Introduction
Buttondown is a Django app for sending emails, mostly beloved by technical users who like its REST API and Markdown support. Like most other email platforms, it also hosts archives of sent emails, and these archives process a millions of pageviews every month in traffic.
These archive pages are classical Django detail views: here is an example of one. You can see from the URL that the contract is pretty simple: given a username and a slug, return the email. Simple enough!
I noticed that Google Search Console was dinging Buttondown for a slow TTFB: Buttondown's archive pages were averaging around 1.2s, and the guidance is to be below one second. These views are pretty uncomplicated, so I dove in with Django Debug Toolbar (ol' faithful) to see what was happening:

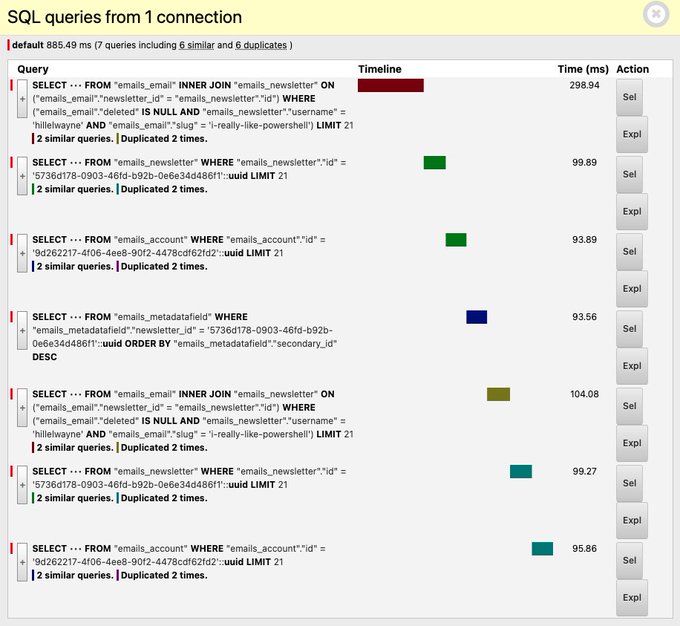
Nine queries! Yikes! DDT is kind enough to provide all of the information you really need: what queries are being run, which ones are repeated, and in what order. Let's dive in, shall we?
Removing unnecessary joins
This is obvious when you say it out loud: the easiest queries to optimize are the ones that you can straight up remove because they're entirely unnecessary. In this case, I had two such queries:
- A query on
monetization_stripeaccount - A query on
monetization_stripe_payment_link
Both of these pull data from Buttondown's mirrored store of Stripe data, and are entirely unnecessary on this page: we don't surface the payment link directly to users on this route, nor do we need information about the author's Stripe account. So we remove them from the serializer that was pulling them in:
class PublicNewsletterSerializer(serializers.ModelSerializer):
- stripe_account = serializers.SerializerMethodField()
- stripe_payment_link = serializers.SerializerMethodField()
...
- def get_stripe_payment_link(self, obj: Newsletter) -> str:
- if not obj.stripe_payment_link:
- return ""
- return obj.stripe_payment_link.data["url"]
- def get_stripe_account(self, obj: Newsletter) -> str:
- if not obj.stripe_account:
- return ""
- return obj.stripe_account.account_id
...
class Meta:
fields = (
...
- "stripe_account",
- "stripe_payment_link",
...
)
Excellent! We're already down to seven queries, as confirmed by DDT:
Caching the object on the view
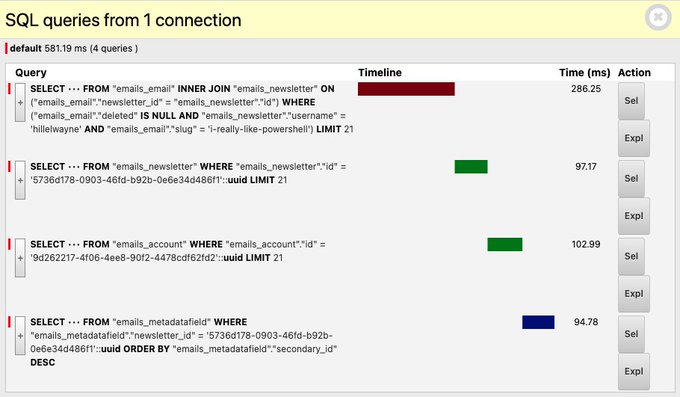
DDT helpfully informs us that some of these queries are duplicated: we grab the email, newsletter, and account twice. This is because of some janky logic I have in the permissions-checking for a given email: we show a slightly different version of the email depending on who's logged in (a premium subscriber may see different data compared to an unpaid one, for instance, or the author may be able to see posts that aren't published yet.)
Rather than fetching the email twice, then, let's just cache the email the first time it's fetched:
@method_decorator(xframe_options_exempt, name="dispatch")
class EmailView(TemplateView):
def get_template_names(self) -> List[str]:
- return determine_template_path(self.request, self.get_object())
+ return determine_template_path(self.request, self.email)
def get_username(self) -> str:
if hasattr(self.request, "newsletter_for_subdomain"):
@@ -89,7 +89,8 @@ def get_object(self) -> Optional[Email]:
email_slug = self.kwargs.get("slug")
username = self.get_username()
- return find_email(email_id or email_slug or "", username)
+ self.email = find_email(email_id or email_slug or "", username)
+ return self.email
def get_context_data(self, **kwargs: Any) -> Dict:
context = super().get_context_data(**kwargs)
That brings us down to a mere four queries:
Denorming with select_related
If you look at those top three queries, it sounds fairly obvious what they're doing:
- Grab the email for a given slug and username.
- Grab the newsletter for that email.
- Grab the account for that newsletter.
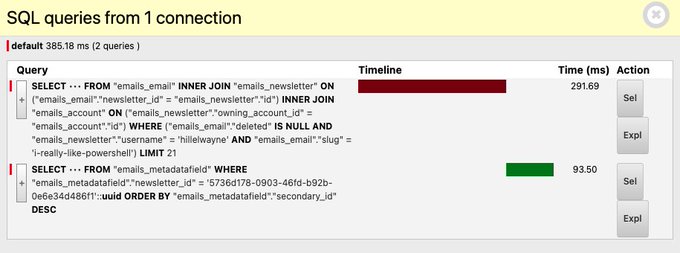
These are all part of the same object, so we can use Django's select_related method to pull in those foreign keys as part of the initial query.
- return emails.get(**kwargs)
+ return emails.select_related("newsletter__owning_account").get(**kwargs)
And with that one-liner, we're down to 385ms across only two queries:
Using defer
We're down to just two queries, but one of them is fairly large — 300ms for a simple join on an index seems awfully large, right?
Well, here's a fun bit of esoterica about Buttondown's implementation: Email objects are large. They contain a bunch of different cached versions of themselves, like:
- How the email should look as a 'teaser'
- How the email should look on email
- How the email should look in Markdown
and so on, to make sending emails as quick as possible. But — especially for larger emails — these add up in size, and the simple act of serializing them from Postgres to Python is non-trivially slow.
This is compounded by the fact that Django's ORM defaults to the equivalent of a select * — if you fetch a row, you're getting all of the columns included in that row.
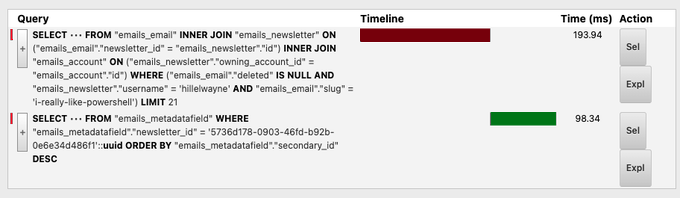
So, as a final touch, we use Django's defer command which allows us to selectively exclude certain fields that we know we don't need (in this case, it's various versions of the email that are rendered for other views):
- return emails.select_related("newsletter__owning_account").get(**kwargs)
+ return emails.select_related("newsletter__owning_account").defer(
+ "rendered_html_for_email",
+ "rendered_html_for_web",
+ "body",
+ ).get(**kwargs)
That saves us another 100ms, bringing us down to around 300ms!
Conclusion
We started with a view that took 1050ms across nine queries and we ended up with one that took 300ms across two queries. Pretty excellent for an hour's work and ~thirty lines of code, considering this view gets hit a few million times a month.
It bears repeating that none of the techniques described above are particularly novel. None required extensive tooling beyond django-debug-toolbar; exactly zero rocket surgery was performed in the course of this optimization.
And yet! This code stuck around, unoptimized, for quite some time. There is so much performance work out there in so many applications that looks like the above: twenty-dollar bills, sitting there crumpled on the ground, waiting to be picked up.
To wit, there are other things I could probably do to get this endpoint even faster:
- That second query is checking to see if the newsletter being fetched has any "metadata fields" associated with it. Metadata fields are a bit of an edge case feature, and only around 15% of newsletters use them; I could add a field like
Newsletter.has_metadata_fieldsand check that before making the query, to eliminate it for the 85% of newsletters who don't use it at all. - The primary query to pull out an email and a newsletter would be slightly faster (~30ms) if I queried the newsletter by ID instead of username. I could keep a cache mapping usernames to IDs to take advantage of that.
And all of those are good ideas for different days — but I'm a sucker for performance work that ends up with negative lines of code added.