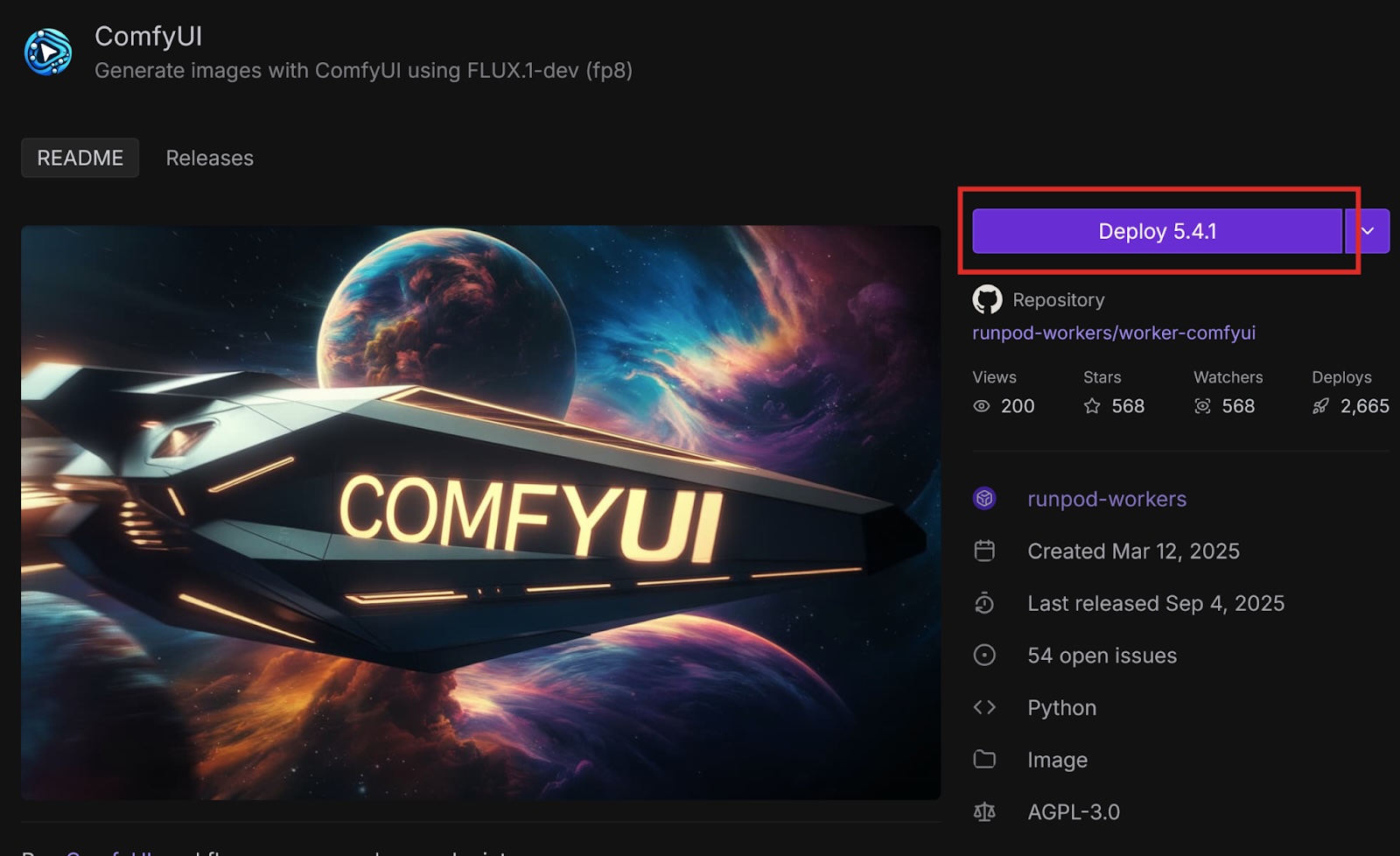
This is a ready-to-deploy template from the Runpod Hub. It uses the FLUX.1-dev-fp8 model and only works with this model. Later in this post, we will deploy this template with other models using Docker.
Requests to ComfyUI return images in the form of base-64 strings by default, so we need the base64 library to decode them.
The requests library helps us send requests to our API endpoint.
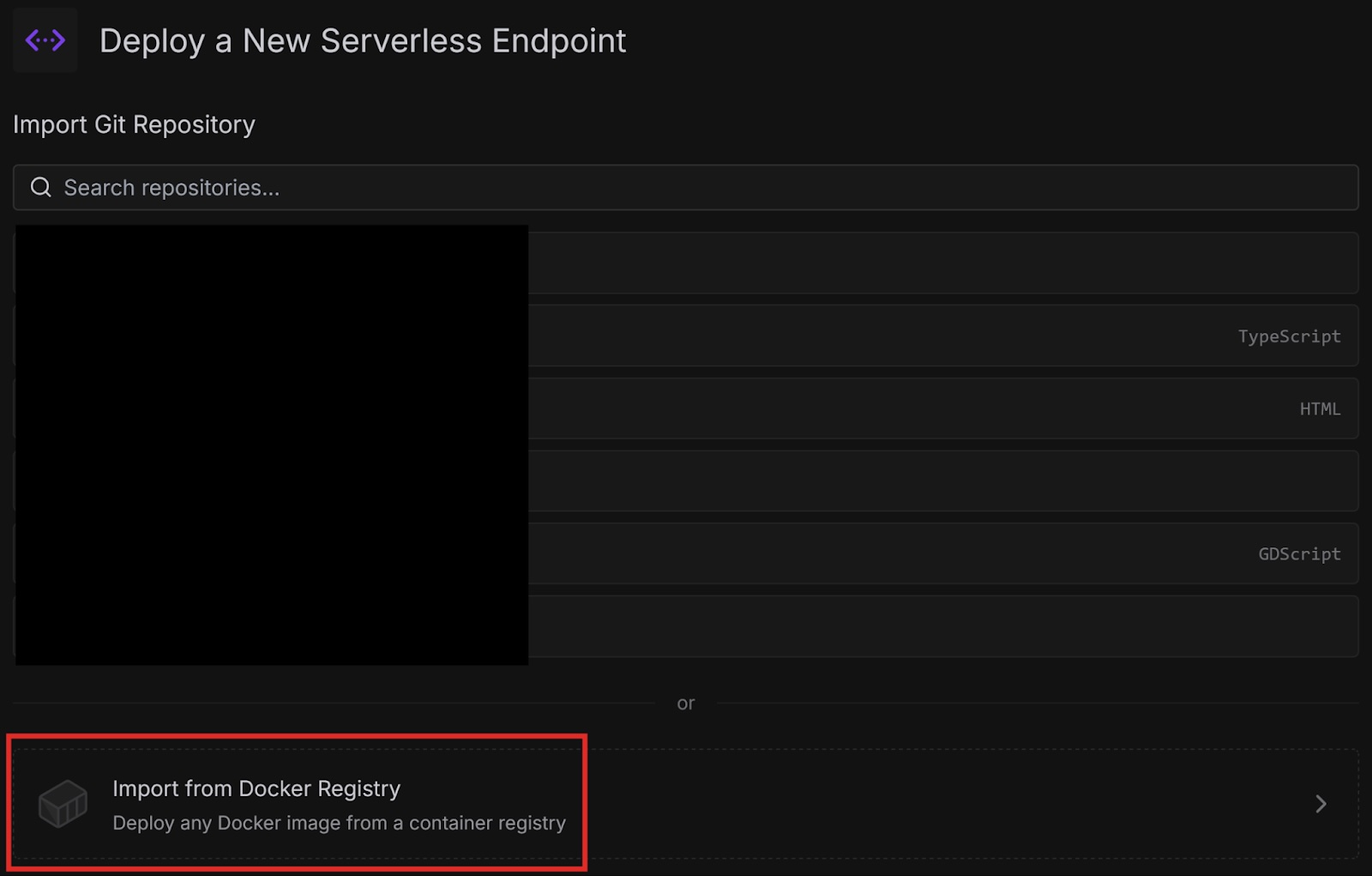
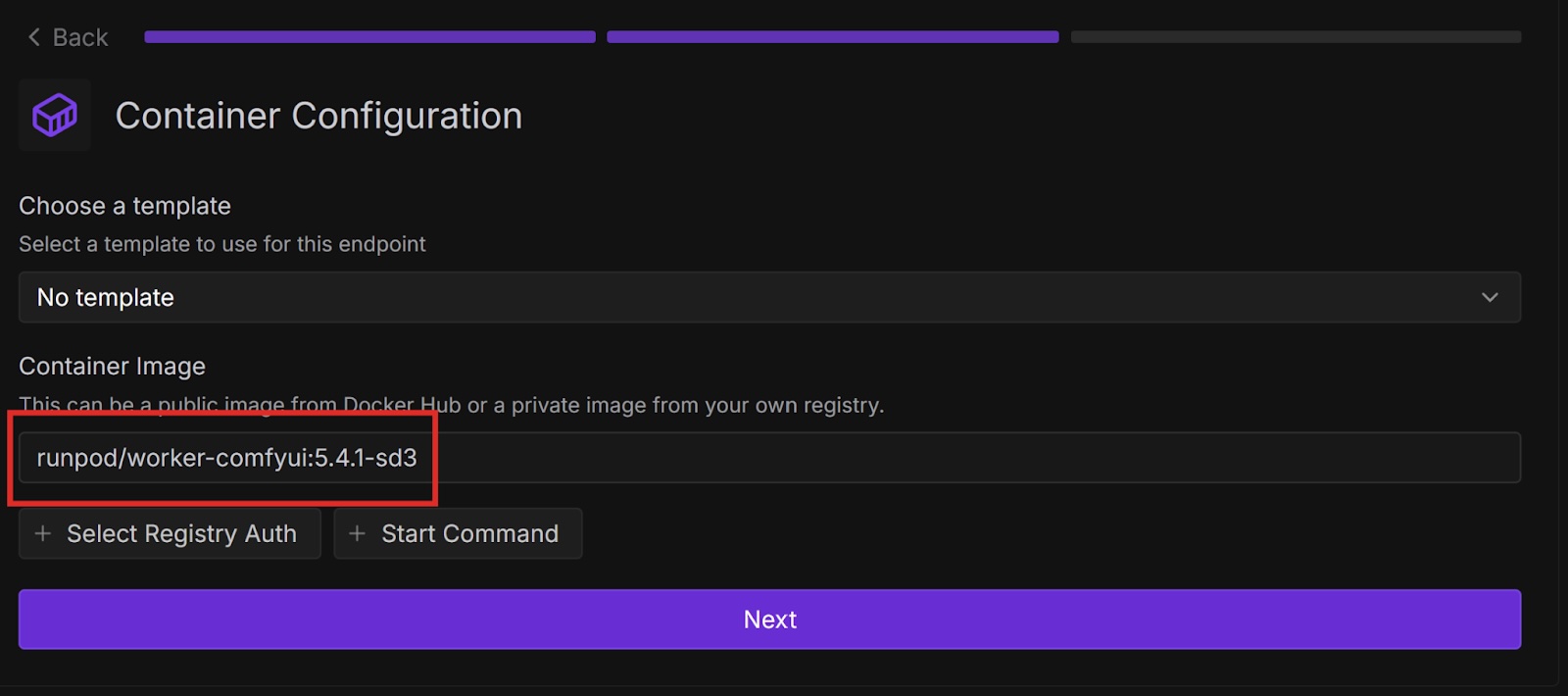
The ComfyUI template on the Runpod Hub makes it easy to deploy as a serverless endpoint, but it is restricted to the FLUX.1-dev-fp8 model. If you want to use a different model, you can use the worker-comfyui repository on GitHub.
Runpod provides official container images on Docker Hub that deploy ComfyUI with various models. In this tutorial, we will use one of these images, but if you want to use a model that Runpod does not have an image for, you can use the latest base image and supply your own model.
requests.post() call).Congratulations, you successfully deployed ComfyUI to a serverless endpoint both from a Runpod Hub repository and a Docker image! Runpod provides many ways to quickly start running common AI workloads without much setup.
Is there a particular model that you want to use with ComfyUI, but isn’t in any of Runpod’s Docker images? Try customizing your setup by creating your own Dockerfile starting from one of the base images and baking the model you want into your image. Then deploy it to Runpod either from Docker or your own GitHub repository.
Author profile: Eliot Cowley
Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
All
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
All
.jpeg)
How 1,100 researchers beat OpenAI's own baseline with 16 megabytes and 10 minutes.
All
Build, train, and scale AI workloads on Runpod with cloud GPUs, Serverless, and Clusters.

此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。