- 基本概念
- 1. 文件描述符限制
- 2. 服务器 TCP 连接数量上限
- 如何测试?
- too many open files
- 解决方案
- 1. 临时性调整
- 2. 永久性设置
- 3. 其他设置
- 4. 查看配置
- 解决方案
- Linux 内核参数调优
- 注意事项
- 客户端参数
- Reference
- 扩展阅读
基本概念
1. 文件描述符限制
- 系统级别限制:操作系统会设置一个全局的文件描述符限制,控制整个系统能同时打开的最大文件数
- 用户级别限制:每个用户会有一个文件描述符的限制,控制这个用户能够同时打开的最大文件数
- 进程级别限制:每个进程也会有一个文件描述符的限制,控制单个进程能够同时打开的最大文件数
2. 服务器 TCP 连接数量上限
一个服务端的 TCP 网络应用,理论上可以支持的最大连接数量是多少?
$$ TCP 四元组 = 客户端 IP + 客户端 Port + 服务端 IP + 服务端 Port $$
其中服务端 IP、服务端 Port 已经固定了 (就是监听的 TCP 程序),所以理论的连接数量上限就取决于 (客户端 IP * 客户端 Port) 的组合数量了。
$$ 客户端 IP 数量 * 客户端 Port 数量 = 2^{32} * 2^{16} = 2^{48} $$
当然如果服务端程序监听 1 ~ 65535 的所有端口号,理论的连接数量上限就变为:
$$ 2^{32} * 2^{16} * 2^{16} = 2^{64} $$
当然实际情况下肯定达不到这样的上限数量,原因有三:
- IP 地址中有分类地址 (A, B, C 类)、内网地址、保留地址 (D, E 类),其中后两者无法用于公网通信
- 某些端口会被保留,仅供专门程序使用,例如 DNS (53), HTTPS (443)
- 服务器内存大小有上限,一个 TCP 套接字会关联内存缓冲区、文件描述符等资源
综上所述,一个服务端的 TCP 网络应用,可以支持的最大连接数量主要取决于其内存大小 (内核参数都已经调优的情况下)。
如何测试?
在测试设备不充足的情况下,如何测试百万连接数量场景?核心思路:突破 TCP 四元组限制即可。
- 客户端配置多个 IP, 这样每个 IP 地址就有大约 64K 个端口号可以使用,向服务端发起连接之前,绑定不同的 IP 地址即可
- 服务端监听多个端口号,客户端只需要连接不同的服务端号口即可
too many open files
首先来看一个高并发场景下的 “经典问题”: too many open files, 产生这个问题的根本原因是: 短时间内打开大量网络 (文件) 连接,超过了操作系统对单个进程允许打开的文件描述符(file descriptor)数量限制。
想要单机支持 100 万链接,需要调优哪些参数呢?
解决方案
Soft open files 是 Linux 系统参数,影响系统单个进程能够打开最大的文件句柄数量。
$ ulimit -n
# 默认输出 1024 或者 65535
1024
表示单个进程同时最多只能维持 1024 个网络 (例如 TCP) 连接。
可以通过增大该参数,来支持更大的网络连接数量。
1. 临时性调整
只在当前会话 (终端) 中有效,退出或重启后失效
2. 永久性设置
修改配置文件 /etc/security/limits.conf:
$ sudo vim /etc/security/limits.conf
# 追加如下内容 (例如支持百万连接)
# 重启永久生效
# 单个进程可以打开的最大进程数量
# 表示可以针对不同用户配置不同的值
# 当然实际情况中,网络应用一般会独享整个主机/容器所有资源
# 调整文件描述符限制
# 注意: 实际生效时会以两者中的较小值为准 (所以最好的方法就是保持两个值相同)
* soft nofile 1048576
* hard nofile 1048576
root soft nofile 1048576
root hard nofile 1048576
运行 sysctl -p 命令生效,重启之后仍然有效。
3. 其他设置
单个进程打开的文件描述符数量 不能超过 操作系统所有进程文件描述符数量 (/proc/sys/fs/file-max), 所以需要修改对应的值:
$ sudo vim /etc/sysctl.conf
# 操作系统所有进程一共可以打开的文件数量
# 增加/修改以下内容
# 注意: 该设置只对非 root 用户进行限制, root 不受影响
fs.file-max = 16777216
# 进程级别可以打开的文件数量
# 或者可以设置为一个比 soft nofile 和 hard nofile 略大的值
fs.nr_open = 16777216
运行 sysctl -p 命令生效,重启之后仍然有效。
4. 查看配置
$ cat /proc/sys/fs/file-nr
# 第一个数表示当前系统使用的文件描述符数
# 第二个数表示分配后已释放的文件描述符数
# 第三个数等于 file-max
1344 0 1048576
Linux 内核参数调优
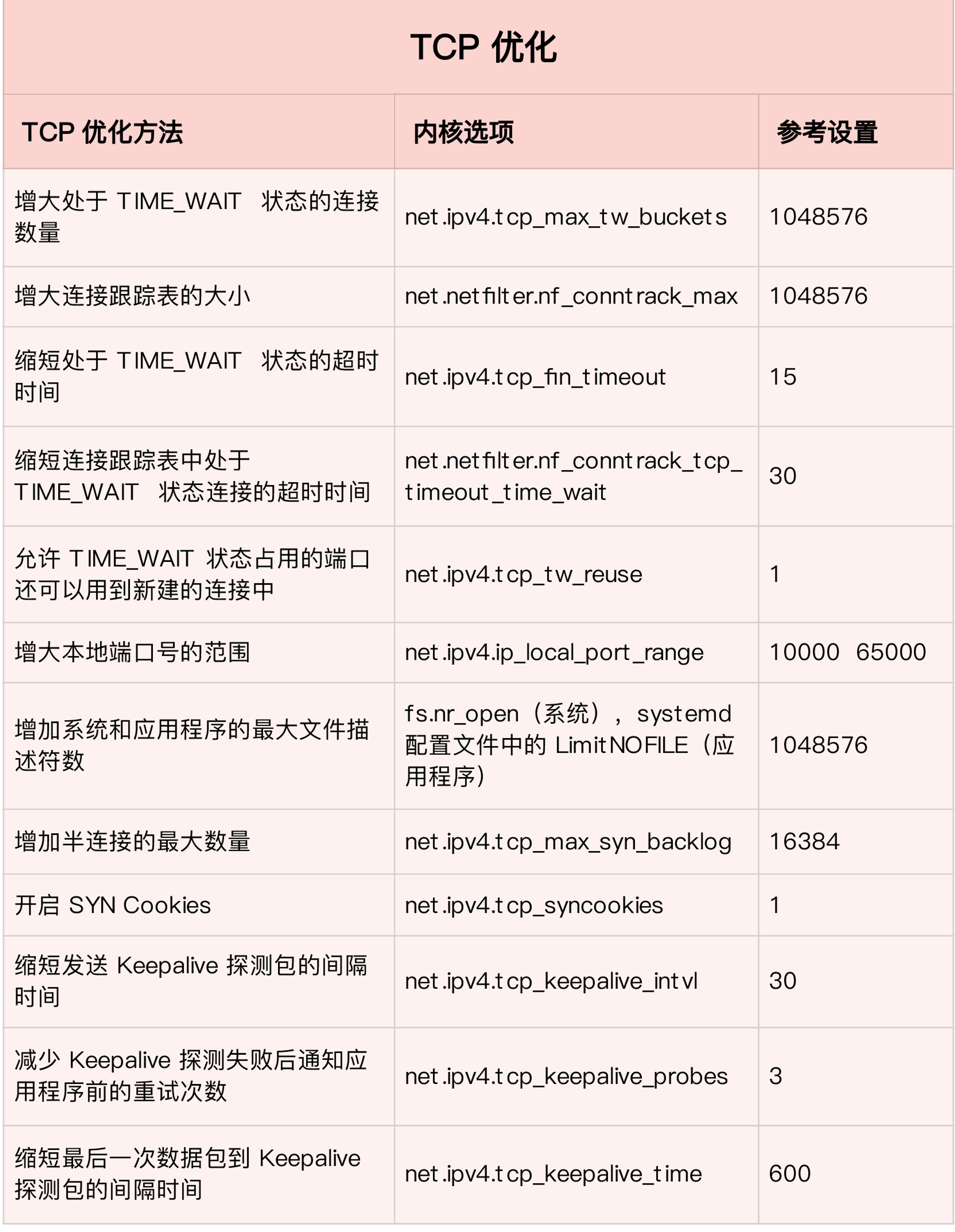
想要单机支持 100 万链接,除了刚才的 文件描述符数量 参数调优之外,还需要针对部分内核参数进行调优。
打开系统配置文件 /etc/sysctl.conf,增加 (或修改) 以下配置数据,参数名称及其作用已经写在了注释中。
# 设置系统的 TCP TIME_WAIT 数量,如果超过该值
# 不需要等待 2MSL,直接关闭
net.ipv4.tcp_max_tw_buckets = 1048576
# 将处于 TIME_WAIT 状态的套接字重用于新的连接
# 如果新连接的时间戳 大于 旧连接的最新时间戳
# 重用该状态下的现有 TIME_WAIT 连接,这两个参数主要针对接收方 (服务端)
# 对于发送方 (客户端) ,这两个参数没有任何作用
net.ipv4.tcp_tw_reuse = 1
# 必须配合使用
net.ipv4.tcp_timestamps = 1
# 启用快速回收 TIME_WAIT 资源
# net.ipv4.tcp_tw_recycle = 1
# 能够更快地回收 TIME_WAIT 套接字
# 此选项会导致处于 NAT 网络的客户端超时,建议设置为 0
# 因为当来自同一公网 IP 地址的不同主机尝试与服务器建立连接时,服务器会因为时间戳的不匹配而拒绝新的连接
# 这是因为内核会认为这些连接是旧连接的重传
# 该配置会在 Linux/4.12 被移除
# 在之后的版本中查看/设置会提示 "cannot stat /proc/sys/net/ipv4/tcp_tw_recycle"
# net.ipv4.tcp_tw_recycle = 0
# 缩短 Keepalive 探测失败后,连接失效之前发送的保活探测包数量
net.ipv4.tcp_keepalive_probes = 3
# 缩短发送 Keepalive 探测包的间隔时间
net.ipv4.tcp_keepalive_intvl = 15
# 缩短最后一次数据包到 Keepalive 探测包的间隔时间
# 减小 TCP 连接保活时间
# 决定了 TCP 连接在没有数据传输时,多久发送一次保活探测包,以确保连接的另一端仍然存在
# 默认为 7200 秒
net.ipv4.tcp_keepalive_time = 600
# 控制 TCP 的超时重传次数,决定了在 TCP 连接丢失或没有响应的情况下,内核重传数据包的最大次数
# 如果超过这个次数仍未收到对方的确认包,TCP 连接将被终止
net.ipv4.tcp_retries2 = 10
# 缩短处于 TIME_WAIT 状态的超时时间
# 决定了在发送 FIN(Finish)包之后,TCP 连接保持在 FIN-WAIT-2 状态的时间 (对 FIN-WAIT-1 状态无效)
# 主要作用是在 TCP 连接关闭时,为了等待对方关闭连接而保留资源的时间
# 如果超过这个时间仍未收到 FIN 包,连接将被关闭
# 更快地检测和释放无响应的连接,释放资源
net.ipv4.tcp_fin_timeout = 15
# 调整 TCP 接收和发送窗口的大小,以提高吞吐量
# 三个数值分别是 min,default,max,系统会根据这些设置,自动调整 TCP 接收 / 发送缓冲区的大小
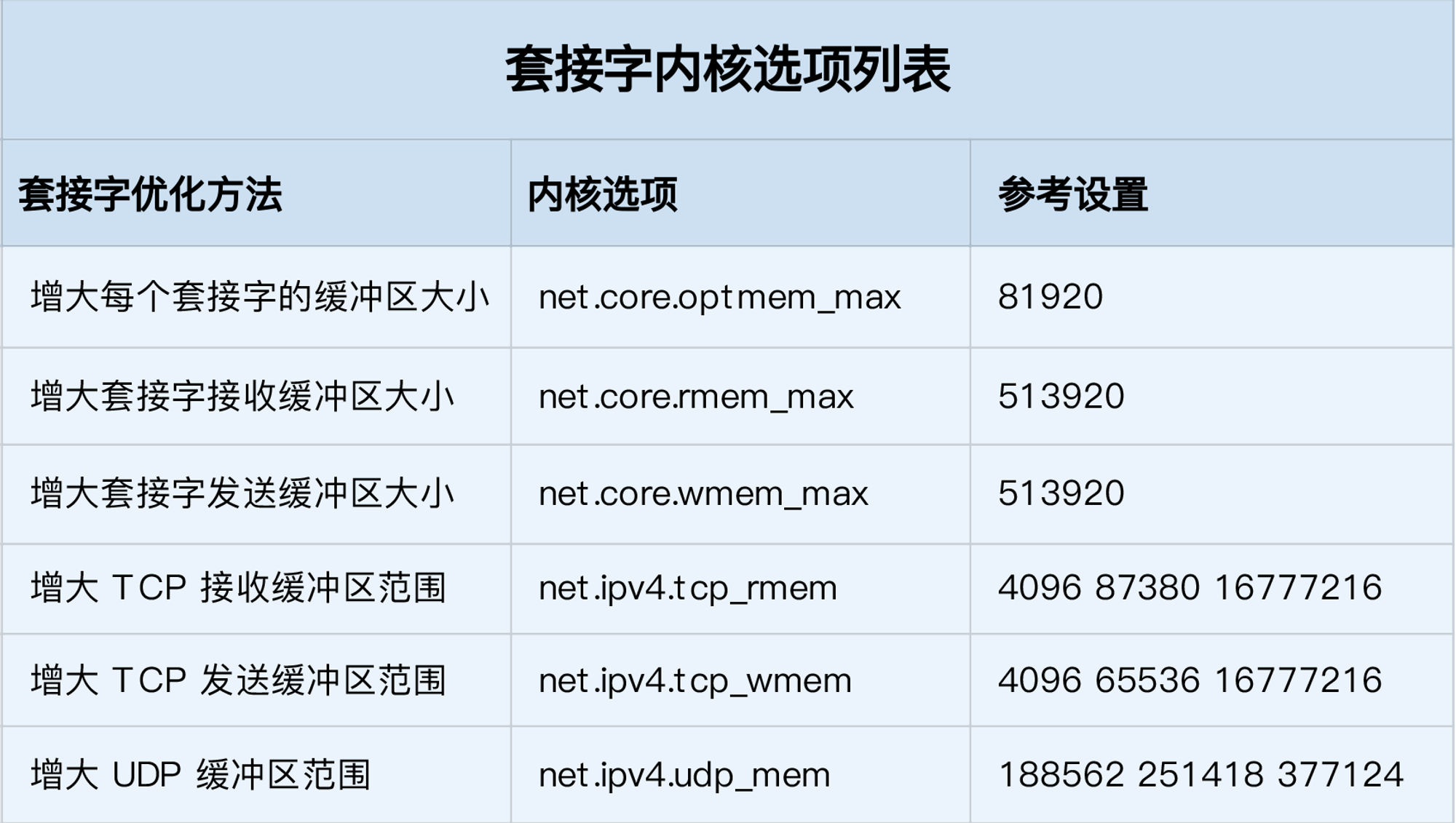
net.ipv4.tcp_mem = 8388608 12582912 16777216
net.ipv4.tcp_rmem = 8192 87380 16777216
net.ipv4.tcp_wmem = 8192 65535 16777216
# 定义了系统中每一个端口监听队列的最大长度
net.core.somaxconn = 65535
# 增加半连接队列容量
# 除了系统参数外 (net.core.somaxconn, net.ipv4.tcp_max_syn_backlog)
# 程序设置的 backlog 参数也会影响,以三者中的较小值为准
net.ipv4.tcp_max_syn_backlog = 65535
# 全连接队列已满后,如何处理新到连接 ?
# 如果设置为 0 (默认情况)
# 客户端发送的 ACK 报文会被直接丢掉,然后服务端重新发送 SYN+ACK (重传) 报文
# 如果客户端设置的连接超时时间比较短,很容易在这里就超时了,返回 connection timeout 错误,自然也就没有下文了
# 如果客户端设置的连接超时时间比较长,收到服务端的 SYN+ACK (重传) 报文之后,会认为之前的 ACK 报文丢包了
# 于是再次发送 ACK 报文,也许可以等到服务端全连接队列有空闲之后,建立连接完成
# 当服务端重试次数到达上限 (tcp_synack_retries) 之后,发送 RST 报文给客户端
# 默认情况下,tcp_synack_retries 参数等于 5, 而且采用指数退避算法
# 也就是说,5 次的重试时间间隔为 1s, 2s, 4s, 8s, 16s, 总共 31s
# 第 5 次重试发出后还要等 32s 才能知道第 5 次重试也超时了,所以总共需要等待 1s + 2s + 4s+ 8s+ 16s + 32s = 63s
# 如果设置为 1
# 服务端直接发送 RST 报文给客户端,返回 connection reset by peer
# 设置为 1, 可以避免服务端给客户端发送 SYN+ACK
# 但是会带来另外一个问题: 客户端无法根据 RST 报文判断出,服务端拒绝的具体原因:
# 因为对应的端口没有应用程序监听,还是全队列满了
# 除了系统参数外 (net.core.somaxconn)
# 程序设置的 backlog 参数也会影响,以两者中的较小值为准
# 所以全连接队列大小 = min(backlog, somaxconn)
net.ipv4.tcp_abort_on_overflow = 1
# 增大每个套接字的缓冲区大小
net.core.optmem_max = 81920
# 增大套接字接收缓冲区大小
net.core.rmem_max = 16777216
# 增大套接字发送缓冲区大小
net.core.wmem_max = 16777216
# 增加网络接口队列长度,可以避免在高负载情况下丢包
# 在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数量
net.core.netdev_max_backlog = 65535
# 增加连接追踪表的大小,可以支持更多的并发连接
# 注意:如果防火墙没开则会提示 error: "net.netfilter.nf_conntrack_max" is an unknown key,忽略即可
net.netfilter.nf_conntrack_max = 1048576
# 缩短连接追踪表中处于 TIME_WAIT 状态连接的超时时间
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 30
运行 sysctl -p 命令生效,重启之后仍然有效。
注意事项
如果系统已经使用了参数 net.ipv4.tcp_syncookies, 参数 net.ipv4.tcp_max_syn_backlog 将自动失效,详情见 之前的文章。
客户端参数
当服务器充当 “客户端角色” 时 (例如代理服务器),连接后端服务器器时,每个连接需要分配一个临时端口号。
# 查询系统配置的临时端口号范围
$ sysctl net.ipv4.ip_local_port_range
# 增加系统配置的临时端口号范围
$ sysctl -w net.ipv4.ip_local_port_range="10000 65535"
Reference