
If you’re into serverless infrastructure engineering, AWS’s Distinguished Engineer Marc Brooker is one of your wisest teachers. In my years working at modal.com his blog has been a super valuable resource to me. I’ve noticed that he really likes ‘the 5 minute rule’, having brought it up at least five times now. I figured if he thinks it’s important I better get my head around it! So here goes.
Simply stated
Jim Gray’s famous 5 minute rule, from 1987:
If an item is accessed frequently enough, it should be main memory resident. For current technology, “frequently enough” means about every five minutes.
It was the 80s and Gray, an eventual 1998 Turing Award winner, was thinking about how much spinning disk storage and RAM he should buy. He went to the 1986 Tandem Computers catalogue and found he could by a disk for about $15,000 and get 15 random accesses a second. Not a lot! A megabyte of Tandem main memory cost $5,000 and could be used to cache data and avoid loading up his feeble $15,000 disks.
If Gray bought too much RAM he’d have overspent, under-loading his relatively cheaper disk storage devices. If he bought too little his disks overload and performance degrades. This is an optimization problem, but one that felt quite strange to me when first reading it.
It’s now 2025—forty years on1—and cloud computing has completely upended the typical engineer’s relationship with computing economics. What Gray is doing is capacity planning, and in the era of hyperscaler clouds very few of us need to do it.
But the ‘5 minute rule’ still matters.
Even if we no longer buy and hold hardware—picking specific disks and RAM sticks and plugging them into motherboards—we still make decisions about RAM/disk ratios. In 2022, Marc Brooker was still finding use of it in AWS Lambda:
Following the logic of Gray and Putzolu’s classic Five Minute Rule [14], the minimum desirable cache size is the one that makes the cost of cache retention equal to the cost of fetching chunks from S3. However, because our cache is not only aimed at reducing costs but also improving customer-observed latency, we also set a hit rate goal and increase the cache size if we fall below that goal. The total cache size, then, is the larger of the size needed to achieve our hit rate goal, and the size needed to optimize costs. — On-demand Container Loading in AWS Lambda
The 5 minute rule insight is durable. We can plug our storage costs, memory costs, and access costs into Gray’s original working and get insight into today’s cloud-based engineering problems.
So let’s work through the original story and then understand how Brooker reapplied it to AWS Lambda.
Understanding Gray’s problem
From Gray’s original paper we have the parameters of the optimization problem:
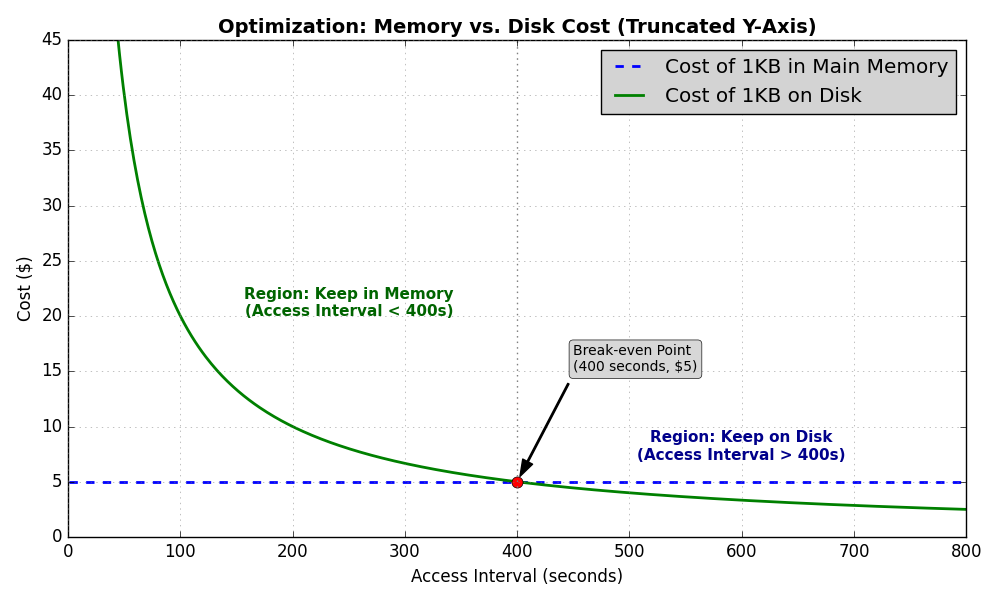
The derivation of the five minute rule goes as follows: A disc, and half a controller comfortably deliver 15 random accesses per second and are priced at about 15K$ So the price per disc access per second is about 1K$/a/s. The extra CPU and channel cost for supporting a disc is 1K$/a/s. So one disc access per second costs about 2K$/a/s. [emphasis mine]
A megabyte of main memory costs about 5K$, so a kilobyte costs 5$. If making a 1Kb data record main-memory resident saves 1a/s, then it saves about 2K$ worth of disc accesses at a cost of 5$, a good deal. If it saves .1a/s then it saves about 200$, still a good deal. Continuing this, the break-even point is one access every 2000/5 - 400 seconds. So, any 1KB record accessed more frequently than every 400 seconds should live in main memory.
Initially finding this formulation unintuitive, I reformulated it to get an alternative that clicked.
In Gray’s day a ‘page’ of data was 1KB (nowadays it’s typically 4KiB). So for every mebibyte of RAM you can cache 1000 pages of memory and avoid trips to disk. How expensive is a trip to disk? Well, Gray’s disks can do 15 random accesses per second and cost $15,000, so that’s $1,000 per access per second (1K$/a/s/). But Gray slaps on an extra $1,000 per access for CPU and channel (a.k.a bus) costs. So $2,000 in hardware spend to buy a rate of one page access per second. Yikes.
A page cache hit is thus worth $2,000. But it only costs $5,000 / 1000 = $5 to get a hit with a RAM stick!
This is a 400x amplification in RAM spend effectiveness: you get $400 dollars of value for every $1 you spend on RAM. With this much amplification in RAM value, you’d break even if a page only saved 1/400th of a disk access per second. Or, in other words, if the page was only accessed once every 400 seconds you’d still break even.
And if you squint, that’s about five minutes.
Moving it into the 21st century…
15 accesses a second is bonkers slow for disk storage in 2025. To get a feel for the ‘5 minute rule’ in today’s cloud computing world let’s move into thinking about RAM and AWS S3, like was done in Brooker’s AWS Lambda paper referenced above:
Following the logic of Gray and Putzolu’s classic Five Minute Rule [14], the minimum desirable cache size is the one that makes the cost of cache retention equal to the cost of fetching chunks from S3.
S3 is here an origin tier store, durable to around ten or eleven 9s. Just like in the paper, let’s make the cache size under consider that of regional caching servers which fetch from S3 on misses. These servers could be ephemeral for cost optimization, but for simplicity we’ll take the resource costs of on-demand (a.k.a dedicated) cloud servers:
- RAM: $1 per GiB/month
- SSD: $0.05 per GiB/month
- Blob (S3): $0.02 per GiB/month plus $0.0004 per thousand requests.
(Note we’ve switched to base-2 gibibytes)
Here we don’t have an accesses per second number like Gray had in his original working. You may think an S3 rate limit could serve as one, but S3 offers “5,500 GET/HEAD requests per second per partitioned Amazon S3 prefix.” With many prefixes our limit could be over 100,000 RPS. They also say that you can pull down “up to 100 Gb/s on a single instance.”
With those limits, the properties of S3 seem to me entirely different to Tandem’s spinning platters. We’ll have to pose our ‘5 minute rule’ problem in terms of our system’s actual, practical limits.
S3’s economic dimensions are:
- data storage cost
- data egress cost
- service HTTP requests cost
Storing 2**30 bytes in S3 for a month costs $0.02. At a 4KiB page size (2**12) we can store a page in S3 for $0.02 / 2**18, absurdly little money.
We’ll assume the S3 client is an EC2 instance within the same AWS region as the bucket, so egress costs are zero.
Each request to retrieve a page costs $4/(10**7) dollars, or $0.0000004, also tiny.
These numbers are so annoyingly small it’ll be easier to work comparatively. Blob storage is 50x cheaper than RAM if you don’t access it. But if you access it you start accumulating costs. The break even point is when you perform (1-0.02) / cost_per_request = 2,450,000 requests in a month across 1GiB of pages. There’s 262,144 pages in a 1GiB so each page can get 9.35 accesses a month before S3 becomes more expensive. Increase requests per page per month beyond 9.35 and you start to spend more on S3 than on RAM.
9.35 requests per month per page is super low! So any page accessed more frequently than once every few days—not once every five minutes!—should be kept in RAM to avoid spending too much on S3 requests.
This analysis ignores disk caching, for brevity. It also ignores the other costs which are part of EC2 instance pricing (CPU, network bandwidth).
This makes RAM-resident data look extremely economical2, and that’s before even considering the gigantic differences in access latency. Accessing main memory is around 100 nanoseconds. Accessing S3 is around 100 milliseconds, or 1 million times slower. Brooker gets at this cost/performance trade off in the paper:
However, because our cache is not only aimed at reducing costs but also improving customer-observed latency, we also set a hit rate goal and increase the cache size if we fall below that goal.
At a certain point, it doesn’t matter how much money you save by trading off performance, your customers will leave and you’ll make $0.00 revenue.
To summarize, by looking at the two relevant cost dimensions of the S3 service we have found that if a page is accessed at least once every few days, it should be main memory resident in a cache server and not in S3.
Under this simplified analysis Gray’s 5-minute rule has become a 72-hour rule. This big duration change is not so surprising. The domain has completely changed. Similar analysis performed on web browser caching found that an item should be cached in the browser’s disk cache if the item has any non-zero chance of being read again3.
| Era | Storage | Memory | Break-even | Rule of Thumb |
|---|---|---|---|---|
| 1987 | Disk | RAM | 400 sec | 5 minutes |
| 2025 | S3 | RAM | 277,338 sec | 3 days |
Despite the rule of thumb not working at all, we have, as Brooker wrote, a durable insight that we “can calculate the cost of something (storing a page of data in memory) and the cost of replacing that thing (reading the data from storage), and quantitatively estimate how long we should keep the thing.”
Pretty neat!