Semantic caching promises to make AI systems faster and cheaper by reducing duplicate calls to large language models (LLMs). But what happens when it doesn’t work as expected?
We built a test environment to find out. Through a caching system, we evaluated how semantically similar queries would behave. When the cache worked, response times were fast. When it didn’t, things got expensive. In fact, a single semantic cache miss increased latency by more than 2.5x. These failures didn’t show up in the API logs. But they cost real time and real money.
This blog shares our findings, why semantic caching matters, what causes it to fail, and how to monitor it effectively.
Traditional caching stores responses based on exact matches. If you’ve asked the same question before—verbatim—you’ll get a fast answer from cache. But if you phrase it differently, even slightly, it’s treated as a brand-new request.
Semantic caching is different. Instead of matching by text, it matches by meaning.
It uses embeddings—numerical representations of the intent behind a query—to determine whether a new request is close enough to a previous one. If two queries are semantically similar, the system can return the same result without reprocessing it through the LLM.
This is especially useful in AI systems where users might ask the same thing in dozens of ways. With semantic caching, “Who’s the President of the US?” and “Who runs America?” can trigger the same cached response—saving time, compute, and cost.
Agentic AI systems don’t just respond to commands—they plan, reason, and act across multiple steps. Each of those steps often involves an LLM call: retrieving documents, rephrasing responses, or deciding what to do next.
The problem? LLM calls are expensive, especially when repeated across variations of the same question.
Instead of reprocessing every variation of a query, it can reuse results from previous, similar requests—so long as the meaning is close enough.
That’s where things get risky: in an agentic AI world, a silent failure in semantic caching doesn’t just mean a slower API call—it can derail entire multistep AI workflows. When semantic cache misses occur, queries go straight to the backend LLM—creating higher latency and skyrocketing costs. Worse yet, these failures are often invisible.
Your API returns a 200 OK, but behind the scenes, your cost and performance are suffering.
Bottom line: Unlike traditional caching, semantic caches introduce new risks:
To experiment with how semantic caching affects user experience and infrastructure cost, we built a testing lab environment locally.
Here’s how it worked:
We configured a Catchpoint test to simulate user queries to our public endpoint URL. The test:
This gave us real evidence of how semantic caching reduces API calls to the expensive LLM backend and improves response times—insights we could quantify directly in the Catchpoint Internet Performance Monitoring (IPM) portal.
Below, are some helpful insights from our testing.
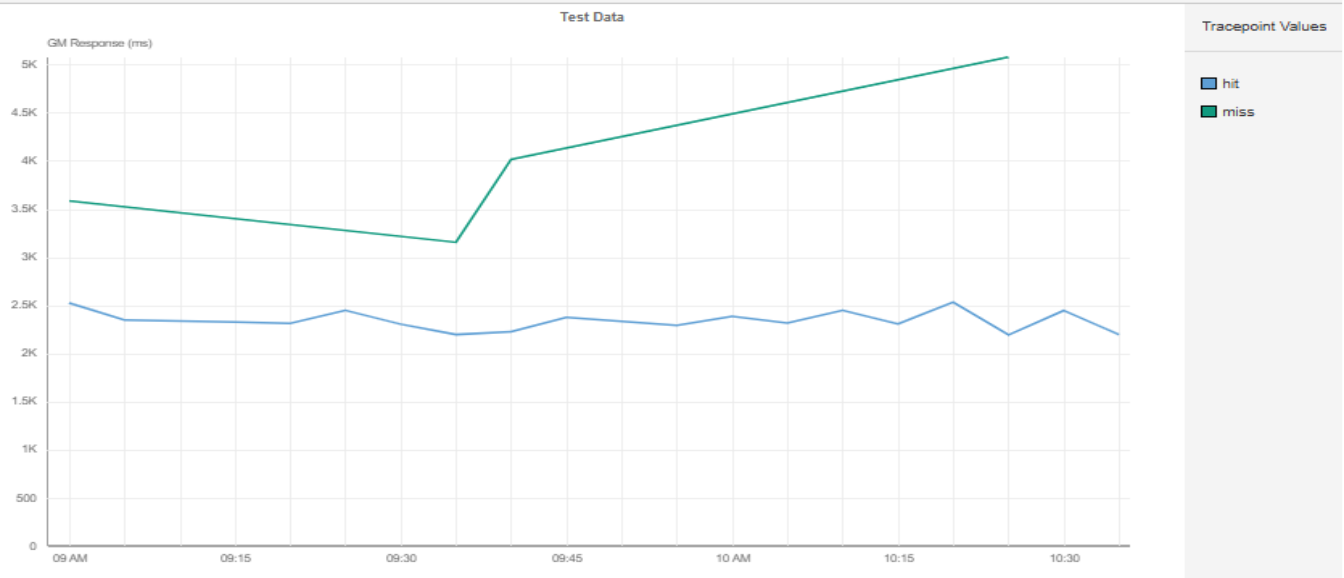
The trend line in the graph above shows that overall, the response time was about 50% to 250% higher when semantic cache returned a MISS compared to a HIT.
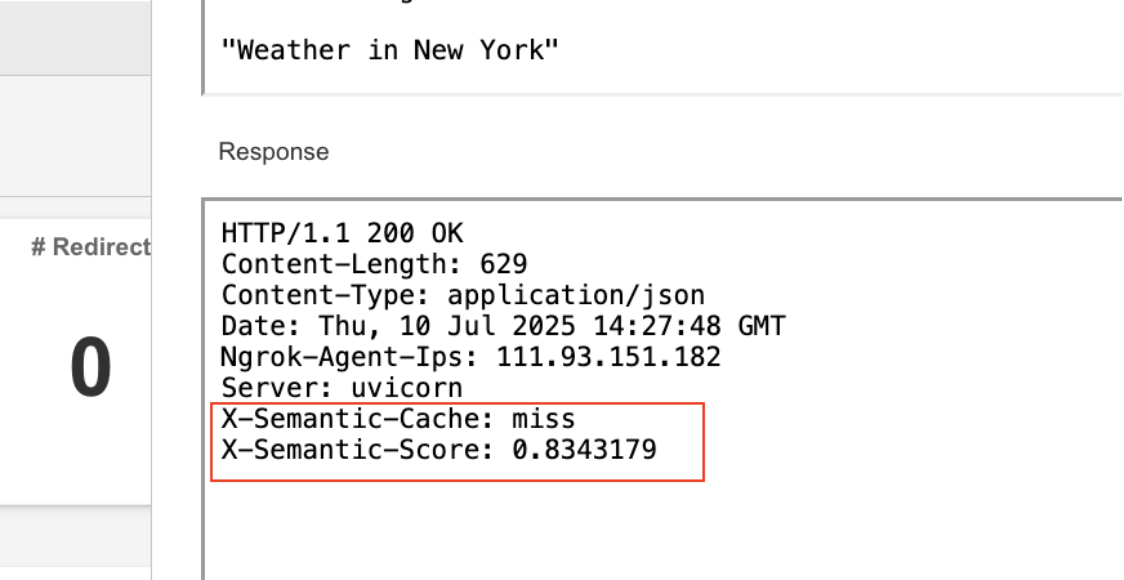
Diving deeper, we observed that the first run of a prompt went to the backend (a cache miss), with higher latency and costs.
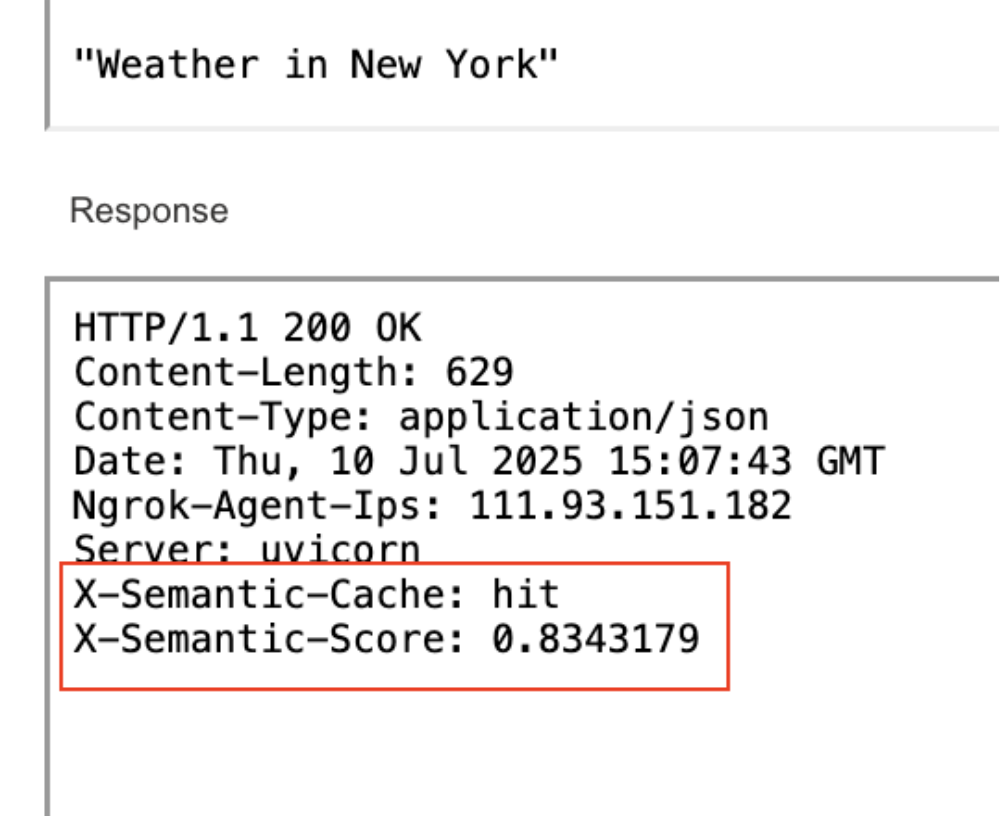
The second run of the same semantic query hit the cache, cutting response times by 50%.

Semantic caching is no longer a background optimization—it’s a core pillar of agentic AI systems that reason and act in real-time. But to trust it, we need to measure how well it’s working.
Here are three ways to monitor and improve its reliability:
Semantic caching lives or dies on how well it matches similar questions. Use synthetic monitoring to simulate different phrasings of the same intent:
Then compare their outcomes:
This gives you visibility into whether your caching system is recognizing intent consistently. For agentic AI, it’s not enough for one query to be fast. You need confidence that all user expressions of the same intent are covered.
Semantic caches often return a similarity score (e.g. 0.85) to indicate how close the new query is to an existing cached answer. If your cache system returns a similarity score (e.g. 0.8343), you can:
For instance, in our tests, both requests returned the same semantic score of 0.85224825.
But if the model changes or query phrasing drifts, scores could drop, leading to unexpected misses and rising costs.
Monitoring these numbers ensures your semantic cache stays reliable—and that you’re not wasting money on backend calls unnecessarily.
One of the biggest promises of semantic caching is speed. Cache hits should be significantly faster than misses.
Monitoring this can:
From our test results:
That’s a 2.5x speedup. In the world of agentic AI, that gap is the difference between a seamless conversation—and a frustrating pause.
Semantic caching isn’t just a nice-to-have—it’s becoming core infrastructure for real-time AI systems. Cloud leaders like Fastly, AWS, and Azure are already baking it into their architectures. But it’s also uniquely fragile. Changes in language, embedding drift, or model updates can quietly degrade performance.
By combining semantic caching with IPM, teams can ensure that their systems are not only fast—but reliably so.
If you're running AI agents at scale, silent cache failures aren't just inefficiencies. They're risks. Measure them, monitor them, and mitigate them.
Learn more:
Semantic caching can make AI systems faster and cheaper by reusing results for similar queries instead of reprocessing them with expensive LLM calls. But when it silently fails—due to phrasing differences, model updates, or vector drift—it can drastically increase latency and costs without warning. In our test lab, a single cache miss slowed responses by 2.5x. This post explores why semantic caching is essential for agentic AI, how it can fail, and how to monitor and improve it to avoid hidden performance and cost issues.
Semantic caching promises to make AI systems faster and cheaper by reducing duplicate calls to large language models (LLMs). But what happens when it doesn’t work as expected?
We built a test environment to find out. Through a caching system, we evaluated how semantically similar queries would behave. When the cache worked, response times were fast. When it didn’t, things got expensive. In fact, a single semantic cache miss increased latency by more than 2.5x. These failures didn’t show up in the API logs. But they cost real time and real money.
This blog shares our findings, why semantic caching matters, what causes it to fail, and how to monitor it effectively.
Traditional caching stores responses based on exact matches. If you’ve asked the same question before—verbatim—you’ll get a fast answer from cache. But if you phrase it differently, even slightly, it’s treated as a brand-new request.
Semantic caching is different. Instead of matching by text, it matches by meaning.
It uses embeddings—numerical representations of the intent behind a query—to determine whether a new request is close enough to a previous one. If two queries are semantically similar, the system can return the same result without reprocessing it through the LLM.
This is especially useful in AI systems where users might ask the same thing in dozens of ways. With semantic caching, “Who’s the President of the US?” and “Who runs America?” can trigger the same cached response—saving time, compute, and cost.
Agentic AI systems don’t just respond to commands—they plan, reason, and act across multiple steps. Each of those steps often involves an LLM call: retrieving documents, rephrasing responses, or deciding what to do next.
The problem? LLM calls are expensive, especially when repeated across variations of the same question.
Instead of reprocessing every variation of a query, it can reuse results from previous, similar requests—so long as the meaning is close enough.
That’s where things get risky: in an agentic AI world, a silent failure in semantic caching doesn’t just mean a slower API call—it can derail entire multistep AI workflows. When semantic cache misses occur, queries go straight to the backend LLM—creating higher latency and skyrocketing costs. Worse yet, these failures are often invisible.
Your API returns a 200 OK, but behind the scenes, your cost and performance are suffering.
Bottom line: Unlike traditional caching, semantic caches introduce new risks:
To experiment with how semantic caching affects user experience and infrastructure cost, we built a testing lab environment locally.
Here’s how it worked:
We configured a Catchpoint test to simulate user queries to our public endpoint URL. The test:
This gave us real evidence of how semantic caching reduces API calls to the expensive LLM backend and improves response times—insights we could quantify directly in the Catchpoint Internet Performance Monitoring (IPM) portal.
Below, are some helpful insights from our testing.
The trend line in the graph above shows that overall, the response time was about 50% to 250% higher when semantic cache returned a MISS compared to a HIT.
Diving deeper, we observed that the first run of a prompt went to the backend (a cache miss), with higher latency and costs.
The second run of the same semantic query hit the cache, cutting response times by 50%.
Semantic caching is no longer a background optimization—it’s a core pillar of agentic AI systems that reason and act in real-time. But to trust it, we need to measure how well it’s working.
Here are three ways to monitor and improve its reliability:
Semantic caching lives or dies on how well it matches similar questions. Use synthetic monitoring to simulate different phrasings of the same intent:
Then compare their outcomes:
This gives you visibility into whether your caching system is recognizing intent consistently. For agentic AI, it’s not enough for one query to be fast. You need confidence that all user expressions of the same intent are covered.
Semantic caches often return a similarity score (e.g. 0.85) to indicate how close the new query is to an existing cached answer. If your cache system returns a similarity score (e.g. 0.8343), you can:
For instance, in our tests, both requests returned the same semantic score of 0.85224825.
But if the model changes or query phrasing drifts, scores could drop, leading to unexpected misses and rising costs.
Monitoring these numbers ensures your semantic cache stays reliable—and that you’re not wasting money on backend calls unnecessarily.
One of the biggest promises of semantic caching is speed. Cache hits should be significantly faster than misses.
Monitoring this can:
From our test results:
That’s a 2.5x speedup. In the world of agentic AI, that gap is the difference between a seamless conversation—and a frustrating pause.
Semantic caching isn’t just a nice-to-have—it’s becoming core infrastructure for real-time AI systems. Cloud leaders like Fastly, AWS, and Azure are already baking it into their architectures. But it’s also uniquely fragile. Changes in language, embedding drift, or model updates can quietly degrade performance.
By combining semantic caching with IPM, teams can ensure that their systems are not only fast—but reliably so.
If you're running AI agents at scale, silent cache failures aren't just inefficiencies. They're risks. Measure them, monitor them, and mitigate them.
Learn more:
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。