2018-10-23 Nginx
- Nginx 安装
- 官方下载稳定版本
- 安装依赖环境
- 解压 & 预编译
- 编译安装
- 优化配置
- 优化 worker 进程数
- 绑定 CPU
- 事件处理模型
- 单个进程允许的最大连接数
- 单个进程允许的最大文件数
- 开启高效文件传输模式
- 连接超时时间
- 连接超时的作用
- 连接超时存在的问题
- 设置超时时间
- 限制上传文件的大小
- gzip 压缩
- 断点续传
- expires 缓存期限
- 配置防盗链
- server 代码块
- location 代码块
- 全局变量
- 安全配置
- 隐藏版本号
- 修改默认用户
- 日志切割
- robots.txt 机器人协议
- 反向代理
- 负载均衡
- 加权轮询
- IP Hash
- Url hash
- 最小连接
- 扩展阅读
- 负载均衡
Nginx 安装
官方下载稳定版本
官方下载地址: https://nginx.org/en/download.html
安装依赖环境
- 安装 gcc 环境用于编译
- 安装 PCRE 库用于解析正则表达式
yum install -y pcre pcre-devel
- 安装 zlib 用于压缩和解压缩
yum install -y zlib zlib-devel
- 安装 SSL 用于 https
yum install -y openssl openssl-devel
解压 & 预编译
tar -zxvf nginx-1.16.1.tar.gz
编译之前,先创建 Nginx 工作目录,如果不创建,在启动 nginx 的过程中会报错。
在 Nginx 工作目录输入如下命令进行配置,目的是为了创建 Makefile 文件。
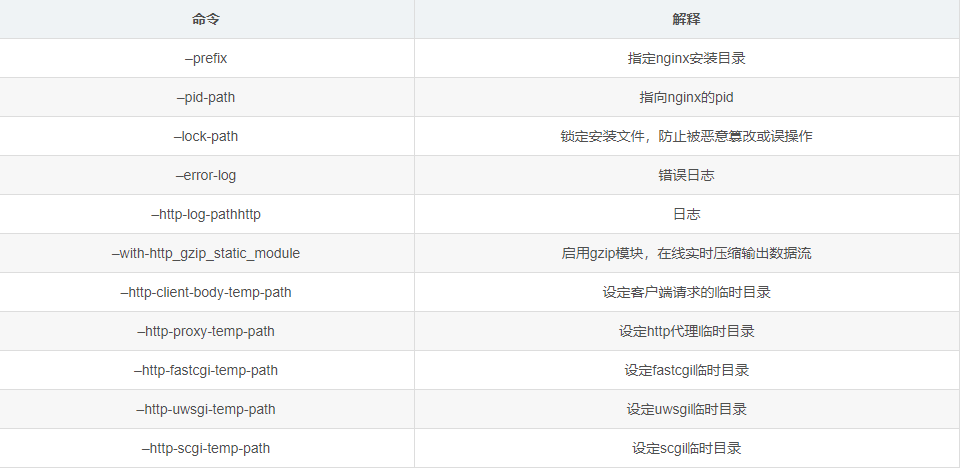
./configure \
--prefix=/usr/local/nginx \
--pid-path=/var/run/nginx/nginx.pid \
--lock-path=/var/lock/nginx.lock \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-http_gzip_static_module \
--http-client-body-temp-path=/var/nginx/client \
--http-proxy-temp-path=/var/nginx/proxy \
--http-fastcgi-temp-path=/var/nginx/fastcgi \
--http-uwsgi-temp-path=/var/nginx/uwsgi \
--http-scgi-temp-path=/var/nginx/scgi \
--with-http_ssl_module
然后开始安装 HTTPS 证书:
将 SSL 证书 *.crt 和私钥 *.key 文件拷贝到 /usr/local/nginx/conf 目录中,修改配置文件,新增监听 443 端口:
server {
listen 443;
server_name www.example.com;
# 开启 ssl
ssl on;
# 配置 ssl 证书
ssl_certificate example.com.crt;
# 配置证书秘钥
ssl_certificate_key example.com.key;
# ssl 会话cache
ssl_session_cache shared:SSL:1m;
# ssl会话超时时间
ssl_session_timeout 5m;
# 配置加密套件,写法遵循 openssl 标准
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
location / {
proxy_pass backend_service_name;
index index.html index.htm;
}
}
编译安装
安装完成之后,可以进入 sib 目录执行相关操作。
# 启动 Nginx
$ nginx
# 停止 Nginx
$ /nginx -s stop
# 重新加载配置
$ nginx -s reload
优化配置
优化 worker 进程数
Nginx 有 master 和 worker 两种进程,master 进程用于管理 worker 进程,worker 进程用于 Nginx 服务,参数 worker_processes 表示需要启动的进程数量 (默认为 1)。
# 设置为 auto 自动匹配进程数
worker_processes auto;
绑定 CPU
默认情况下,Nginx 的多个进程有可能运行在某一个 CPU 或 CPU 的某一核上,导致 Nginx 进程使用硬件的资源不均,因此绑定 Nginx 进程到不同的 CPU 上是为了充分利用硬件的多 CPU 多核资源。
worker_processes 4;
# 为每个进程分配一个 CPU 核
worker_cpu_affinity 0001 0010 0100 1000;
# 自动分配
# worker_cpu_affinity auto;
事件处理模型
# Linux 使用 epoll IO 多路复用模型
events {
use epoll;
}
当然也可以不指定事件处理模型,Nginx 会自动选择最佳的事件处理模型。
单个进程允许的最大连接数
控制 Nginx 单个进程允许的最大连接数的参数为 worker_connections,这个参数要根据服务器性能和内存使用量来调整。
进程的最大连接数受 Linux 系统进程打开的最大文件数的限制,只有执行了 “ulimit -HSn 65535” 之后,worker_connections 才能生效。
连接数包括代理服务器的连接、客户端的连接等,Nginx 总并发连接数 = worker_processes * worker_connections, 测试完之后记得根据不同业务场景进行压测并调整。
# 设置单个进程允许的最大连接数为 65536
worker_processes 65535;
单个进程允许的最大文件数
# 设置单个进程打开的最大文件数为 65535
worker_rlimit_nofile 65535;
开启高效文件传输模式
sendfile 参数用于开启文件的高效传输模式,该参数实际上是激活了 sendfile() 功能。
sendfile() 是作用于两个文件描述符之间的数据拷贝函数,这个拷贝操作是在内核之中的,被称为 “零拷贝” 。sendfile 比 read 和 write 函数要高效得多,因为 read 和 write 函数要把数据拷贝到应用层再进行操作。
tcp_nopush 参数用于激活 Linux 上的 TCP_CORK socket 选项,尽可能发送大块的数据,减少数据包的数量,此选项仅仅当开启 sendfile 时才生效, tcp_nopush 参数可以把 http response header 和文件的开始部分放在一个文件里发布,以减少网络报文段的数量。
sendfile on;
tcp_nopush on;
连接超时时间
连接超时的作用
- 将无用的连接设置为尽快超时,可以保护服务器的系统资源(CPU、内存、磁盘)
- 当连接很多时,及时断掉那些建立好的但又长时间不做事的连接,以减少其占用的服务器资源
- 如果黑客攻击,会不断地和服务器建立连接,因此设置连接超时以防止大量消耗服务器的资源
- 如果用户请求了动态服务,则 Nginx 就会建立连接,请求 FastCGI 服务以及后端数据库服务,设置连接超时,使得在用户容忍的时间内返回数据
连接超时存在的问题
- 服务器建立新连接是要消耗资源的,因此,连接超时时间不宜设置得太短,否则会造成并发很大,导致服务器瞬间无法响应用户的请求
- 有些 PHP 站点会希望设置成短连接,因为 PHP 程序建立连接消耗的资源和时间相对要少些
- 有些 Java 站点会希望设置成长连接,因为 Java 程序建立连接消耗的资源和时间要多一些,这是由语言的运行机制决定的
设置超时时间
- keepalive_timeout:用于设置客户端连接保持会话的超时时间,超过这个时间服务器会关闭该连接
- client_header_timeout:用于设置读取客户端请求头数据的超时时间,如果超时客户端还没有发送完整的 header 数据,服务器将返回 “Request time out (408)” 错误
- client_body_timeout:用于设置读取客户端请求主体数据的超时时间,如果超时客户端还没有发送完整的主体数据,服务器将返回 “Request time out (408)” 错误
- send_timeout:用于指定响应客户端的超时时间,如果超过这个时间,客户端没有任何活动,Nginx 将会关闭连接
- tcp_nodelay:默认情况下当数据发送时,内核并不会马上发送,可能会等待更多的字节组成一个数据包,这样可以提高 I/O 性能,但是,在每次只发送很少字节的业务场景中,使用 tcp_nodelay 功能,等待时间会比较长
限制上传文件的大小
client_max_body_size 128M;
如果客户端文件超过 128MB, 就会收到 413 的错误响应码。
gzip 压缩
# 开启 gzip 压缩功能
gzip on;
# 设置允许压缩的页面最小字节数,页面字节数从 header 头的 Content-Length 中获取。默认值是 0,表示不管页面多大都进行压缩。
# 建议设置成大于 1K,如果小于 1K 可能会越压越大
gzip_min_length 1k;
# 压缩缓存区大小。表示申请 4 个单位的位 16K 的内存作为压缩结果流缓存,
# 默认值是申请与原始数据大小相同的内存空间来存储 gzip 压缩结构
gzip_buffers 4 16k;
# 压缩版本 (默认 1.1),用于设置识别 HTTP 协议版本,默认是 1.1,目前大部分浏览器都支持 GZIP 解压,使用默认即可
gzip_http_version 1.1;
# 压缩比率。用来指定 gzip 压缩比,1 压缩比最小,处理速度最快;9 压缩比最大,传输速度快,但处理最慢,也比较消耗 CPU 资源
gzip_comp_level 2;
# 用来指定压缩的类型
gzip_types text/plain text/css text/xml application/javascript;
# vary header 支持。该选项可以让前端的缓存服务器缓存经过 gzip 压缩的页面,例如用 Squid 缓存经过 Nginx 压缩的数据
gzip_vary on;
需要注意的是: 图片和视频文件在启用压缩前需要二次确认,因为这些文件大多数都已经被压缩过了,如果再次压缩可能会适得其反。
断点续传
视频等大文件可以多线程加载,支持断点续传并提高性能。
server {
...
location ~ ^/(mp4|avi/m3u8) {
add_header Access-Control-Allow-Origin *;
add_header Accept-Ranges bytes;
root /var/www/...;
access_log off;
expires 30d;
}
}
expires 缓存期限
server {
...
location / {
proxy_pass http://tomcats;
expires 10s; # 浏览器缓存10秒钟
#expires @22h30m # 在晚上10点30的时候过期
#expires -1h # 缓存在一小时前时效
#expires epoch # 不设置缓存
#expires off # 缓存关闭,浏览器自己控制缓存
#expires max # 最大过期时间
}
}
配置防盗链
主要通过请求的 Referer 头部来确定。
server {
...
location ~* .*\.(gif|jpg|ico|png|css|svg|js)$ {
valid_referers none blocked *.example.com;
if ($invalid_referer) {
return 403;
}
# 合法请求
...
}
}
更好的做法是使用 map 模块或 ngx_http_referer_module 模块来实现,这样可以避免使用 if 语句可能引发的问题。
map $http_referer $invalid_referer {
default 1;
"~*^https?://(www\.)?example\.com" 0;
}
server {
...
location ~ \.(jpg|jpeg|png|gif)$ {
if ($invalid_referer) {
return 403;
}
# 合法请求
...
}
}
上面的配置通过使用 map 模块,将引用者与合法的域名进行匹配,这样可以更加灵活地配置防盗链规则。
server 代码块
server 代码块位于 http 代码块内部,可以添加多个 server,每一个 server 都可以用来配置一个虚拟主机。也就是说,每一个 server 代表了一个虚拟服务器的配置信息。
server 中的主要配置有:
- listen 虚拟主机监听的端口
- server_name 虚拟主机的域名或 IP 地址,可以配置多个(用空格隔开)
- root 虚拟主机的根目录
- index 虚拟主机的首页,也可以用 location 代码块来配置
- access_log 虚拟主机的访问日志
- error_log 虚拟主机的错误日志
- error_page 错误页面
location 代码块
location 代码块位于 server 代码块内部,用于配置虚拟主机的 URI,每一个 server 可以配置多个 location, 根据不同的 URI 配置来处理不同的请求。
全局变量
- $args #这个变量等于请求行中的参数
- $content_length #请求头中的 Content-length 字段
- $content_type #请求头中的 Content-Type 字段
- $document_root #当前请求在 root 指令中指定的值
- $host #请求主机头字段,否则为服务器名称
- $http_user_agent #客户端 agent 信息
- $http_cookie #客户端 cookie 信息
- $limit_rate #这个变量可以限制连接速率
- $request_body_file #客户端请求主体信息的临时文件名
- $request_method #客户端请求的动作,通常为 GET 或 POST
- $remote_addr #客户端的 IP 地址
- $remote_port #客户端的端口
- $remote_user #已经经过 Auth Basic Module 验证的用户名
- $request_filename #当前请求的文件路径,由 root 或 alias 指令与 URI 请求生成
- $ query_string #与$args 相同
- $scheme #HTTP 方法(如 http,https)
- $server_protocol #请求使用的协议,通常是 HTTP/1.0 或 HTTP/1.1
- $server_addr #服务器地址,在完成一次系统调用后可以确定这个值
- $server_name #服务器名称
- $server_port #请求到达服务器的端口号
- $ request_uri #包含请求参数的原始 URI,不包含主机名,如:”/foo/bar.php?arg=baz”
- $ uri #不带请求参数的当前 URI,$uri 不包含主机名,如”/foo/bar.html”
- $ document_uri #与$uri 相同
安全配置
隐藏版本号
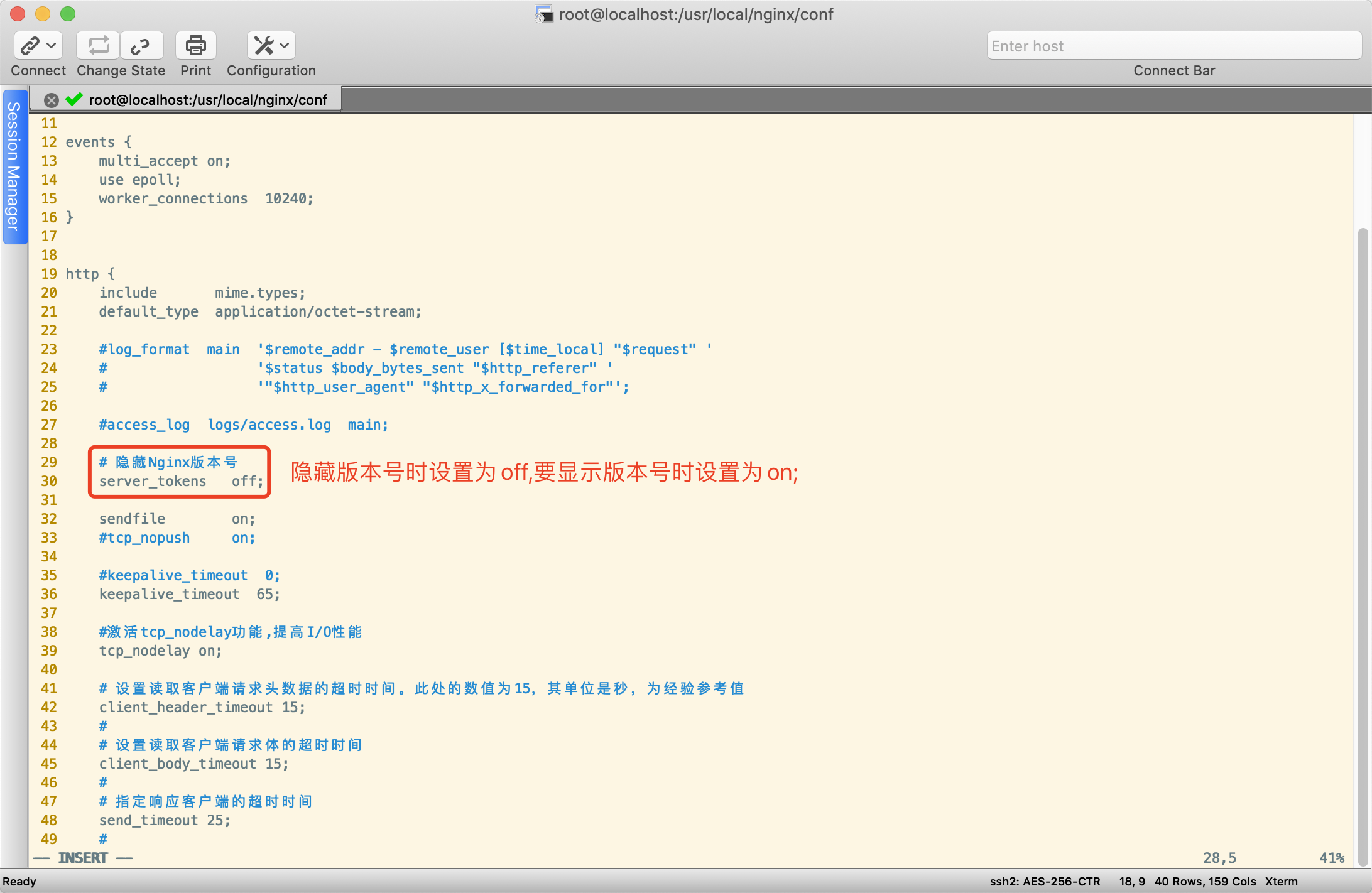
修改默认用户
首先查看 Nginx 服务对应的默认用户:
grep '#user' nginx.conf.default

- 为 Nginx 创建新用户
useradd nginx -s /sbin/nologin -M # 不需要有系统登录权限,应当禁止其登录能力
- 配置 Nginx 刚创建的用户
第一种是直接修改配置文件参数,将默认的 #user nobody; 修改为如下内容:
第二种方法 (推荐使用) 为直接在编译 Nginx 软件的时候指定编译的用户名和组,这样无论配置文件中是否加参数,用户都是 nginx (固定的)。
./configure \
--user=nginx \
--group=nginx \
--prefix=/usr/local/nginx-1.18.0 \
--with-http_v2_module \
--with-http_ssl_module \
--with-http_stub_status_module
日志切割
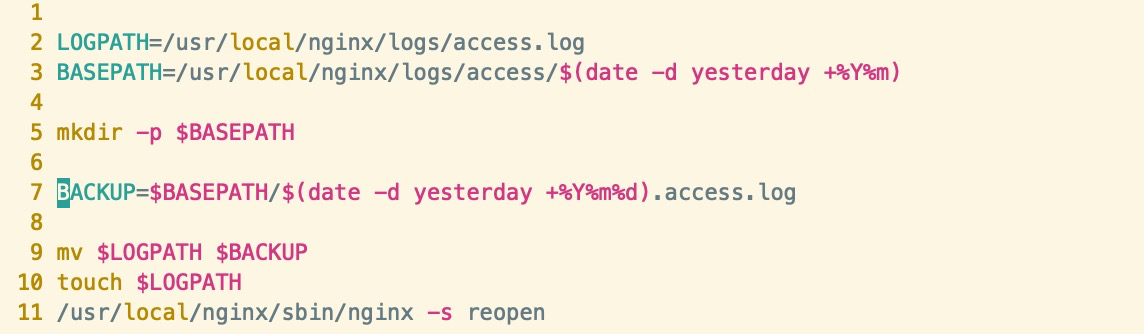
创建一个 runlog.sh 文件,按天切割
# 日志文件路径
LOGPATH=/usr/local/nginx/logs/access.log
BASEPATH=/usr/local/nginx/logs/access/$(date -d yesterday +%Y%m)
mkdir -p $BASEPATH
BACKUP=$BASEPATH/$(date -d yesterday +%Y%m%d).access.log
mv $LOGPATH $BACKUP
touch $LOGPATH
/usr/local/nginx/sbin/nginx -s reopen
日志切割脚本配合定时任务,每天 0 点切割一次
0 0 * * * sh /usr/local/nginx/logs/runlog.sh

robots.txt 机器人协议
通过 Robots 协议告诉搜索引擎 (爬虫) 哪些页面可以抓取,哪些页面不能抓取。
server {
...
location = /robots.txt {
alias /path/to/your/robots.txt;
}
}
# robots.txt 文件内容
User-agent: *
Disallow: /private/
Disallow: /restricted/
Robots.txt 文件指示所有爬虫(User-agent: *)不应该爬取 /private/ 和 /restricted/ 路径下的所有内容。
反向代理
upstream [proxyName] {
server 192.168.1.173:8080;
server 192.168.1.174:8080;
server 192.168.1.175:8080;
}
# proxy_cache_path 设置缓存保存的目录的位置
# keys_zone设置共享内以及占用的空间大小
# mas_size 设置缓存最大空间
# inactive 缓存过期时间,错过此时间自动清理
# use_temp_path 关闭零时目录
proxy_cache_path /usr/local/nginx/upsteam_cache keys_zone=mycache:5m max_size=1g inactive=8h use_temp_path=off;
server {
listem 80;
server_name www.tomcats.com;
# 开启并使用缓存
proxy_cache mycache;
# 针对200和304响应码的缓存过期时间
proxy_cache_valid 200 304 8h;
location / {
proxy_pass backend_service_name;
}
}
负载均衡
加权轮询
upstream [proxyName] {
server 192.168.1.173:8080 weight=1;
server 192.168.1.174:8080 weight=5;
server 192.168.1.175:8080 weight=2;
}
IP Hash
upstream [proxyName] {
ip_hash
server 192.168.1.173:8080;
server 192.168.1.174:8080;
server 192.168.1.175:8080;
}
使用注意: 不能把后端服务器直接移除,只能标记 down。
Url hash
upstream [proxyName] {
hash $request_url;
server 192.168.1.173:8080;
server 192.168.1.174:8080;
server 192.168.1.175:8080;
}
最小连接
upstream [proxyName] {
least_conn;
server 192.168.1.173:8080;
server 192.168.1.174:8080;
server 192.168.1.175:8080;
}