In this blog you’ll learn:
If you're not familiar, vLLM is a powerful LLM inference engine that boosts performance (up to 24x) - if you'd like to learn more about how vLLM works, check out our blog on vLLM and PagedAttention.
When deciding between a closed source LLM like OpenAI's ChatGPT API and a open source LLM like Meta’s Llama-7b, it's crucial to consider cost efficiency, performance, and data security. Standard models are convenient and powerful, but open source LLMs offer tailored performance, cost savings, and enhanced data privacy.
Open source models can be fine-tuned for specific applications, ensuring accuracy in niche tasks. While the initial costs might be higher, ongoing expenses can be lower than standard APIs, especially for high-volume use cases. These models also provide greater control over data, which is essential for sensitive information, and offer scalability and adaptability to meet evolving needs. Here’s a table to help you understand the differences better:
| Criteria | Open Source LLMs | Closed Source LLM APIs |
|---|---|---|
| Tailored Solutions | Domain-specific | General-purpose capabilities |
| Cost | Lower long-term costs | Lower short-term costs |
| Data Privacy | Greater control | Limited control |
| Scalability | Flexible and adaptable | Fixed |
| Performance | Superior for specific tasks | Robust general performance |
Now that we’ve established why open source LLMs could be the right fit for your use case, let’s explore a popular open source LLM inference engine that will help run your LLM much faster and cheaper.
vLLM is a blazingly fast LLM inference engine that lets you run open source models at 24x higher throughput than other open source engines.
vLLM achieves this performance by utilizing a memory allocation algorithm called PagedAttention. For a deeper understanding of how PagedAttention works, check out our blog on vLLM.
Here are the key reasons why you should use vLLM:
Now let's dive into how you can start running vLLM in less than a few minutes.
Follow the step-by-step guide below with screenshots and video walkthrough at the end to deploy your open source LLM with vLLM in less than a few minutes.
Pre-requisites:
Step-by-step Guide:
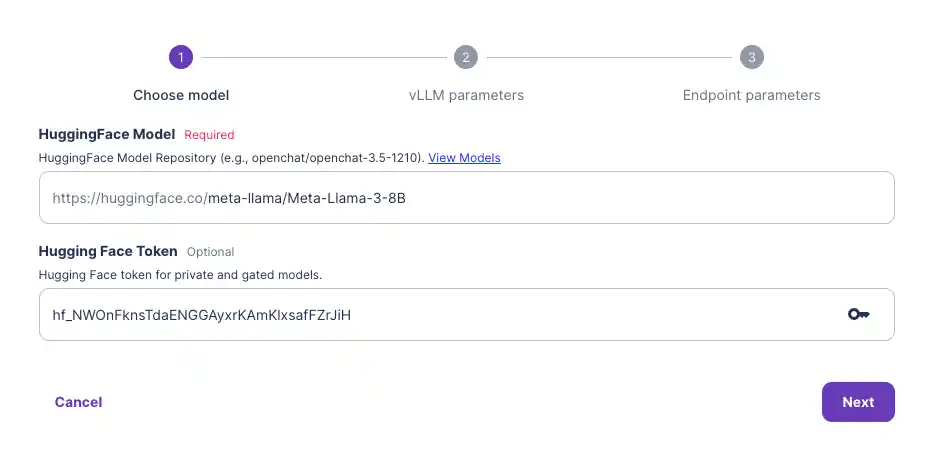
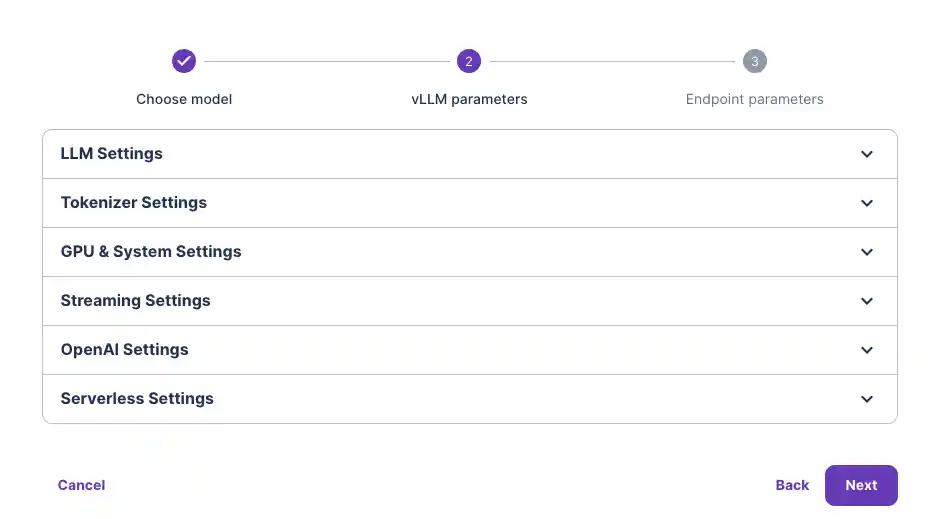
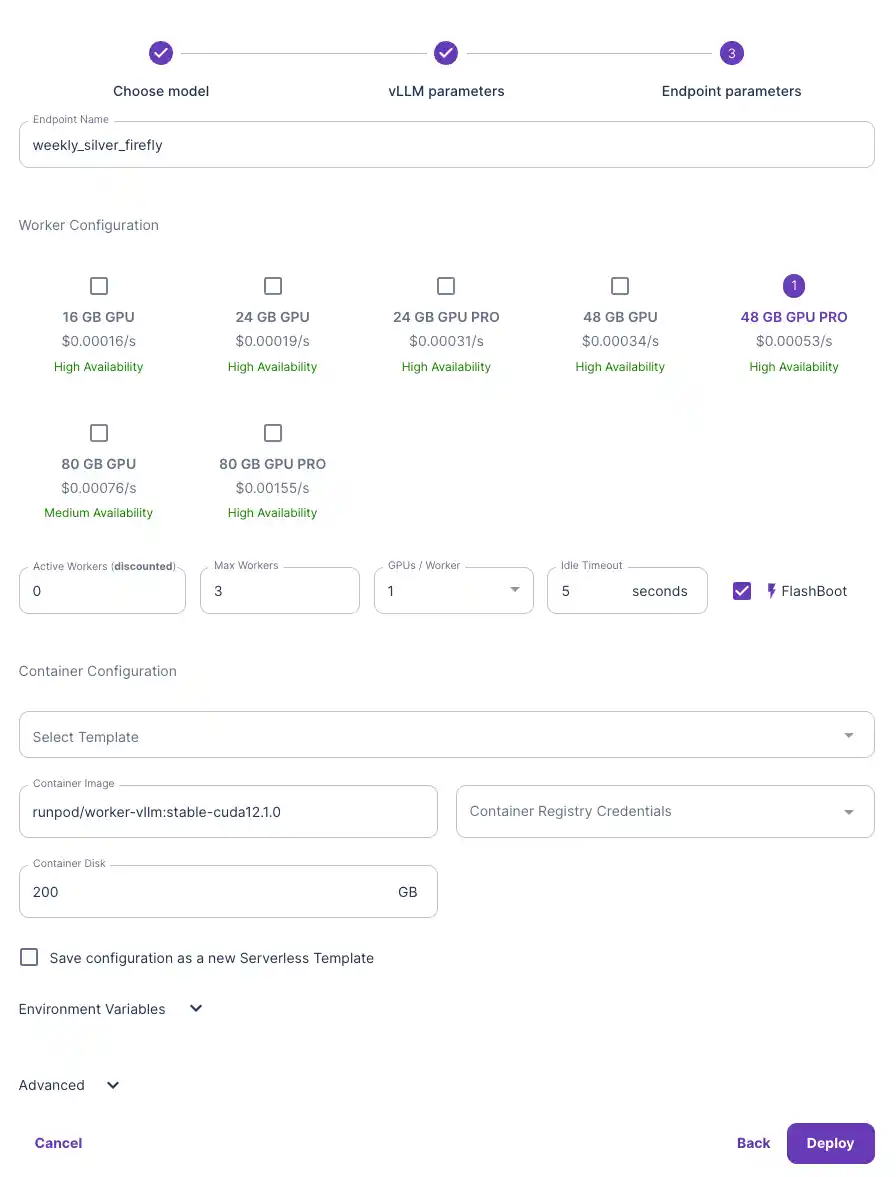
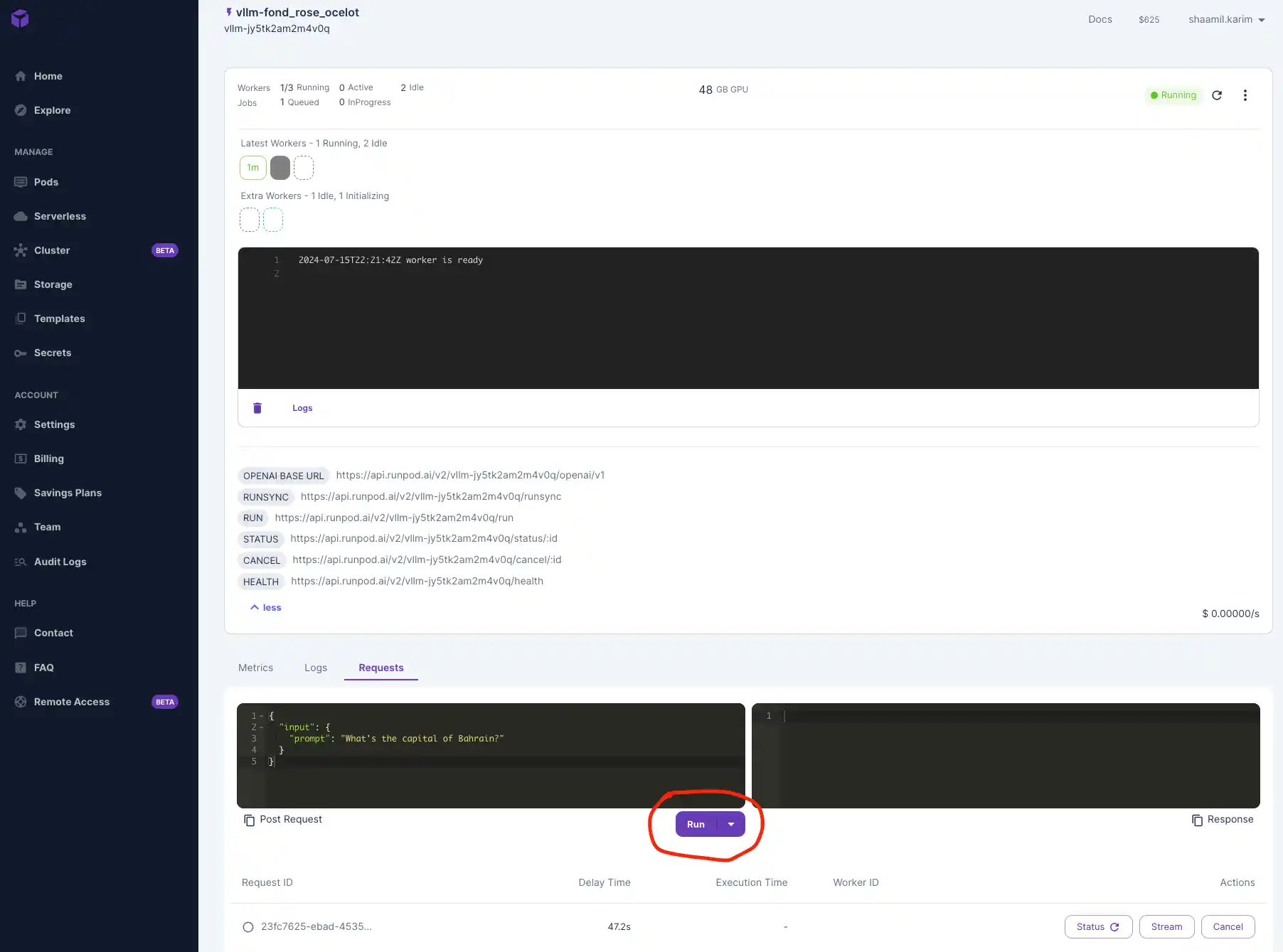
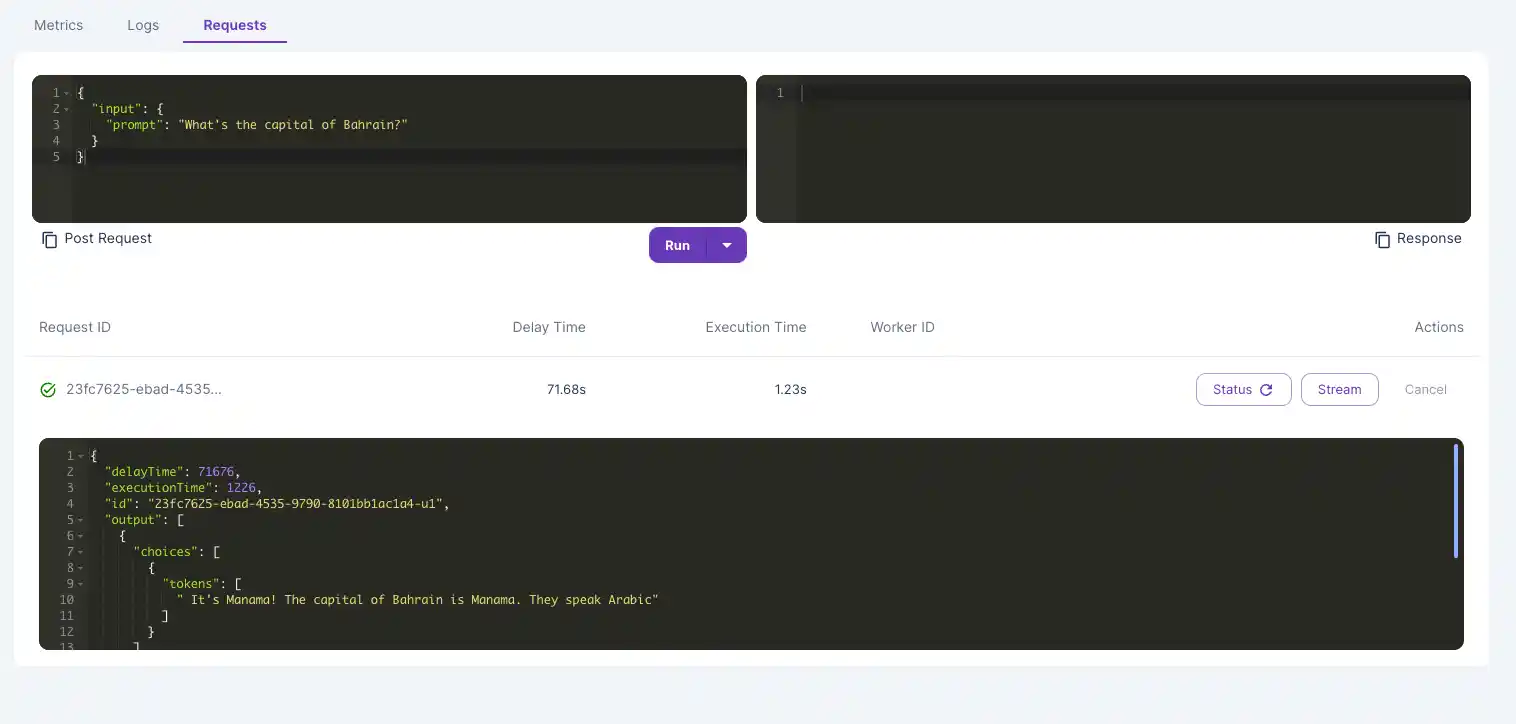
Video guide:
When sending a request to your LLM for the first time, your endpoint needs to download the model and load the weights. If the output status remains "in queue" for more than 5-10 minutes, read below!
To recap, open source LLMs boost performance through fine-tuning for specific applications, reduce inference costs, and maintain control over your data. To run your open source LLM, we recommend using vLLM - an inference engine that's highly-compatible with thousands of LLMs and increases throughput by up to 24x vs. other engines.
Hopefully by now, you should have a stronger grasp of when you should use closed source vs open source models and how to run your own open source models with vLLM on Runpod.
Deploy vLLM on Runpod Serverless
Author profile: Shaamil Karim
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。