2018-12-30 计算机网络
- 概述
- 前置知识点
- 1. 丢包
- 前置知识点
- 拥塞控制
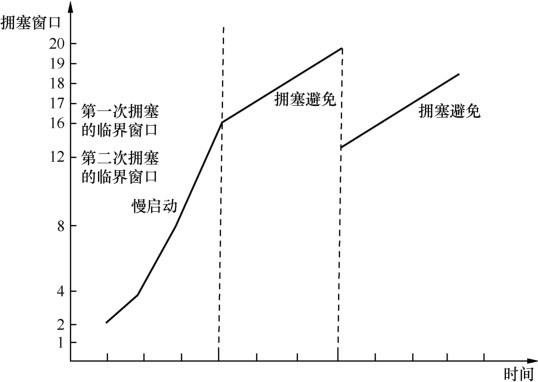
- 1. 慢启动
- 2. 拥塞避免
- 利用 Wireshark 估算网络拥塞点
- 3. 拥塞发生
- 4. 快速恢复
- 不足 (局限性)
- 慢启动和快速恢复到底指什么?
- 小结
- 扩展阅读
概述
TCP 实现可靠传输层的核心有三点:
- 确认与重传 (已经可以满足 “可靠性”,但是可能存在性能问题)
- 滑动窗口 (也就是流量控制,为了提高吞吐量,充分利用链路带宽,避免发送方发的太慢)
- 拥塞控制 (防止网络链路过载造成丢包,避免发送方发的太快)
滑动窗口和拥塞控制相互制约,使发送方可以从网络链路的全局角度来自动调整发送速率,从这个角度来看,TCP 对于整个网络的意义已经超过 “传输层”。
本文主要讲解三个核心中的第三点: 拥塞控制。
滑动窗口主要关注发送方到接收方的流量控制
拥塞控制更多地关注整个网络 (链路) 层面的流量控制
拥塞控制的视角更为全面,会对整个网络链路中的所有主机、路由器,以及降低网络传输性能的有关因素进行综合考量。
前置知识点
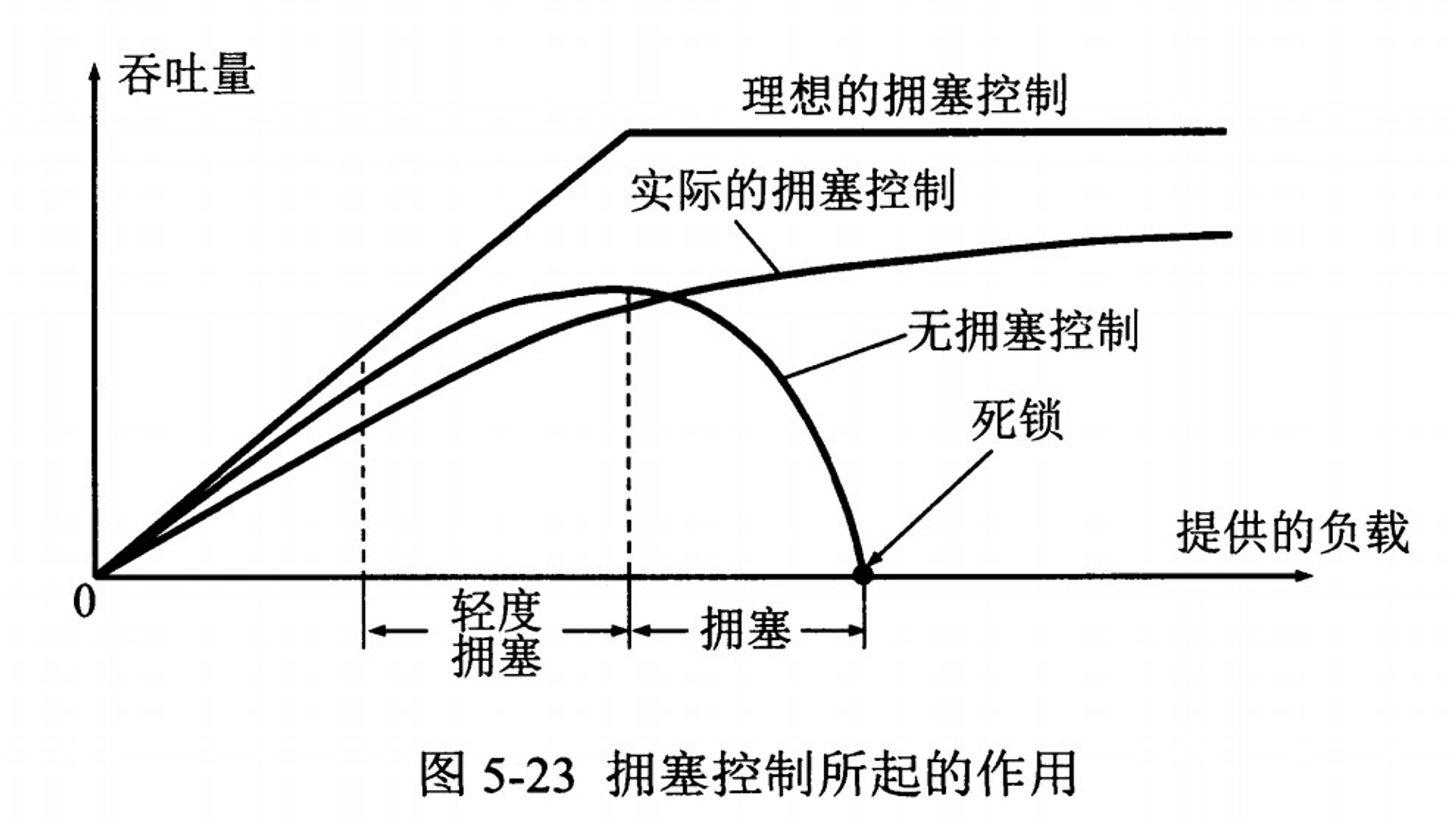
在讲解 TCP 的拥塞控制之前,先来复习几个基本知识点。
1. 丢包
丢包一般分两种情况:
- 网络质量导致的零星丢包
- 网络拥塞导致的大量丢包
丢包会引起重传,重传会加剧网络负载,网络负载严重后,丢包会更严重,进入 “恶性循环”。
如果网络中所有发送方和接收方都进入 “恶性循环”,就会形成 “网络丢包” 风暴,直至拖垮整个网络。
所以 TCP 需要站在整个网络层面的角度,对传输的整个过程链路进行规划和把握,也就是本文的主题 拥塞控制。
拥塞控制
TCP 的拥塞控制的核心思想是根据网络状况动态调整拥塞窗口(cwnd)的大小,通过反馈机制(如丢包和延迟)检测网络拥塞,并相应地调整数据发送速率,主要由 4 个方面组成:
- 慢启动
- 拥塞避免
- 快速重传 (拥塞发生后)
- 快速恢复
目前有非常多的 TCP 的拥塞控制协议,例如:
- 基于丢包 的拥塞控制:采取慢启动方式,逐渐增大拥塞窗口,出现丢包时减小拥塞窗口,如 Reno、Cubic、NewReno
- 基于时延 的拥塞控制:通过延迟和带宽估算来进行拥塞控制,延迟增大时减小拥塞窗口,延时减小时增大拥塞窗口,如 Vegas、FastTCP
- 基于链路容量 的拥塞控制:实时测量网络带宽和时延,根据网络传输中的 报文总量 和带宽时延的乘积 进行拥塞控制,如 BBR (Google 开发的一种算法,通过估算瓶颈带宽和往返时延来控制拥塞)
- 基于学习的 拥塞控制:没有特定的拥塞信号,通过分析不同网络条件下的传输行为,借助评价函数,基于训练数据,使用机器学习的方法生成最优的拥塞控制规则,如 Remy
本文不对上述协议展开讲解,感兴趣的读者可以查阅相关资料。
1. 慢启动
发送方和接收方三次握手后连接建立后,是不是应该直接开始快速发送数据包呢?TCP 认为,虽然单个连接上快速发送大量数据包是 OK 的 (毕竟有滑动窗口地址负责流量控制),但是如果网络中的所有连接都这么做的话,避免会导致流量高峰,进而形成网络拥塞。所以,刚开始的时候应该慢点发送数据,然后根据网络状态不断进行调整 (网络负载较小时就多发送,网络负载较小时就少发送)。
Typically, ssthresh starts at 65535 bytes.
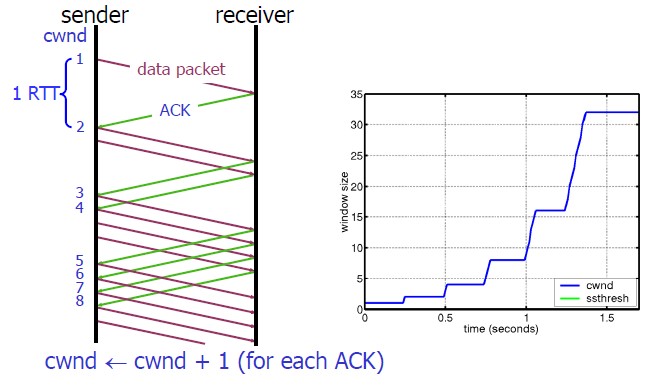
- 初始状态下,cwnd 设置为一个较小的值(例如 2 个 MSS)
- 每收到一个 Ack,cwnd 加 1 (cwnd += 1)
- 所以当前的 cwnd, 每经过一个 RTT, cwnd 翻倍 (cwnd *= 2)
- 直到 cwnd >= ssthresh (预定义的慢启动阈值) 或者检测到丢包,cwnd 增长结束 (进入拥塞避免阶段)
因为是指数级增长,所以 “慢启动” 其实并不慢。
Linux 3.0 之后,采用了 Google 的建议,将 cwnd 初始化为 10 个 MSS。
https://github.com/torvalds/linux/blob/02f8c6aee8df3cdc935e9bdd4f2d020306035dbe/include/net/tcp.h#L200
# Linux 3.0 默认 cwnd 大小
#define TCP_INIT_CWND 10
2. 拥塞避免
不同拥塞控制算法的核心差异主要在 拥塞避免 阶段。
拥塞避免 并非指完全能够避免网络拥塞,而是指在拥塞避免阶段,将拥塞窗口控制为按线性规律增长,使网络尽可能避免出现拥塞。
Typically, ssthresh starts at 65535 bytes.
慢启动持续一段时间后,拥塞窗口变为一个较大的值,此时距离 网络拥塞点 也比较接近了,所以需要降缓速度慢下来。
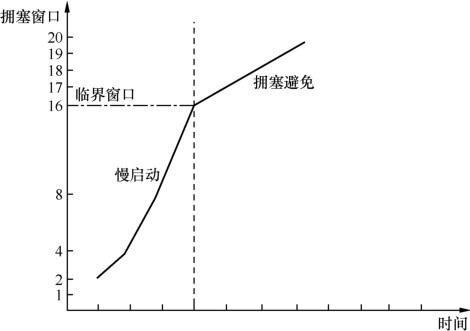
当 cwnd >= ssthresh 时,进入拥塞避免阶段,此时 cwnd 的增长方式变化为:
- 每收到一个 Ack,cwnd = cwnd + 1/cwnd (使用 cwnd 自己的倒数作为增长值,cwnd 越大,增长值越小,反之 cwnd 越小,增长值越大)
- 每经过一个 RTT, cwnd = cwnd + 1
从算法的变化过程可以看出,进入拥塞避免后,cwnd 由指数型增长变化为线性增长。
利用 Wireshark 估算网络拥塞点
网络拥塞的特征是连续丢包,丢包会引起重传,Wireshark 能够标识出重传的数据包,因此可以先从 Wireshark 中找到一连串重传包中的第 1 个,再根据该重传包的 Seq 值找到其原始包,最后计算该原始包发送时刻的在途字节数。由于网络拥塞就是在该原始数据包发出去的时刻发生的,所以这个在途字节数就大致代表了 网络拥塞点 的大小。
可以根据这个结果,多次采样进行参考,然后选定一个合适的值作为该连接的拥塞点。例如根据采样结果取一个偏小的 (类似接口响应的 95 分位) 数值。
3. 拥塞发生
传统 (基于丢包) 的 TCP 流量控制认为,一旦发生丢包,就是网络链路发生了拥塞,所以发送方会急剧地减小发送窗口,甚至进入短暂的等待状态(超时重传)。
所以,1% 的丢包率并不只是降低 1% 的传输性能,而是可能降低 50% 甚至更多 (取决于具体的 TCP 实现)。
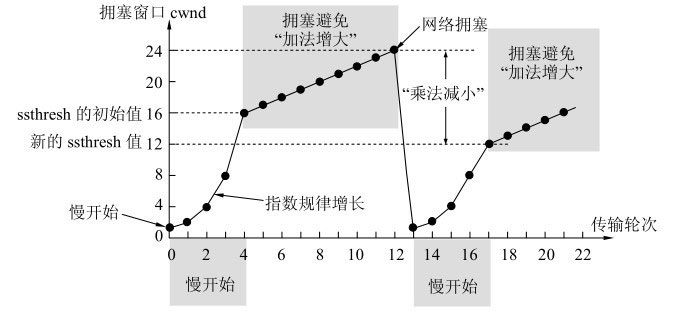
拥塞发生之后,又有几种常用的算法来解决:
1. TCP Tahoe 算法
该算法和超时重传机制一样,工作过程如下:
- 修改 sshthresh = cwnd / 2
- 修改 cwnd = 1
- 进入慢启动过程
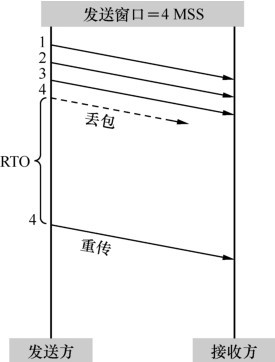
因为拥塞窗口大小直接变为 1,然后重新开始慢启动,所以这是一种极为保守的算法。
2. TCP Reno 算法
该算法工作过程如下:
- 修改 cwnd = cwnd / 2
- 修改 sshthresh = cwnd
- 进入快速恢复过程 (下文中会提到)
3. TCP Cubic 算法
Cubic 是一种改进的拥塞控制算法 (Linux 2.6.18 之后默认使用),是基于丢包机制的拥塞控制算法中表现最好的。
Cubic 和 Reno 算法一样,发生拥塞后也是采用加法线性增加,但是每次不是加 1, 而是根据一个特定的公式来决定窗口增加的大小,从而到达更快地收敛 cwnd。
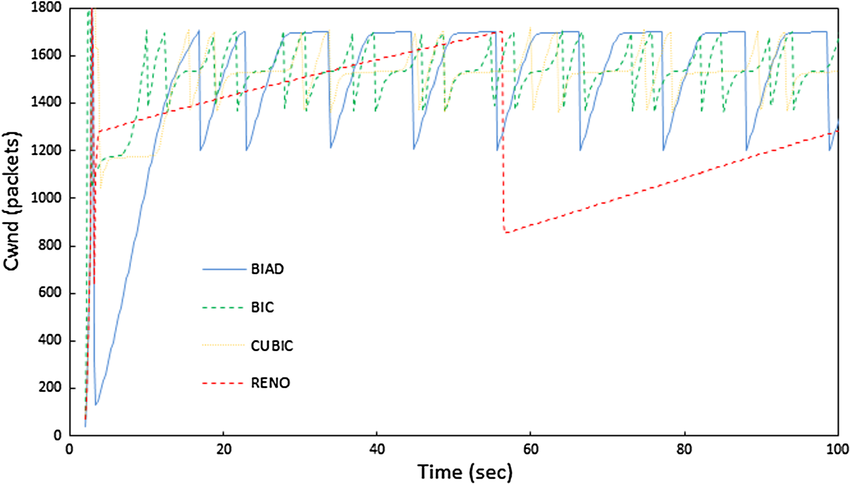
如图所示,相比于 Reno 算法发生拥塞后的 “大起大落”,Cubic 算法要相对 “顺滑” 一些。
由此可见,没有网络拥塞时,发送窗口越大,性能越好,此时应该尽量增大接收窗口 (例如 LAN 环境中)。如果经常发生拥塞,那限制发送窗口反而能提高性能,因为丢包 + 重传是绝对的性能杀手。
4. 快速恢复
在重传数据包之后,发送方不会立即进入慢启动阶段,而是通过调整 cwnd 来快速恢复到丢包前的传输速率。
拥塞发生之后,如果发生了快速重传 (收到 3 个及以上 Dup Ack), 说明此时网络拥塞并没有很严重,所以只要保证接下来降低发送速率就可以了,完全不需要像超时重传一样那么保守,此时就可以进入到快速恢复阶段了。
进入 快速恢复 阶段之前,cwnd 和 sshthresh 已经被修改过了,例如 TCP Reno 算法修改如下:
cwnd = cwnd / 2
sshthresh = cwnd
快速恢复 (Fast Recovery) 算法如下:
- cwnd = sshthresh + 3 * MSS(收到 3 个 Ack)
- 重传 Dup Ack 指定的数据包
- 再次收到 Dup Ack,修改 cwnd = cwnd + 1
- 再次 Ack,修改 cwnd = sshthresh, 进入拥塞避免阶段
不足 (局限性)
相比保守的 RTO 超时重传,快速恢复调整 cwnd 和 sshthresh 更加符合真实的网络链路场景,但是该算法的不足在于: 严重依赖引起快速重传的 Dup Ack, 引发快速重传至少需要 3 个 Dup Ack 包,但是 3 个 Dup Ack 并不意味着只丢了 3 个数据包 (很可能是多个数据包),但是快速重传只会重传一个,其他丢失的数据包依然只能等待 RTO 超时重传,于是进入一个恶性循环:
- 超时一个数据包,sshthresh 就锐减一半
- 超时多个数据包,sshthresh 就会减少到 1, 并且不会触发快速恢复算法了
慢启动和快速恢复到底指什么?
慢启动和快速恢复针对的目标是同一个: cwnd 初始值大小,慢启动设置 cwnd 初始值为 1, 快速恢复设置 cwnd 初始值为 ssthresh。
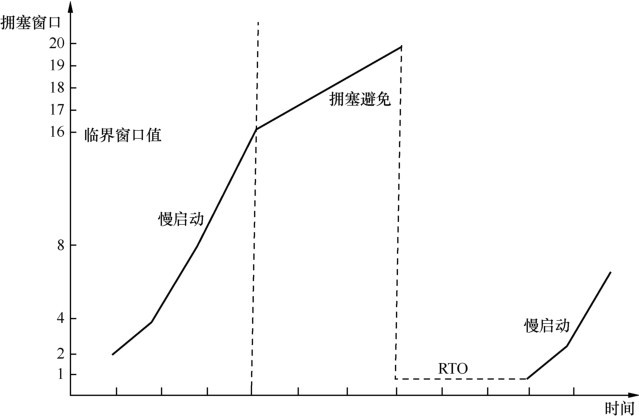
小结
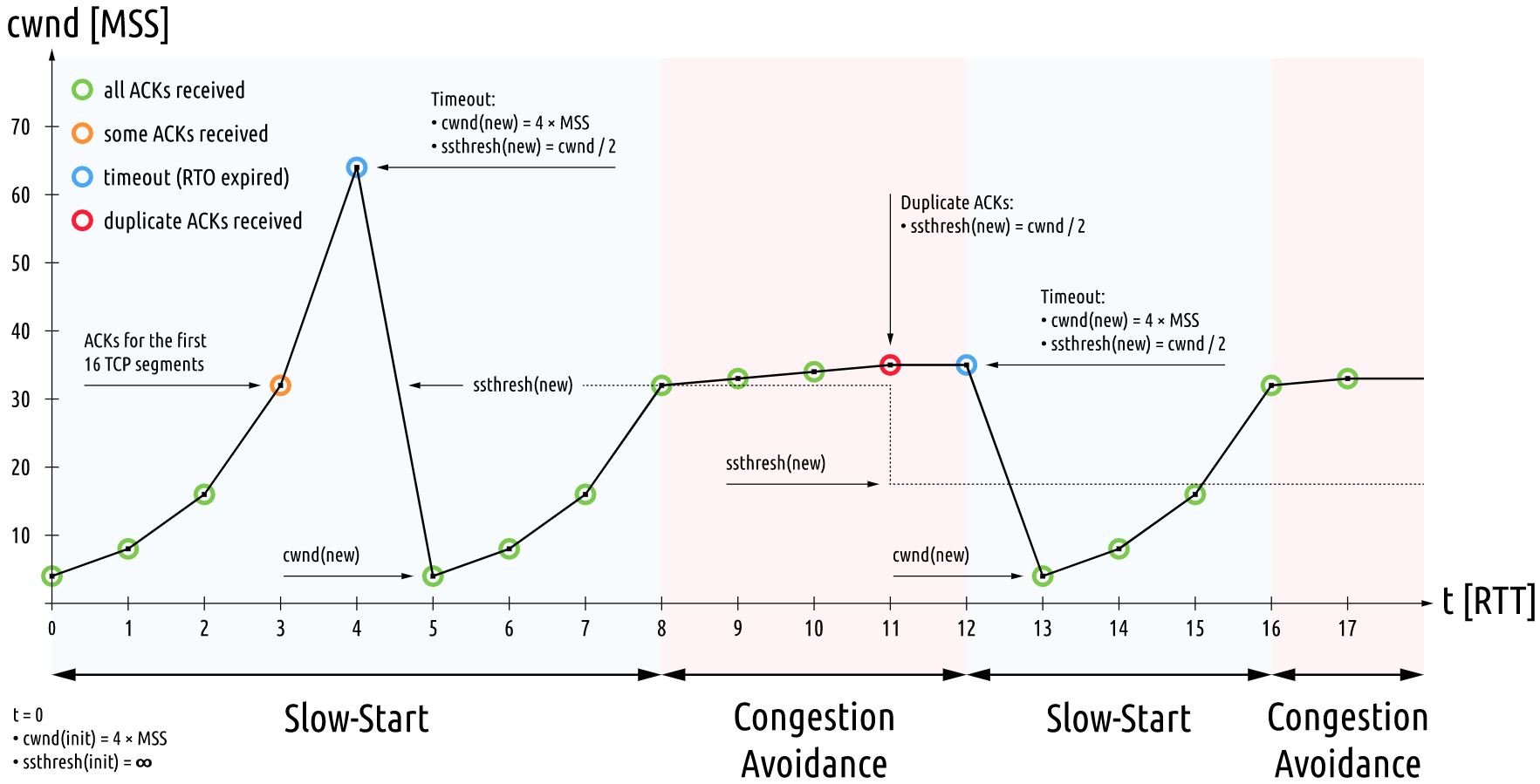
下面这张图,将慢启动、拥塞控制、拥塞发生、快速重传和超时重传各个不同的状态值,很好地展示了出来。