Dense retrieval has become the default first stage in RAG pipelines. Encode documents into vectors, encode queries into vectors, compute cosine similarity, done. But a basic question rarely gets asked: for a d-dimensional embedding, how many distinct top-k retrieval results can it actually represent?
An ICLR 2026 paper from Google DeepMind and JHU, “On the Theoretical Limitations of Embedding-Based Retrieval”, gives a mathematical answer: not enough. Not even close.
Paper: arxiv.org/abs/2508.21038
The Dimension Lower Bound
Start with the combinatorics. Given n documents and top-k retrieval, the total number of possible top-k subsets is $\binom{n}{k}$. This grows extremely fast as n and k increase.
For each top-k subset to be “realized,” there must exist some query vector whose dot product with the k relevant documents exceeds all others by a margin $\gamma$. The paper’s Theorem 1 proves:
$$d \geq \frac{\log \binom{n}{k}}{\log(1 + 1/\gamma)}$$
The interpretation is straightforward: to represent all possible top-k combinations, the embedding dimension d must be at least this large.
Plugging in $\gamma = 0.1$:
| Docs (n) | k=2 | k=10 | k=100 | k=1000 |
|---|---|---|---|---|
| $10^3$ | 6 | 23 | 135 | — |
| $10^5$ | 10 | 42 | 329 | 2334 |
| $10^7$ | 14 | 61 | 521 | 4257 |
| $10^9$ | 17 | 81 | 713 | 6177 |
The largest embedding dimension in current SOTA models is 4096 (Qwen3 Embed), with many deployments truncating to 1024 or lower via Matryoshka representation learning. At n in the millions and k=100, the theoretical lower bound already approaches or exceeds 4096. And this is an extremely loose lower bound.
Free Embeddings: Best-Case Performance
The theorem gives a floor. Real models face additional constraints from gradient descent, tokenization, and language modeling. How much worse is reality?
The paper designs a “free embedding” experiment: skip the language model entirely. Treat query and document vectors as directly optimizable parameters, and run gradient descent (Adam + InfoNCE loss) on the test-set qrel matrix. This is the theoretical best case, since the vectors can be placed anywhere in space without natural language constraints.
With k=2, they increase n until the optimization can no longer achieve 100% recall. This breaking point is the critical-n for each dimension d.
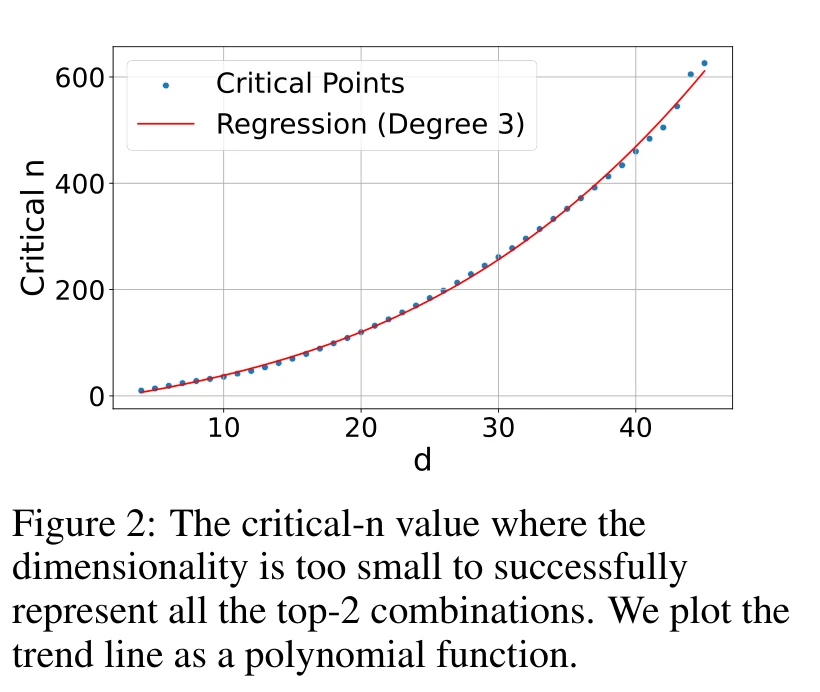
The curve fits a cubic polynomial $y = -10.53 + 4.03d + 0.052d^2 + 0.0037d^3$ with $r^2 = 0.999$. Extrapolating to practical dimensions:
- d=512 → critical-n ≈ 500k
- d=1024 → ≈ 4M
- d=3072 → ≈ 107M
- d=4096 → ≈ 250M
These numbers look large, but remember: this is k=2 only, directly optimizing on the test set with zero generalization requirement. Real models will hit the ceiling much sooner. The paper confirms this: the theoretical lower bound says d=4 suffices for n=100, but free embeddings actually need d>18, a 4.5x multiplier even without any language modeling constraints.
The LIMIT Dataset: Trivial Queries, Total Failure
Theory and free embeddings are abstract. To test real models on real text, the paper constructs the LIMIT dataset.
The setup is deliberately simple. Each document is a fictional person with random attributes: “Jon Durben likes Quokkas, Apples, and Scuba Diving.” Queries take the form “Who likes X?”, each with exactly 2 relevant documents (k=2).
Here’s the clever part: the paper wants to make the task as hard as possible, so it needs to cover all possible top-2 combinations. They select 46 core documents and assign each pair a unique attribute word — shared by exactly those two documents and no others. This produces $\binom{46}{2} = 1035$ queries, each targeting a distinct pair. The embedding model must distinguish all 1,035 different top-2 sets. On top of the 46 core documents, 49,954 distractor documents (unrelated to any query) are added, for a total of 50,000.

Any human can answer these queries at a glance. Here’s how SOTA embedding models do:
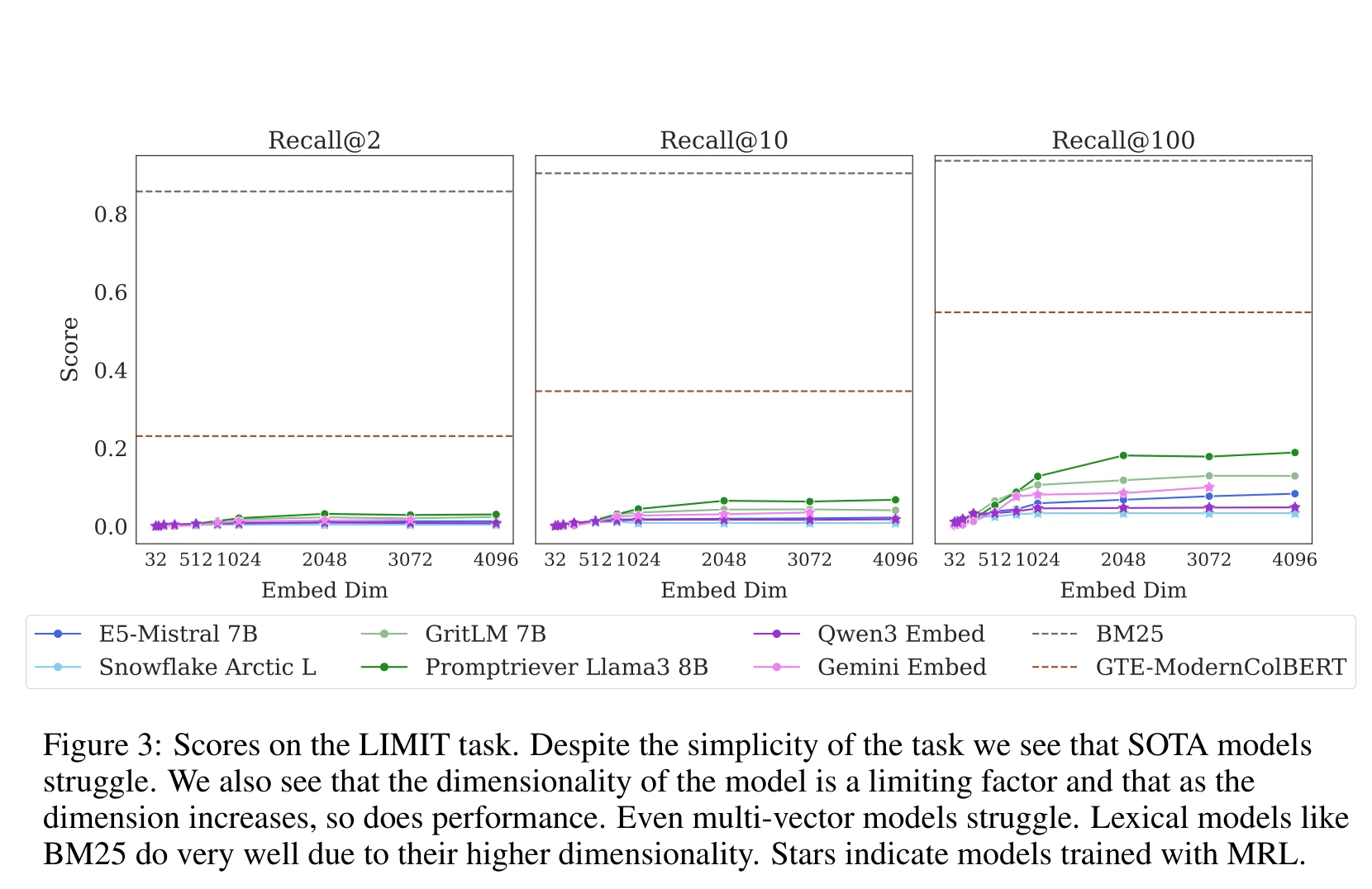
On the full 50k-document setting, every single-vector model scores below 5% Recall@2 — Promptriever 8B (4096 dimensions) manages just 3.0%, Qwen3 Embed only 0.8%. Even at Recall@100, the best reaches just 18.9%. For a task any human solves at a glance, the strongest embedding models nearly completely fail.
The small version (just 46 documents) is also bad:
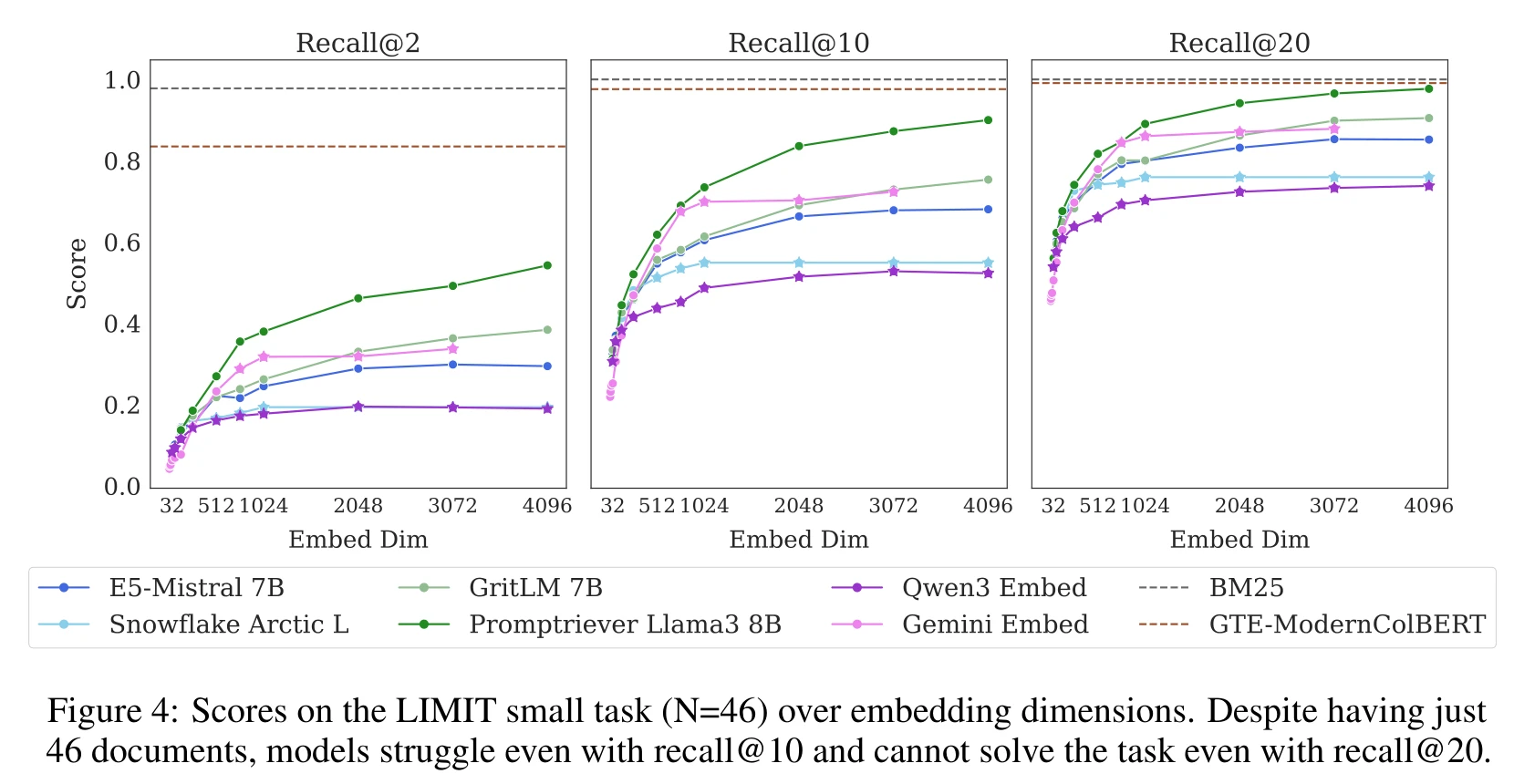
Even picking 2 documents out of 46, Promptriever 4096-dim only hits 54.3% Recall@2, Qwen3 Embed just 19.0%. Models cannot solve the task even with Recall@20 — returning 20 out of 46 documents still misses the correct pair.
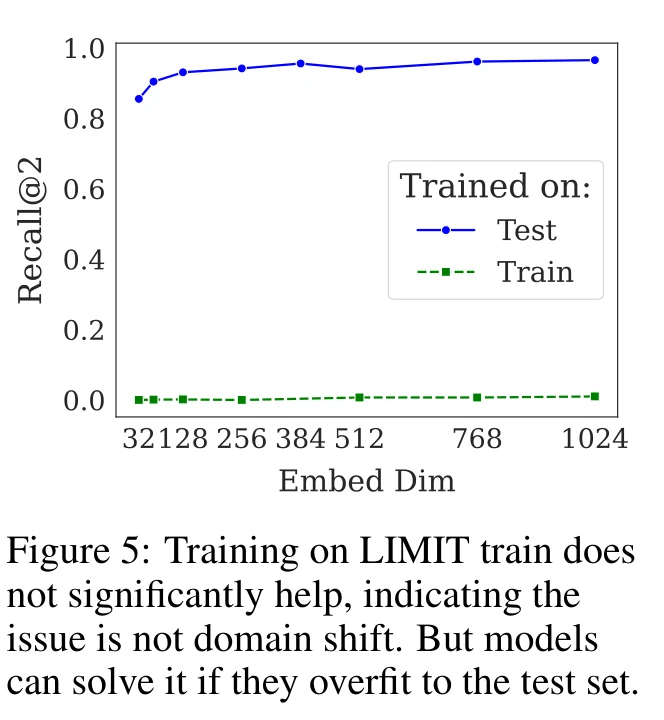
The paper rules out domain shift as the explanation. Fine-tuning on a LIMIT training set (same format, different attributes) barely moves the needle — Recall@10 goes from ~0 to 2.8%. But fine-tuning on the test set pushes performance to near 100%, confirming the issue is representational capacity, not distribution mismatch.
BM25 Wins, But Not Really
BM25 scores 97.8% Recall@2 on LIMIT. Its “dimension” is the vocabulary size, orders of magnitude larger than any dense model, and the task is pure lexical matching.
But this advantage is fragile. The paper creates a synonym variant: replace all attributes in the corpus with synonyms (“glasses” → “spectacles”), keeping queries unchanged.
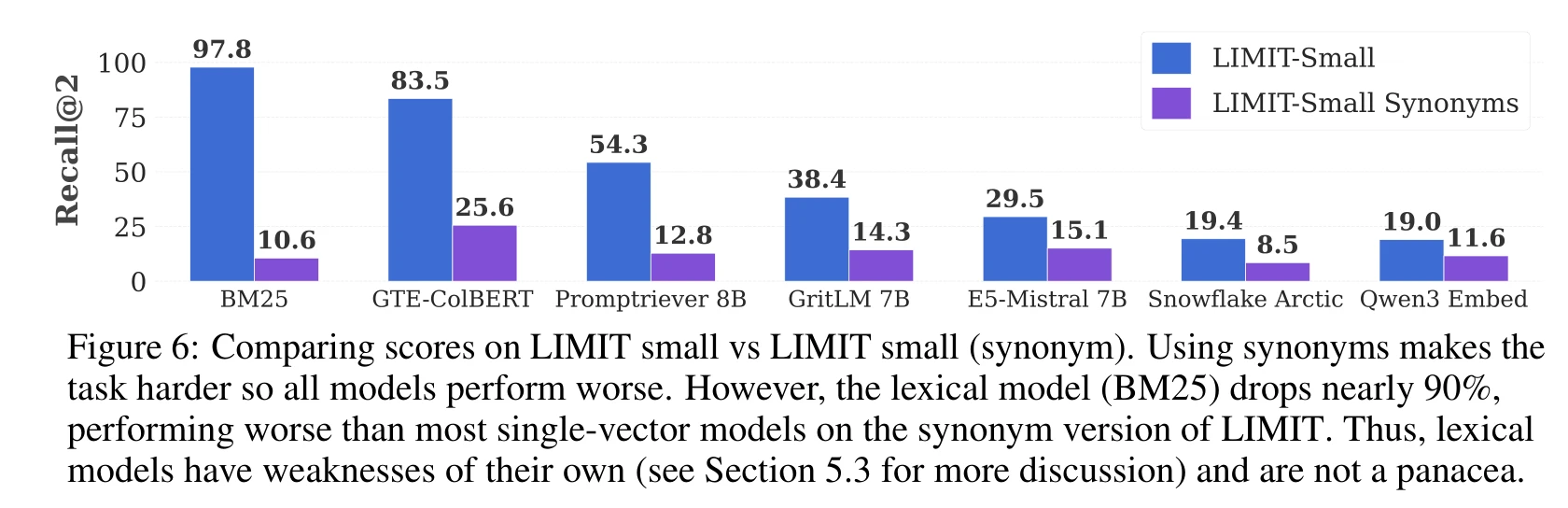
BM25 drops from 97.8% to 10.6%, an 89% collapse. Dense models also decline but far less — Qwen3 Embed drops 38.9%. BM25’s high dimensionality only helps when there’s exact lexical overlap. Move to semantic matching and it falls apart.
Alternative Architectures
Cross-encoders: Gemini 2.5 Pro, given all 46 documents and 1,000 queries in a single pass, scores 100%. Cross-encoders compute a score for each query-document pair independently, so they’re not constrained by embedding dimension. The tradeoff is that they can’t do first-stage retrieval at scale.
Multi-vector models: GTE-ModernColBERT (ColBERT architecture) reaches 83.5% Recall@2 on the full LIMIT, substantially better than single-vector models despite using a smaller backbone. The per-token vectors with MaxSim scoring provide more expressive power, though still well short of solving the task.
What This Means for RAG
The core message: single-vector retrieval has a hard combinatorial ceiling that better training data and larger models cannot overcome.
For RAG practitioners, a few concrete implications. As query complexity grows (instruction-following, logical composition, reasoning), the number of top-k combinations that need to be representable explodes, and single-vector models will increasingly fail. This isn’t a quality problem — it’s a capacity limit.
The complementarity of BM25 and dense retrieval is not a nice-to-have; it’s structural. Their weaknesses are almost perfectly opposed: BM25 has high dimensionality but only does lexical matching; dense models do semantic matching but in a low-dimensional space.
For high-stakes retrieval (legal, medical, compliance), relying on dense retrieval alone may have systematic blind spots. Cross-encoder reranking or multi-vector models become necessary safeguards, not optional enhancements.
The paper is honest about its limits: the theory covers single-vector models only and doesn’t extend to multi-vector architectures. It also doesn’t bound the “allow some errors” setting. Both are open problems.