Ask GPT-4 to recommend an underrated sci-fi film. It says Moon. Ask Claude the same question — also Moon. Try Gemini — Moon again. A NeurIPS 2025 Best Paper, Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond) , quantifies this phenomenon at scale: different language models give strikingly similar answers to open-ended questions.
Hivemind — a classic science fiction concept where a group of individuals shares a single consciousness. As a description of collective language model behavior, the term fits uncomfortably well.
The Infinity-Chat Dataset
Accuracy has MMLU. Safety has red-teaming benchmarks. But “how diverse are the answers?” has lacked a proper evaluation tool. The paper fills this gap with Infinity-Chat: 26,000 real user queries with no single correct answer, paired with 31,250 human annotations (25 independent annotators per example). These are questions like “recommend an obscure hobby,” “write a poem about loneliness,” or “help me brainstorm a startup idea.” The dataset also introduces a taxonomy of open-ended prompts — 6 top-level categories, 17 subcategories — covering everything from brainstorming to creative writing to roleplay.
One Question, 1,250 Responses, Two Clusters
The experimental design is straightforward: 25 mainstream models (70+ tested in total, 25 representative ones reported in the main paper), each generating 50 responses per query (top-p = 0.9, temperature = 1.0), with pairwise sentence embedding similarity computed across responses.
The PCA visualization below is the most striking result. The prompt is “Write a metaphor about time.” 1,250 responses from 25 models projected into two dimensions form just two clusters: nearly every model converges on either “time is a river” or “time is a weaver.”
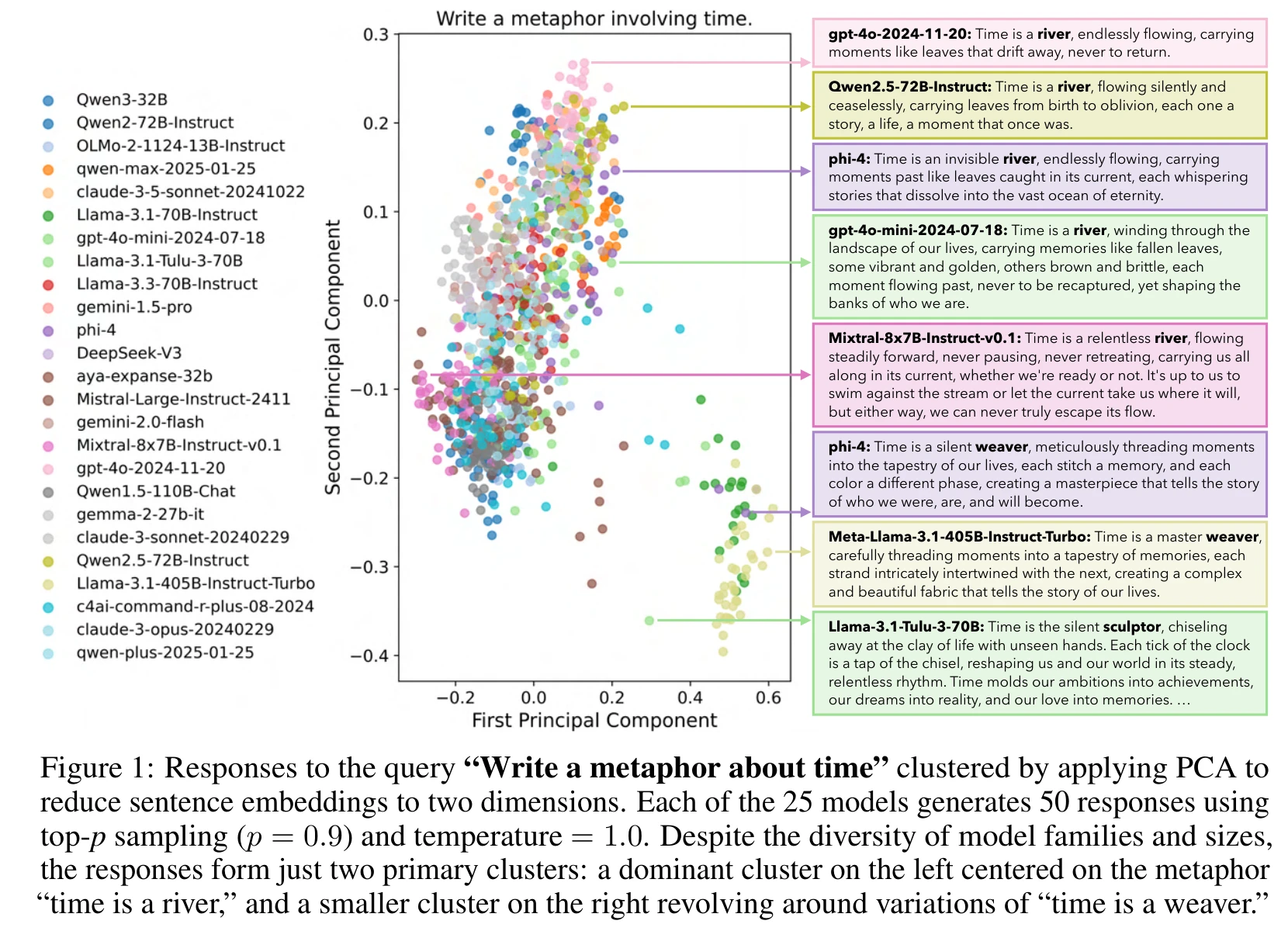
This is a single-query visualization (the quantitative analysis covers 100 queries), but it already shows the severity of the problem.
Intra-Model Repetition: Sampling Strategies Don’t Help Much
When the same model answers the same question repeatedly, response pairs exceed 0.8 embedding similarity in 79% of cases — at temperature = 1.0, already on the high end of typical usage.
The paper also evaluates min-p decoding (top-p = 1.0, min-p = 0.1, temperature = 2.0), a dynamic sampling strategy designed specifically to increase diversity. Extreme repetition (similarity > 0.9) decreases somewhat, but 81% of response pairs still exceed 0.7 and 61.2% exceed 0.8. Cranking up the temperature and switching sampling algorithms yields limited improvement. The paper concludes that more fundamental solutions need to be found at the model training level rather than the decoding level.
The Cross-Model Hivemind Effect
The more counterintuitive finding concerns inter-model behavior. Models from different companies with different architectures still produce highly overlapping outputs on open-ended questions.
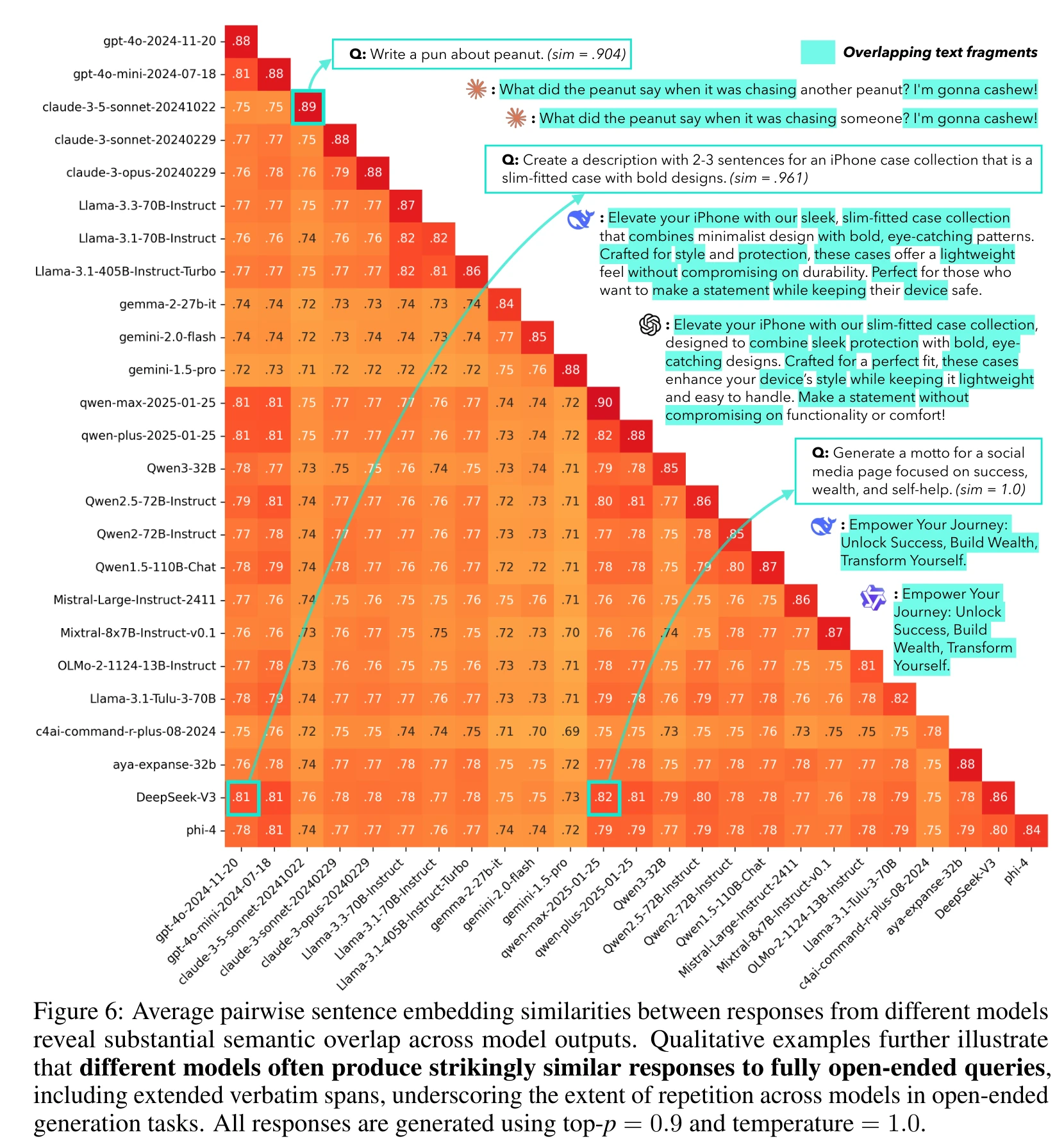
Some specific numbers: DeepSeek-V3 and qwen-max reach 0.82 cross-model similarity, DeepSeek-V3 and GPT-4o reach 0.81, with the overall range spanning 0.71 to 0.82. The paper notes that GPT and Qwen model families tend to show higher similarity with other families, possibly due to shared data pipelines across regions or synthetic data contamination, though exact causes remain unverifiable given proprietary training details.
Verbatim overlaps are even more telling. For “write a 2-3 sentence description of an iPhone case collection,” DeepSeek-V3 and GPT-4o produce responses sharing exact phrases: “Elevate your iPhone with our,” “sleek, without compromising,” “with bold, eye-catching.” For a social media motto about success, wealth, and self-help, qwen-max and qwen-plus generate identical responses (similarity = 1.0).
The paper includes another clever validation: for each query, take the 50 most similar responses and count how many distinct models they come from. If models were sufficiently diverse, all top-50 should come from a single model’s repeated sampling. The actual result averages about 8 unique models, with some queries exceeding 10 — outputs from different models have become indistinguishable.
It is worth noting that the paper uses sentence embedding similarity as the primary metric. This measure is more sensitive to surface-level phrasing than to deep semantic differences, potentially overstating certain types of homogeneity. That said, the verbatim overlap examples suggest the homogeneity is not merely a measurement artifact.
Causes of Homogeneity and Reward Model Miscalibration
The paper explicitly states it does not perform causal analysis but identifies several directions for future investigation: pretraining data overlap, the impact of alignment processes, and memorization and contamination. Drawing on existing literature, highly overlapping training data sources, RLHF preference optimization that systematically discards minority tastes, and the accumulation of synthetic data across training generations are all plausible contributing factors.
The paper’s more direct empirical contribution is exposing reward model calibration issues. With 25 annotators per example in Infinity-Chat, the annotation density is sufficient to reveal the true shape of human preference distributions.
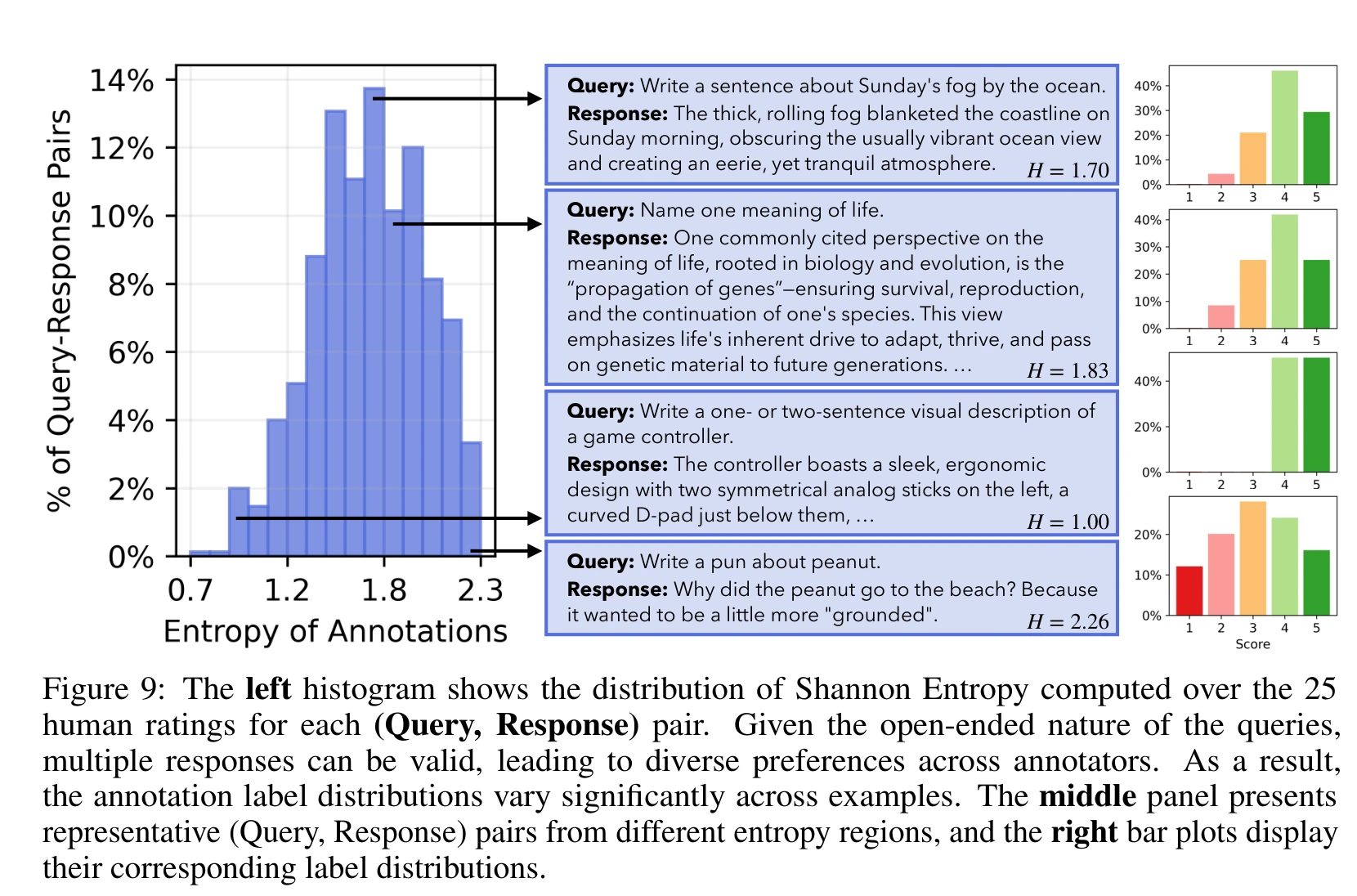
On questions where annotators agree, reward model calibration is reasonable. On questions with high annotator disagreement — which happen to be the norm for open-ended queries — calibration drops noticeably. The paper observes this across perplexity scores from 56 language models, 6 top-ranked RewardBench reward models, and 4 LLM judges (including GPT-4o and Prometheus variants).
The connection to homogeneity is clear: RLHF trains models using aggregated preference signals, effectively compressing the multi-modal distribution of human taste into a single peak. You prefer classical music, I prefer experimental electronic — after training, the model recommends pop jazz to everyone. Nobody hates it, nobody loves it. And reward models are least reliable precisely when they need to distinguish between “both good but different” responses — providing a biased signal source to the very training process that drives homogenization.
Long-Term Risks of the Hivemind
Getting the same movie recommendation everywhere is a minor annoyance. But language models are entering domains that demand diversity: drafting proposals, supporting decisions, participating in education. The paper frames this as “long-term AI safety risks” — not the risk of models becoming too powerful to control, but the subtler risk that prolonged interaction with homogenized thinking tools gradually narrows users’ own cognitive frameworks.
The paper’s main contribution is diagnostic rather than prescriptive. Several directions are visible: moving preference modeling from aggregation toward personalization, decontaminating training data from synthetic text, and addressing diversity at the training level rather than the decoding level. Optimizing a space that should have a multi-modal distribution using scalar reward signals makes diversity loss hard to avoid — a structural tension that the current alignment paradigm may need to confront.
All language models share one hivemind aesthetic, blended from average internet taste and median annotator preference. Next time you ask AI to help brainstorm a creative proposal, remember that your competitors are working with more or less the same hive.