Everyone knows what AWS S3 is, but few comprehend the massive scale it operates at, nor what it took to get there.
In essence - it’s a scalable multi-tenant storage service with APIs to store and retrieve objects, offering extremely high availability1 and durability2 at a relatively low cost3.
400+ trillion4 objects
150 million requests a second (150,000,000/s)
> 1 PB/s of peak traffic
tens of millions of disks

Hard drives.
How S3 achieves this scale is an engineering marvel. To understand and appreciate the system, we first must appreciate its core building block - the hard drive.
Hard Disk Drives (HDDs) are an old, somewhat out-of-favor technology largely superseded by SSDs. They are physically fragile, constrained for IOPS and high in latency.
But they nailed something flash still hasn’t: dirt cheap commodity economics:
Over their lifetime, HDDs have seen exponential improvement:
price: 6,000,000,000x cheaper per byte (inflation-adjusted)
capacity: increased 7,200,000x
size: decreased 5,000x
weight: decreased 1,235x
But one issue has consistently persisted - they’re constrained for IOPS. They have been stuck at 120 IOPS for the last 30 years.
Latency also hasn’t kept up in the same pace as the rest.
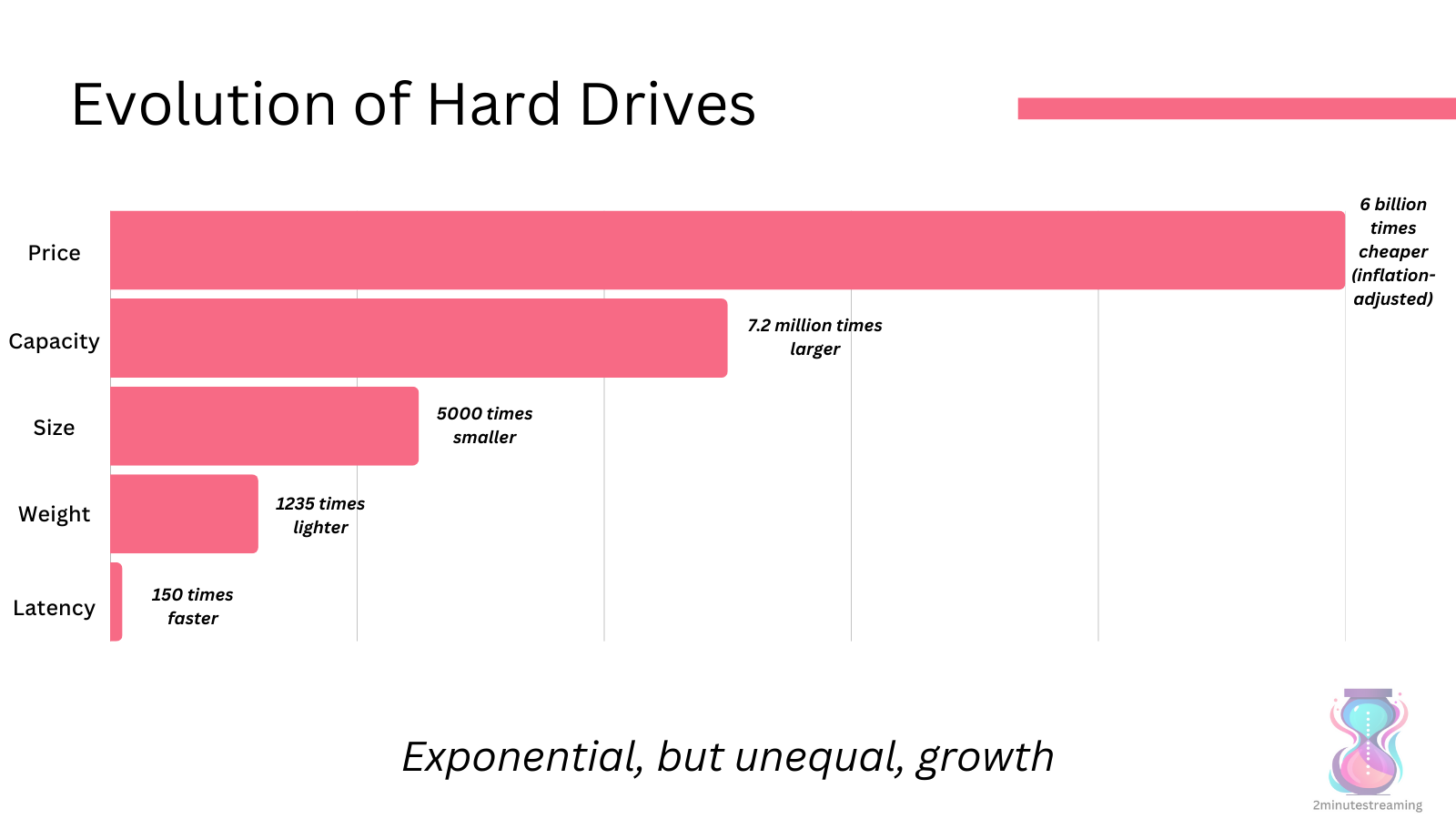
This means that per byte, HDDs are becoming slower.
HDDs are slow because of physics.
They require real-world mechanical movement to read data. (unlike SSDs, which use electricity travelling at ~50% the speed of light). Here is a good visualization:
The platter spins around the spindle at about 7200 rounds per minute (RPM)5.
The mechanical arm (actuator) with its read/write head physically moves across the platter and waits for it to rotate until it gets to the precise LBA address where the data resides.
Accessing data from the disk therefore involves two mechanical operations and one electrical.
That physical movements are:
seek - the act of the actuator moving left or right to the correct track on the platter
rotation - waiting for the spindle to spin the disk until it matches the precise address on the platter’s track
full rotational latency: ~8.3ms8
half rotational latency (avg): ~4ms
And then the electrical one:
transfer rate - the act of the head shoving bits off the platter across the bus into memory (the drive’s internal cache)
reading 0.5MB: ~2.5ms on average9
Hard Drives are optimized for sequential access patterns.
Reading/writing bytes that are laid out consecutively on the disk is fast. The natural rotation of the platter cycles through the block of bytes and no excessive seeks need to be performed (the actuator stays still).
The easiest and most popular data structure with sequential access patterns is the Log. Popular distributed systems like Apache Kafka are built on top of it and through sequential access patterns squeeze out great performance off cheap hardware.
It is no surprise that S3’s storage backend - ShardStore - is based on a log-structured merge tree (LSM) itself.
In essence, writes for S3 is easy. Because they write sequentially to the disk, they take advantage of the HDD’s performance. (similar to Kafka, I bet they batch pending PUTs so as to squeeze out more sequential throughput on disk via appends to the log)10
Reads, however, are trickier. AWS can’t control what files the user requests - so they have to jump around the drive when serving them.
In the average case, a read on a random part of the drive would involve half of the full physical movement.
The average read latency is the sum of both average physical movements plus the transfer rate. Overall, you’re looking at ~16ms on average to read 0.5 MB of random I/O from a drive. That’s very slow.
Since a second has 1000 milliseconds, you’d only achieve ~32MB/s of random I/O from a single drive.
Because physical movements are a bottleneck - disks have been stuck at this same random I/O latency for the better part of 30 years.
They are simply not efficient under random access patterns. That’s when you’d opt for SSDs. But if you have to store massive amounts of data - SSDs become unaffordable.11
This becomes a pickle when you are S3 - a random access system12 that also stores massive amounts of data.
Yet, S3 found a way to do it - it delivers tolerable latency13 and outstanding14 throughput while working around the physical limitations.
S3 solves this problem through massive parallelism.
They spread the data out in many (many!15) hard drives so they can achieve massive read throughput by utilizing each drive in parallel.
Storing a 1 TB file in a single HDD means limits your reading rate by that single drive’s max throughput (~300 MB/s16).
Splitting that same 1 TB file across 20,000 different HDDs means you can read it in parallel at the sum of all HDDs’ throughput (TB/s).
They do this via Erasure Coding.
Redundancy schemes are common practice in storage systems.
They are most often associated with data durability - protecting against data loss when hardware fails.
S3 uses Erasure Coding (EC). It breaks data into K shards with M redundant “parity” shards. EC allows you to reconstruct the data from any K shards out of the total K+M shards.
The S3 team shares they use a 5-of-9 scheme. They shard each object into 9 pieces - 5 Regular Shards (K) and 4 Parity Shards (M)
This approach tolerates up to 4 losses. To access the object, they need 5/9 shards.
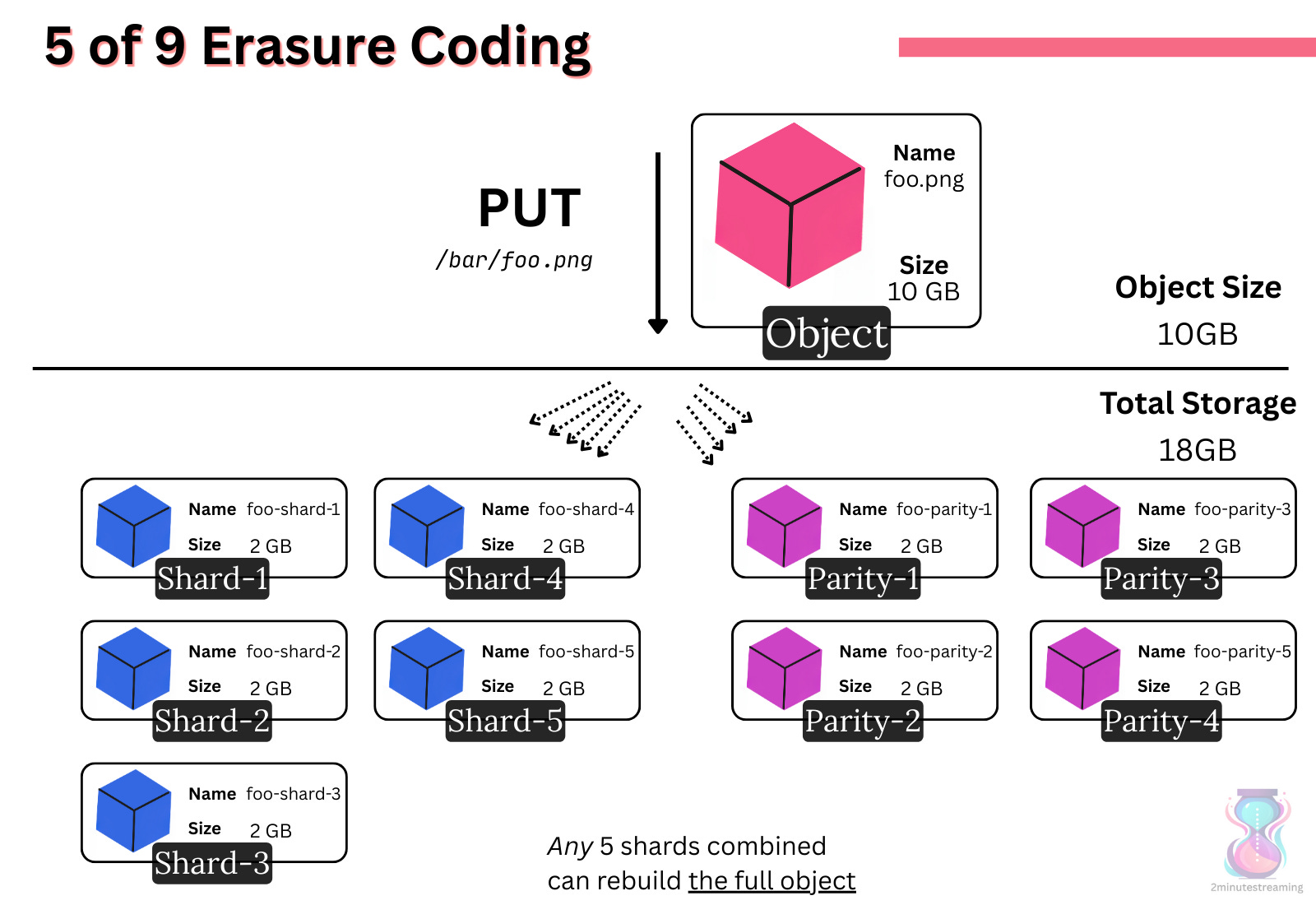
This scheme helps S3 find a middle balance - it doesn’t take much extra disk capacity yet still provides flexible I/O.
EC makes them store 1.8x the original data.
A naive alternative like 3-way replication would result in 3x the data. That extra 1.2x starts to matter when we’re talking hundreds of exabytes.
EC gives them 5-of-9 possible read sources - an ample hedge against node bottlenecks
3-way replication would only give them 3 sources, meaning its resistant to maximum 2 straggler nodes. If all 3 nodes are hot, performance would suffer. 5-of-9 EC is resistant to 4 straggler nodes (2x more).
EC’s 5-of-9 sources also offer much more burst write/read I/O due to parallelism and the actual sharding of the data17
An under-appreciated aspect of EC is precisely its ability to distribute load. Such schemes spread the hot spots of a system out and give it the flexibility to steer read traffic in a balanced way. And since shards are small, firing off hedge requests18 to dodge stragglers is far cheaper than with full replicas.
S3 leverages parallelism in three main ways:
From the user’s perspective - upload/download the file in chunks.
From the client’s perspective - send requests to multiple different front-end servers.
From the server’s perspective - store an object in multiple storage servers.
Any part of the end-to-end path can become a bottleneck, so it’s important to optimize everything.
Instead of requesting all the files through one connection to one S3 endpoint, users are encouraged to open as many connections as necessary. This happens behind the scenes in the library code through an internal HTTP connection pool.
This approach utilizes many different endpoints of the distributed system, ensuring no single point in the infrastructure becomes too hot (e.g. front-end proxies, caches, etc)
Instead of storing the data in a single hard-drive, the system breaks it into shards via EC and spreads it out across multiple storage back ends.
Instead of sending one request through a single thread and HTTP connection, the client chunks it into 10 parts and uploads each in parallel.19
PUT requests support multipart upload, which AWS recommends in order to maximize throughput by leveraging multiple threads.
GET requests similarly support an HTTP header denoting you read only a particular range of the object (called byte-ranged GET). AWS again recommends this for achieving higher aggregate throughput instead of the single object read request.
Uploading 1 GB/s to a single server may be difficult, but uploading 100 chunks each at 10 MB/s chunks to 100 different servers is very practical.
This simple idea goes a long way.
S3 now finds itself with a difficult problem. They have tens of millions of drives, hundreds of millions of parallel requests per second and hundreds of millions of EC shards to persist per second.
How do they spread this load around effectively so as to avoid certain nodes/disks overheating?
As we said earlier - a single disk can do around ~32 MB/s of random IOs. It seems trivial to hit that bottleneck. Not to mention any additional system maintenance work like rebalancing data around for more efficient spreading would also take valuable IOs off the disk.
Forming hot spots in a distributed system is dangerous, because it can easily cause a domino-like spiral into system-wide degradation20.
Needless to say, S3 is very careful in trying to spread data around. Their solution is again deceptively simple:
randomize where you place data on ingestion
continuously rebalance it
scale & chill
Where you place data initially is key to performance. Moving it later is more expensive.
Unfortunately, at write time you have no good way of knowing whether the data you’re about to persist is going to be accessed frequently or not.
Knowing the perfect the least-loaded HDD to place new data in is also impossible at this scale. You can’t keep a synchronous globally-consistent view when you are serving hundreds of millions of requests per second across tens of millions of drives. This approach would also risk load correlation - placing similar workloads together and having them burst together at once.
A key realization is that picking at random works better in this scenario. 💡
It’s how AWS intentionally engineers decorrelation into their system:
A given PUT picks a random set of drives
The next PUT, even if it’s targetting the same key/bucket, picks a different set of near-random drives.
The way they do it is through the so-called Power of Two Random Choices:
Power of Two Random Choices: a well-studied phenomenon in load balancing that says choosing between the least-loaded of two completely random nodes yields much better results than choosing just one node at random.
Another key realization is that newer data chunks are hotter than older ones. 💡
Fresh data is accessed more frequently. As it grows older, it gets accessed less.
All hard drives therefore eventually cool off in usage as they get filled with data and said data ages. The result is full storage capacity with ample I/O capacity.
AWS has to proactively rebalance the cold data out (so as to free up space) and rebalance cold data in (so as to make use of the free I/O).
Data rebalances are also needed when new racks of disks are added to S3. Each rack contains 20 PB of capacity21, and every disk in there is completely empty. The system needs to proactively spread the load around the new capacity.
Suffice to say - S3 constantly rebalances data around.
The last realization is perhaps the least intuitive: the larger the system becomes, the more predictable it is. 💡
AWS experienced so-called workload decorrelation as S3 grew. That is the phenomenon of seeing a smoothening of load once it’s aggregated on a large enough scale. While their peak demand is growing in size, their peak-to-mean delta is collapsing.
This is because storage workloads are inherently very bursty - they demand a lot at once, and then may remain idle for a long time (months).
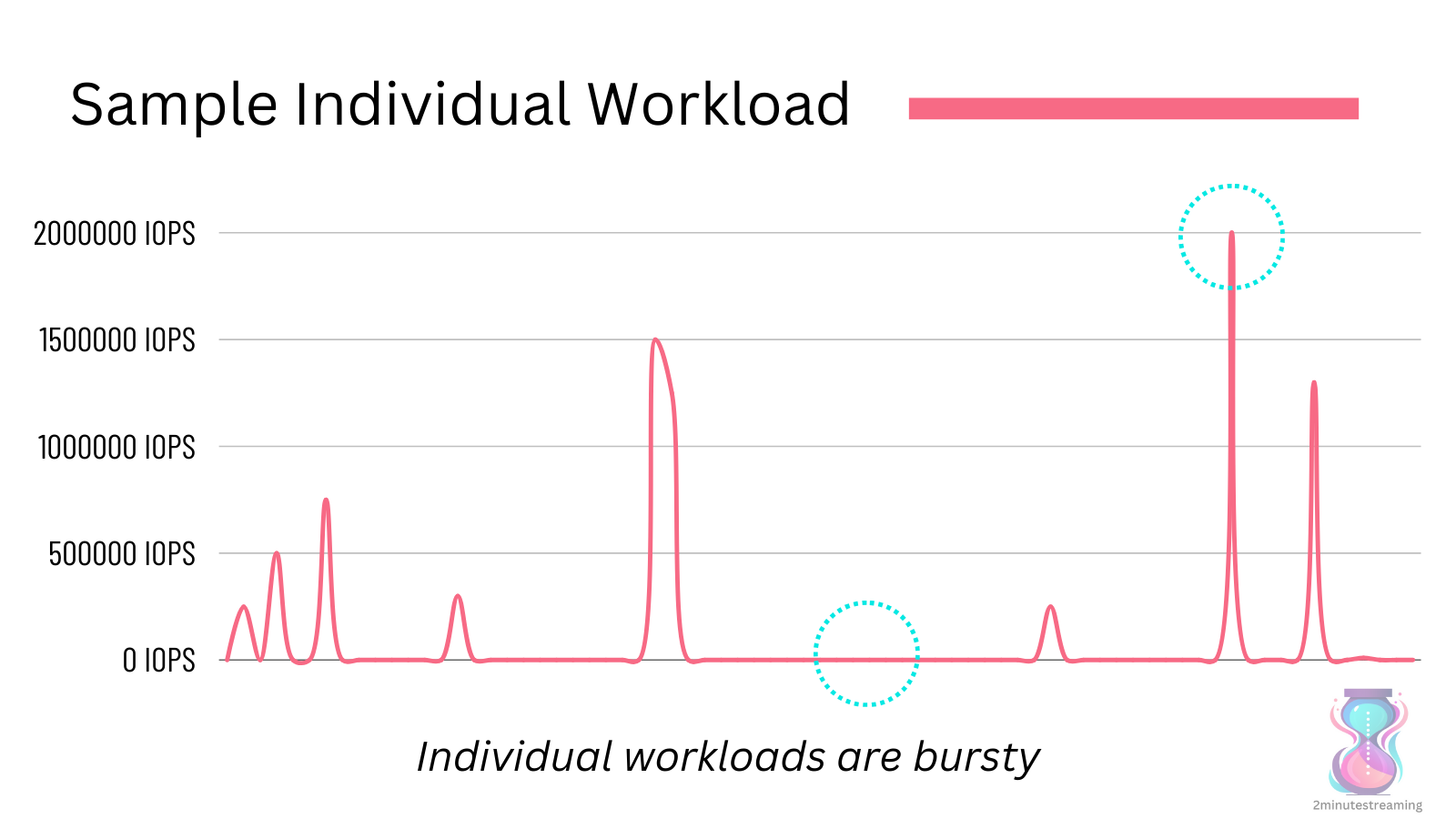
Because independent workloads do not burst together, the more workloads you cram together - the more those idle spots get filled up and the more predictable the system becomes in aggregate. 💡
copyright: AWS; from this re:Invent presentation.
AWS S3 is a massively multi-tenant storage service. It’s a gigantic distributed system consisting of many individually slow nodes that on aggregate allow you to access data faster than any single node can provide. S3 achieves this through:
massive parallelization across the end-to-end path (user, client, server)
neat load-balancing tricks like the power of two random
spreading out data via erasure coding
lowering tail latency via hedge requests
the economies of multi-tenancy at world scale
It started as a service optimized for backups, video and image storage for e-commerce websites - but eventually grew support being the main storage system used for analytics and machine learning on massive data lakes.
Nowadays, the growing trend is for entire data infrastructure projects to be based on top of S3. This gives them the benefits of stateless nodes (easy scaling, less management) while outsourcing difficult durability, replication and load-balancing problems to S3. And get this - it also reduces cloud costs.22
Learned something? Share with a colleague on Slack
Subscribe for more interesting dives in big data distributed systems (or the occassional small data gem).
S3 has a lot of other goodies up its bag, including:
shuffle sharding at the DNS level
client library hedging requests by cancelling slow requests that pass the p95 threshold and sending new ones to a different host
software updates done erasure-coding-style, including rolling out their brand-new ShardStore storage system without any impact to their fleet
conway’s law and how it shapes S3’s architecture (consisting of 300+ microservices)
their durability culture, including continuous detection, durable chain of custody, a design process that includes durability threat modelling and formal verification
These are generally shared in their annual S3 Deep Dive at re:Invent:
2022 (video)
2023 (video)
2024 (video)
Building and operating a pretty big storage system called S3 (article)
Thank you to the S3 team for sharing what they’ve built, and thank you for reading!
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。