Today’s enterprises don’t run on singular self-contained systems—they’re intricate webs of interdependence: cloud services, APIs, CI/CD tools, DNS, CDNs, SASE vendors, identity management providers, cloud interconnects, ISPs, SaaS applications, application components, microservices, etc. A recent industry survey found that 84% of organizations suffered operational disruption from third-party risk incidents, with 66% facing adverse financial impact.
This isn’t just about vendor contracts anymore; it’s about operational survival in an architecture where failures cascade through invisible dependency chains.
For SREs and CIOs, the challenge has shifted: you’re no longer just managing your infrastructure—you’re managing an ecosystem. Every external dependency is both a capability multiplier and a potential single point of failure.
Google defines toil as “work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows.”
Vendor-related tasks—such as manually verifying external dependencies, coordinating incident triage, and validating SLA claims—can contribute significantly to operational toil in modern environments.
Hidden operational tax from vendor mismanagement includes:
SRE teams report spending up to 50% of their time on operational tasks, with vendor-related incidents consuming an increasing share. Breaking this cycle requires observability that spans the entire Internet Stack.
The question then becomes: once you recognize vendor-related toil as a drag on engineering efficiency, what can you do about it? The next step is to evaluate vendors not just on their promises but on measurable trade-offs of cost, performance, and accountability.
When choosing a cloud provider, a secure remote access platform, an ISP to support a remote office or any other vendor, you need objective data to weigh cost against performance.
For example, a CDN provider may deliver median page load times of 520 ms in North America at an annual cost of $1 million, while a different vendor delivers 570 ms for $750,000. The latency difference is negligible, but the cost savings are substantial. You may decide to use two vendors or even take advantage of intelligent traffic steering.
You may find that your SASE vendor might not deliver an acceptable experience to your users in Europe and might need either a new SASE vendor or different vendors by region. And then you need to monitor continuously to ensure the SLA is maintained and the user experience is always what the business needs.
Internet Performance Monitoring (IPM) provides proactive visibility into the entire Internet Stack—including third-party services, protocols, and network infrastructure—to diagnose and resolve issues affecting application performance and user experience. IPM starts with the user experience (customer, employee, or an API consuming a service) from the real-world location where the user is located.
Unlike Application Performance Monitoring (APM), which focuses on the application itself, IPM is designed to understand the context where an application lives, including internal networks and resources, cloud services, networking and connectivity, all the way to the user.
Because one of the key differentiators of Catchpoint IPM is measuring performance from thousands of global vantage points across ISPs, clouds, and backbone providers, you can identify the most cost-effective vendor option in each region.
Here are a few ways IPM can make vendor selection more data-driven and accountable:
Catchpoint IPM can measure performance across on-premises, public, hybrid, and multi-cloud environments, helping you identify the most cost-effective option for the right global location.
To move from vendor selection into day-to-day accountability, teams need mechanisms to enforce performance commitments.
SLA service disputes can take a long time and lead to substantial financial payouts. Further, it can be hard to determine if the vendor or client has the strongest case without objective data. This ambiguity not only strains relationships but also poses a considerable financial burden on organizations.
IPM-powered SLA validation
With independent observability, you can minimize legal expenses, reduce operational disruptions, and ensure SLA compliance.
According to the 2024 SRE Report, SLA breaches are both widespread and costly.
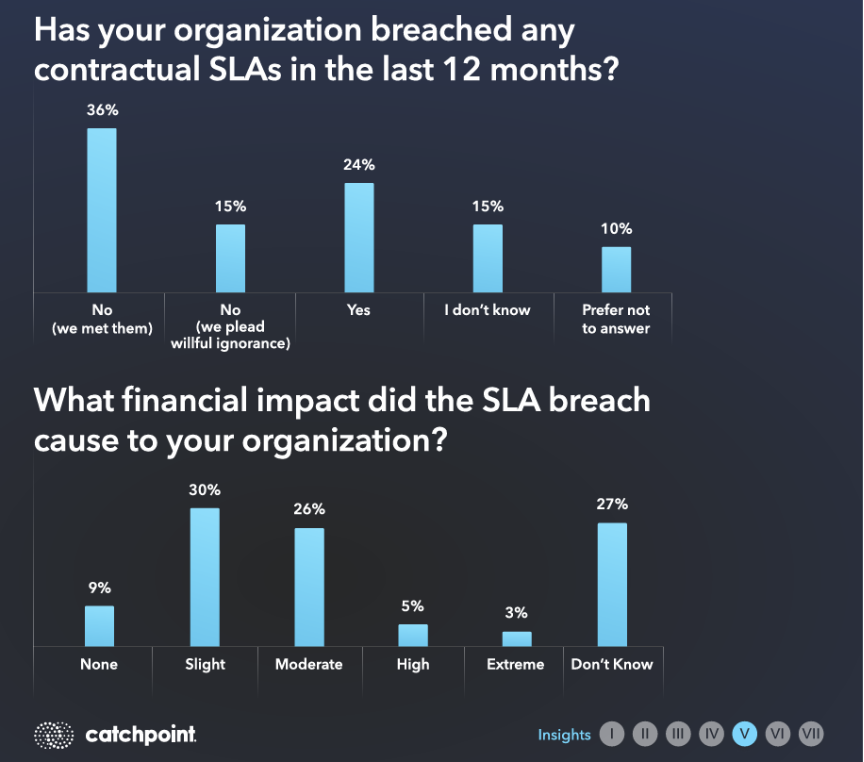
Nearly a quarter of organizations admitted breaching contractual SLAs in the past year, while another 15% said they didn’t know. Even more striking, over a quarter of respondents could not quantify the financial impact of those breaches, reflecting a major visibility gap. Without independent monitoring, organizations risk both underestimating and underreporting the true business cost of SLA violations.
The same accountability issues that complicate SLA enforcement also vary dramatically by geography. This makes it essential to move beyond global averages and examine performance at the regional and even city level, where user impact is most directly felt.
A global vendor’s reputation doesn’t guarantee local reliability. Time and again, our performance data reveals that even the largest cloud providers can show regional disparities in performance. Take the example below, which compares two major cloud providers’ latency by global region and by city. City-level analysis reveals “pockets of pain” invisible in global averages.

Side-by-side maps from the Catchpoint IPM portal showing latency variation by global region and city for two large cloud providers. One provider shows stronger performance in some regions while the other shows weaknesses, and both display a mix of strong and weak regions at the city level.
Key takeaways for IT teams:
If your business is truly global, choosing a vendor based solely on reputation or blanket SLAs is risky. Outages or latency issues that are “invisible” at the macro level can cause very real pain for specific user bases.
What challenges come with managing multiple vendors?
Different providers can vary in performance, reliability, and transparency. Without independent data, it’s difficult to compare them fairly or hold them accountable.
How does Catchpoint IPM support vendor selection and management?
IPM measures performance across the full Internet Stack, from cloud to ISP to end-user. This enables you to compare vendors objectively, validate SLAs, and make region-specific decisions based on real-world user experience.
Why not just rely on vendor dashboards?
Vendor-reported metrics typically reflect their own vantage points and may mask regional issues. Independent monitoring ensures neutrality and visibility into the actual experience of your customers and employees. With full visibility there is no finger pointing between vendors, or head scratching when a dashboard is all green but users still complain.
How can IPM help reduce costs?
By comparing performance and cost trade-offs across providers and regions, IPM helps identify where a slightly slower but significantly cheaper option won’t harm user experience, enabling smarter vendor spend.
What role does IPM play in preventing outages?
With thousands of vantage points worldwide, IPM can detect regional disruptions before they escalate, helping teams mitigate impact and maintain resilience.
In today’s complex digital ecosystem, relying solely on vendor-reported metrics is no longer sufficient. Independent, continuous monitoring is essential for accountable vendor management, resilient operations, and consistent digital experiences.
Catchpoint empowers organizations with objective insights into vendor performance, SLA compliance, incident response, and regional reliability—helping SREs and CIOs make smarter decisions.
Dig deeper:
Today’s enterprises don’t run on singular self-contained systems—they’re intricate webs of interdependence: cloud services, APIs, CI/CD tools, DNS, CDNs, SASE vendors, identity management providers, cloud interconnects, ISPs, SaaS applications, application components, microservices, etc. A recent industry survey found that 84% of organizations suffered operational disruption from third-party risk incidents, with 66% facing adverse financial impact.
This isn’t just about vendor contracts anymore; it’s about operational survival in an architecture where failures cascade through invisible dependency chains.
For SREs and CIOs, the challenge has shifted: you’re no longer just managing your infrastructure—you’re managing an ecosystem. Every external dependency is both a capability multiplier and a potential single point of failure.
Google defines toil as “work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows.”
Vendor-related tasks—such as manually verifying external dependencies, coordinating incident triage, and validating SLA claims—can contribute significantly to operational toil in modern environments.
Hidden operational tax from vendor mismanagement includes:
SRE teams report spending up to 50% of their time on operational tasks, with vendor-related incidents consuming an increasing share. Breaking this cycle requires observability that spans the entire Internet Stack.
The question then becomes: once you recognize vendor-related toil as a drag on engineering efficiency, what can you do about it? The next step is to evaluate vendors not just on their promises but on measurable trade-offs of cost, performance, and accountability.
When choosing a cloud provider, a secure remote access platform, an ISP to support a remote office or any other vendor, you need objective data to weigh cost against performance.
For example, a CDN provider may deliver median page load times of 520 ms in North America at an annual cost of $1 million, while a different vendor delivers 570 ms for $750,000. The latency difference is negligible, but the cost savings are substantial. You may decide to use two vendors or even take advantage of intelligent traffic steering.
You may find that your SASE vendor might not deliver an acceptable experience to your users in Europe and might need either a new SASE vendor or different vendors by region. And then you need to monitor continuously to ensure the SLA is maintained and the user experience is always what the business needs.
Internet Performance Monitoring (IPM) provides proactive visibility into the entire Internet Stack—including third-party services, protocols, and network infrastructure—to diagnose and resolve issues affecting application performance and user experience. IPM starts with the user experience (customer, employee, or an API consuming a service) from the real-world location where the user is located.
Unlike Application Performance Monitoring (APM), which focuses on the application itself, IPM is designed to understand the context where an application lives, including internal networks and resources, cloud services, networking and connectivity, all the way to the user.
Because one of the key differentiators of Catchpoint IPM is measuring performance from thousands of global vantage points across ISPs, clouds, and backbone providers, you can identify the most cost-effective vendor option in each region.
Here are a few ways IPM can make vendor selection more data-driven and accountable:
Catchpoint IPM can measure performance across on-premises, public, hybrid, and multi-cloud environments, helping you identify the most cost-effective option for the right global location.
To move from vendor selection into day-to-day accountability, teams need mechanisms to enforce performance commitments.
SLA service disputes can take a long time and lead to substantial financial payouts. Further, it can be hard to determine if the vendor or client has the strongest case without objective data. This ambiguity not only strains relationships but also poses a considerable financial burden on organizations.
IPM-powered SLA validation
With independent observability, you can minimize legal expenses, reduce operational disruptions, and ensure SLA compliance.
According to the 2024 SRE Report, SLA breaches are both widespread and costly.
Nearly a quarter of organizations admitted breaching contractual SLAs in the past year, while another 15% said they didn’t know. Even more striking, over a quarter of respondents could not quantify the financial impact of those breaches, reflecting a major visibility gap. Without independent monitoring, organizations risk both underestimating and underreporting the true business cost of SLA violations.
The same accountability issues that complicate SLA enforcement also vary dramatically by geography. This makes it essential to move beyond global averages and examine performance at the regional and even city level, where user impact is most directly felt.
A global vendor’s reputation doesn’t guarantee local reliability. Time and again, our performance data reveals that even the largest cloud providers can show regional disparities in performance. Take the example below, which compares two major cloud providers’ latency by global region and by city. City-level analysis reveals “pockets of pain” invisible in global averages.
Side-by-side maps from the Catchpoint IPM portal showing latency variation by global region and city for two large cloud providers. One provider shows stronger performance in some regions while the other shows weaknesses, and both display a mix of strong and weak regions at the city level.
Key takeaways for IT teams:
If your business is truly global, choosing a vendor based solely on reputation or blanket SLAs is risky. Outages or latency issues that are “invisible” at the macro level can cause very real pain for specific user bases.
What challenges come with managing multiple vendors?
Different providers can vary in performance, reliability, and transparency. Without independent data, it’s difficult to compare them fairly or hold them accountable.
How does Catchpoint IPM support vendor selection and management?
IPM measures performance across the full Internet Stack, from cloud to ISP to end-user. This enables you to compare vendors objectively, validate SLAs, and make region-specific decisions based on real-world user experience.
Why not just rely on vendor dashboards?
Vendor-reported metrics typically reflect their own vantage points and may mask regional issues. Independent monitoring ensures neutrality and visibility into the actual experience of your customers and employees. With full visibility there is no finger pointing between vendors, or head scratching when a dashboard is all green but users still complain.
How can IPM help reduce costs?
By comparing performance and cost trade-offs across providers and regions, IPM helps identify where a slightly slower but significantly cheaper option won’t harm user experience, enabling smarter vendor spend.
What role does IPM play in preventing outages?
With thousands of vantage points worldwide, IPM can detect regional disruptions before they escalate, helping teams mitigate impact and maintain resilience.
In today’s complex digital ecosystem, relying solely on vendor-reported metrics is no longer sufficient. Independent, continuous monitoring is essential for accountable vendor management, resilient operations, and consistent digital experiences.
Catchpoint empowers organizations with objective insights into vendor performance, SLA compliance, incident response, and regional reliability—helping SREs and CIOs make smarter decisions.
Dig deeper:
This is some text inside of a div block.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。