一条数据在更新过程当中,如果中途 mysql crash 了,mysql 是如何保证数据的一致性和持久性的?在这个过程中 mysql 的日志系统起到了至关重要的作用。本文将会介绍 mysql 中的 undo log、redo log 和 bin log 在这其中的作用。
在数据更新的时候,数据并不是实时同步到硬盘中,而是在一块缓存 buffer pool 中更新,如果缓存中没有查询到该数据,则从磁盘中加载到 buffer pool 中。
当然,缓存的作用是为了提高 IO 性能,可以通过将数据先保留在缓存中,然后在适当的时机,批量写入到硬盘中。
并且在查询数据时,先是从缓存中进行查询,不用去磁盘中查找,减少 IO 的操作,加快查询的速度。
我们知道 InnoDB 是支持事务的,在事务提交失败时,是会回滚到执行之前的状态,那么肯定是需要保存之前的状态才可以进行恢复的,这个就是通过 undo log 来实现的。
在数据写入 buffer pool 的同时会将更新前的数据保存在 undo log 中,通过该日志语句便可以在事务回滚时,恢复到之前的状态。
再回到 buffer pool ,因为它是缓存,是在内存中,所有它的缺点也显而易见,那就是当服务器宕机中,缓存中的数据会丢失,那么 mysql 是如何保证数据的持久性呢?这个时候就要来介绍介绍 redo log 了。
在数据更新到 buffer pool 后,这个时候会将更新后的数据记录到 redo log buffer 中,这个也是一个缓存区,它当然也具备了缓存优缺点,并且默认是在提交事务的时候写入到 redo log 中,刷盘的策略可以根据 innodb_flush_log_at_trx_commit 来设置
因为 redo log 是顺序写入,所以 IO 性能不会太差。
当 buffer pool 中的数据还没有写入到磁盘中时,发生了宕机,当 mysql 重启时,会读取已经持久化 redo log 中的数据,再恢复到 buffer pool 中。
在开启事务准备更新一条记录时,InnoDB 会先在 buffer pool 中更新数据,然后将更新后的数据记录到 redo log buffer 中,这也是一个缓存。当然这个时候也是会发生宕机,但是没关系,如果该部分数据丢失,则认为该次事务提交失败,数据会恢复到之前的状态。
redolog 是由多个固定大小的文件组成的一个环形结构,并在这个环形结构中不断的写入与覆盖的过程。
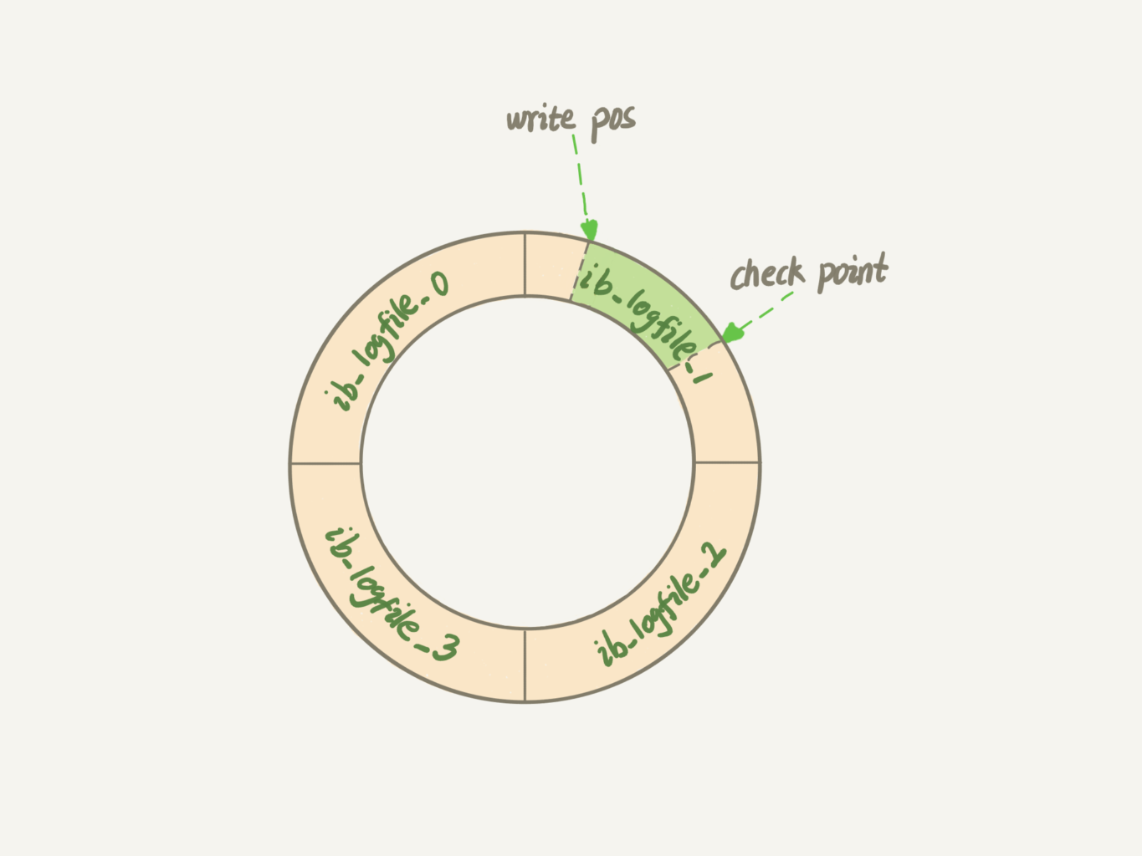
当有新的 redo log 写入时,从 wirte pos 位置往后写,而 check point 是上一次已经刷入磁盘的数据的位置,也是要不断的往后推进,然后将数据刷入磁盘中。
是在 mysql 层级记录的日志,主要是用于主从复制和数据恢复,可以通过某个时间的全量备份+binlog 来恢复到任意时间内的状态。
和 redo log 的区别
| 性质 | redo log | bin log | |
|---|---|---|---|
| 实现 | innodb 独有实现 | mysql server 层级实现,所有的引擎都可以使用 | |
| 内容 | 物理 log, 记录的是“在某个数据页上做了什么修改” | 逻辑 log,给 ID=2 这一行的 c 字段加 1 | |
| 写入 | 循环写入 | 追加写,写到一定大小切换下一个文件继续写 | |
| 应用 | 崩溃恢复(crash-safe) | 主从同步,数据恢复 |
为什么需要两阶段提交?
是为了让 redo log 和 bin log 保持逻辑一致性。
因为 redo log 写完了,所以即使系统崩溃,也可以恢复数据,但是 bin log 没写完 crash 了,这个时候 bin log 中少了该条语句,因此数据备份的时候,如果使用了该份 bin log 则会少一次更新。
因为 redo log 没写完,所以该事务没有生效,但是 binlog 中已经有该条记录,所以使用 bin log 时,会多出一个事务,与原来的数据不一致。
所以使用两阶段提交可以解决上面两种场景。
两阶段提交的实现逻辑
通过 prepare 和 commit 两种状态来完成两阶段的提交实现。
验证两阶段提交
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。