I’ve solved over 2,000 coding problems across LeetCode and other platforms, and if there’s one thing I’ve learned, it’s this:
Getting good at DSA is less about how many problems you solve and more about how many patterns you truly understand.
Patterns help you solve a wide range of problems in less time because they train you to recognize the right approach, even for questions you have never seen before.
In this article, I’ll walk you through the 20 most important patterns that made learning DSA and preparing for coding interviews far less painful for me.
Even better, these are the same patterns that showed up again and again in my interviews, including at companies like Amazon and Google.
For each pattern, I’ll share:
When to use it
A reusable template
A sample problem walkthrough
Practice links to related LeetCode problems
This article is the essence of everything I have learned about DSA and LeetCode, distilled into one guide. I’ve also added links for each pattern so you can dive deeper when you’re ready.
If you want to explore more patterns and resources, check out: algomaster.io
Let’s get started.
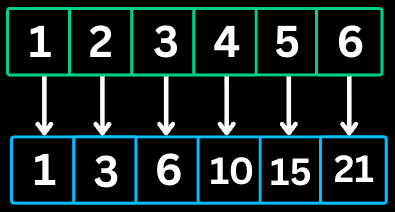
The Prefix Sum pattern involves preprocessing an array to create a new array where each element at index i represents the sum of all elements from the start up to i. This allows for O(1) sum queries on any subarray.
Multiple sum queries on subarrays
Finding subarrays with a target sum
Calculating cumulative totals
// Build prefix sum array
int[] prefix = new int[n + 1];
for (int i = 0; i < n; i++) {
prefix[i + 1] = prefix[i] + nums[i];
}
// Query sum of range [left, right]
int rangeSum = prefix[right + 1] - prefix[left];Range Sum Query: Given an array nums, answer multiple queries about the sum of elements within a specific range [i, j].
Input: nums = [1, 2, 3, 4, 5, 6], i = 1, j = 3
Output: 9
nums = [1, 2, 3, 4, 5, 6]
Step 1: Build prefix sum array
prefix[0] = 0
prefix[1] = 0 + 1 = 1
prefix[2] = 1 + 2 = 3
prefix[3] = 3 + 3 = 6
prefix[4] = 6 + 4 = 10
prefix[5] = 10 + 5 = 15
prefix[6] = 15 + 6 = 21
prefix = [0, 1, 3, 6, 10, 15, 21]
Step 2: Query sum for range [1, 3]
sum = prefix[3 + 1] - prefix[1]
sum = prefix[4] - prefix[1]
sum = 10 - 1 = 9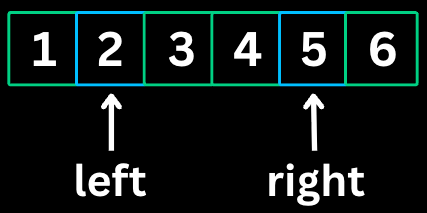
The Two Pointers pattern uses two pointers to traverse an array or list, typically from opposite ends or both moving in the same direction. It reduces time complexity from O(n^2) to O(n) for many problems.
Finding pairs in sorted arrays
Comparing elements from both ends
Partitioning arrays
Palindrome checks
// Opposite direction (converging)
int left = 0, right = n - 1;
while (left < right) {
if (condition_met) {
// found answer
} else if (need_larger_sum) {
left++;
} else {
right--;
}
}
// Same direction
int slow = 0;
for (int fast = 0; fast < n; fast++) {
if (condition) {
// process and move slow
slow++;
}
}Two Sum II: Find two numbers in a sorted array that add up to a target value. Return their indices.
Input: nums = [1, 2, 3, 4, 6], target = 6
Output: [1, 3] (indices of 2 and 4)
nums = [1, 2, 3, 4, 6], target = 6
Step 1: left = 0, right = 4
sum = nums[0] + nums[4] = 1 + 6 = 7 > 6
Move right pointer left: right = 3
Step 2: left = 0, right = 3
sum = nums[0] + nums[3] = 1 + 4 = 5 < 6
Move left pointer right: left = 1
Step 3: left = 1, right = 3
sum = nums[1] + nums[3] = 2 + 4 = 6 == target
Found! Return [1, 3]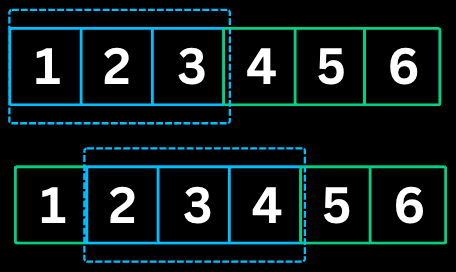
The Sliding Window pattern maintains a window of elements and slides it across the array to find subarrays or substrings that satisfy certain conditions. It avoids recalculating overlapping parts of consecutive windows.
Contiguous subarray/substring problems
Finding maximum/minimum in window of size k
Longest/shortest substring with certain properties
Problems involving consecutive elements
// Fixed-size window
int windowSum = 0;
for (int i = 0; i < n; i++) {
windowSum += nums[i];
if (i >= k - 1) {
// process window
result = Math.max(result, windowSum);
windowSum -= nums[i - k + 1];
}
}
// Variable-size window
int left = 0;
for (int right = 0; right < n; right++) {
// expand window by including nums[right]
while (window_condition_violated) {
// shrink window from left
left++;
}
// update result
}Maximum Sum Subarray of Size K: Find the maximum sum of any contiguous subarray of size k.
Input: nums = [2, 1, 5, 1, 3, 2], k = 3
Output: 9
nums = [2, 1, 5, 1, 3, 2], k = 3
Step 1: Build initial window [2, 1, 5]
windowSum = 2 + 1 + 5 = 8
maxSum = 8
Step 2: Slide window to [1, 5, 1]
windowSum = 8 - 2 + 1 = 7
maxSum = max(8, 7) = 8
Step 3: Slide window to [5, 1, 3]
windowSum = 7 - 1 + 3 = 9
maxSum = max(8, 9) = 9
Step 4: Slide window to [1, 3, 2]
windowSum = 9 - 5 + 2 = 6
maxSum = max(9, 6) = 9
Result: 9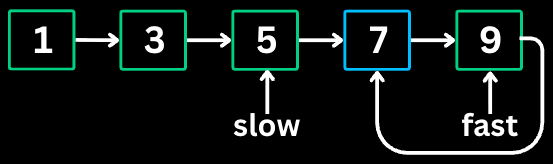
The Fast & Slow Pointers pattern (also called Tortoise and Hare) uses two pointers moving at different speeds. When there is a cycle, the fast pointer will eventually meet the slow pointer.
Detecting cycles in linked lists or arrays
Finding the middle of a linked list
Finding the start of a cycle
// Find middle
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow; // middle node
// Cycle detection
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
// cycle detected
return true;
}
}
return false; // no cycleLinked List Cycle: Detect if a linked list has a cycle.
Input: head = [3, 2, 0, -4], tail connects to node index 1
Output: true
List: 3 -> 2 -> 0 -> -4 -> (back to 2)
Step 1: slow = 3, fast = 3
Step 2: slow = 2, fast = 0
Step 3: slow = 0, fast = 2 (wrapped around)
Step 4: slow = -4, fast = -4
slow == fast, cycle detected!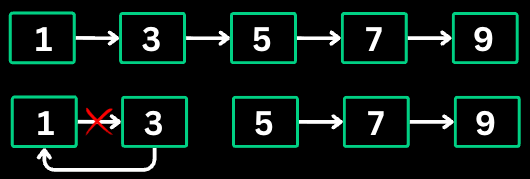
This pattern reverses parts of a linked list without using extra space. It manipulates pointers to reverse the direction of links.
Reversing a linked list or portion of it
Reversing nodes in groups
Checking for palindromes in linked lists
// Reverse entire list
ListNode prev = null, curr = head;
while (curr != null) {
ListNode next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev; // new headReverse Linked List II: Reverse the nodes of a linked list from position m to n.
Input: head = [1, 2, 3, 4, 5], m = 2, n = 4
Output: [1, 4, 3, 2, 5]
Original: 1 -> 2 -> 3 -> 4 -> 5
Reverse positions 2 to 4
Step 1: Position prev before node 2
prev = 1, curr = 2
Step 2: Move 3 after 1
1 -> 3 -> 2 -> 4 -> 5
Step 3: Move 4 after 1
1 -> 4 -> 3 -> 2 -> 5
Result: [1, 4, 3, 2, 5]The Frequency Counting pattern uses hash maps or arrays to count occurrences of elements. It transforms O(n^2) lookup problems into O(n) by trading space for time.
Finding duplicates or unique elements
Checking if two collections have same elements
Finding elements that appear k times
Anagram problems
// Using HashMap
Map<Integer, Integer> freq = new HashMap<>();
for (int num : nums) {
freq.put(num, freq.getOrDefault(num, 0) + 1);
}
// Using array (when range is known)
int[] freq = new int[26]; // for lowercase letters
for (char c : str.toCharArray()) {
freq[c - 'a']++;
}
// Finding element with specific frequency
for (Map.Entry<Integer, Integer> entry : freq.entrySet()) {
if (entry.getValue() == target) {
return entry.getKey();
}
}Valid Anagram: Given two strings s and t, return true if t is an anagram of s.
Input: s = "anagram", t = "nagaram"
Output: true
s = "anagram", t = "nagaram"
Step 1: Count frequencies in s
freq = {a: 3, n: 1, g: 1, r: 1, m: 1}
Step 2: Decrement frequencies using t
't' -> n: freq[n] = 1 - 1 = 0
't' -> a: freq[a] = 3 - 1 = 2
't' -> g: freq[g] = 1 - 1 = 0
't' -> a: freq[a] = 2 - 1 = 1
't' -> r: freq[r] = 1 - 1 = 0
't' -> a: freq[a] = 1 - 1 = 0
't' -> m: freq[m] = 1 - 1 = 0
Step 3: Check all frequencies are 0
freq = {a: 0, n: 0, g: 0, r: 0, m: 0}
All zero -> Return true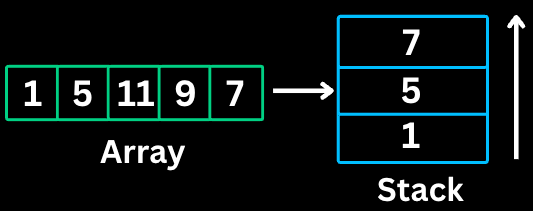
A Monotonic Stack maintains elements in either increasing or decreasing order. As you iterate, you pop elements that violate the order, which reveals relationships between elements.
Finding the next greater/smaller element
Finding previous greater/smaller element
Problems involving spans or ranges
Histogram problems
/// Next Greater Element (decreasing stack)
int[] result = new int[n];
Arrays.fill(result, -1);
Stack<Integer> stack = new Stack<>(); // stores indices
for (int i = 0; i < n; i++) {
while (!stack.isEmpty() && nums[i] > nums[stack.peek()]) {
int idx = stack.pop();
result[idx] = nums[i];
}
stack.push(i);
}Next Greater Element: For each element in an array, find the next greater element. Output -1 if none exists.
Input: nums = [2, 1, 2, 4, 3]
Output: [4, 2, 4, -1, -1]
nums = [2, 1, 2, 4, 3]
result = [-1, -1, -1, -1, -1]
stack = []
Step 1: i = 0, nums[0] = 2
stack is empty, push 0
stack = [0]
Step 2: i = 1, nums[1] = 1
1 < nums[0]=2, push 1
stack = [0, 1]
Step 3: i = 2, nums[2] = 2
2 > nums[1]=1, pop 1, result[1] = 2
2 <= nums[0]=2, push 2
stack = [0, 2], result = [-1, 2, -1, -1, -1]
Step 4: i = 3, nums[3] = 4
4 > nums[2]=2, pop 2, result[2] = 4
4 > nums[0]=2, pop 0, result[0] = 4
push 3
stack = [3], result = [4, 2, 4, -1, -1]
Step 5: i = 4, nums[4] = 3
3 < nums[3]=4, push 4
stack = [3, 4]
Result: [4, 2, 4, -1, -1]Bit manipulation uses binary operations (AND, OR, XOR, NOT, shifts) to solve problems efficiently. XOR is particularly useful since a ^ a = 0 and a ^ 0 = a.
Finding unique numbers (XOR)
Checking power of 2
Counting bits
Generating subsets using bit masks
Space optimization
// Basic operations
int and = a & b; // both bits 1
int or = a | b; // either bit 1
int xor = a ^ b; // bits different
int not = ~a; // flip bits
int leftShift = a << n; // multiply by 2^n
int rightShift = a >> n;// divide by 2^n
// Check if bit i is set
boolean isSet = (n & (1 << i)) != 0;
// Set bit i
n = n | (1 << i);
// Clear bit i
n = n & ~(1 << i);
// Toggle bit i
n = n ^ (1 << i);
// Check if power of 2
boolean isPowerOf2 = (n > 0) && ((n & (n - 1)) == 0);
// Count set bits
int count = 0;
while (n > 0) {
count += n & 1;
n >>= 1;
}
// Or: Integer.bitCount(n);
// Find single number (XOR all elements)
int single = 0;
for (int num : nums) {
single ^= num;
}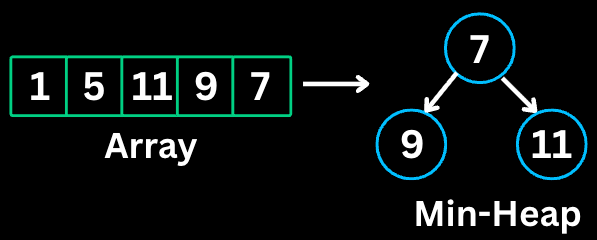
This pattern finds the k largest or smallest elements using heaps (priority queues). A min-heap of size k keeps track of k largest elements, and a max-heap keeps k smallest.
Finding k largest/smallest elements
Finding kth largest/smallest element
Finding k most/least frequent elements
Merging k sorted lists
// K largest elements using min-heap
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
for (int num : nums) {
minHeap.offer(num);
if (minHeap.size() > k) {
minHeap.poll(); // remove smallest
}
}
// minHeap now contains k largest elements
// minHeap.peek() is the kth largestKth Largest Element: Find the kth largest element in an unsorted array.
Input: nums = [3, 2, 1, 5, 6, 4], k = 2
Output: 5
nums = [3, 2, 1, 5, 6, 4], k = 2
Using min-heap of size k
Step 1: num = 3
heap = [3]
Step 2: num = 2
heap = [2, 3]
Step 3: num = 1
heap = [1, 3, 2], size > k
poll smallest: heap = [2, 3]
Step 4: num = 5
heap = [2, 3, 5], size > k
poll smallest: heap = [3, 5]
Step 5: num = 6
heap = [3, 5, 6], size > k
poll smallest: heap = [5, 6]
Step 6: num = 4
heap = [4, 6, 5], size > k
poll smallest: heap = [5, 6]
heap.peek() = 5 (kth largest)This pattern handles problems involving intervals that may overlap. The key insight is that after sorting by start time, two intervals [a, b] and [c, d] overlap if b >= c.
Merging overlapping intervals
Finding interval intersections
Scheduling problems (meeting rooms)
Inserting into sorted intervals
// Sort by start time
Arrays.sort(intervals, (a, b) -> a[0] - b[0]);
// Merge overlapping intervals
List<int[]> merged = new ArrayList<>();
for (int[] interval : intervals) {
if (merged.isEmpty() || merged.get(merged.size() - 1)[1] < interval[0]) {
// no overlap, add new interval
merged.add(interval);
} else {
// overlap, merge by extending end time
merged.get(merged.size() - 1)[1] =
Math.max(merged.get(merged.size() - 1)[1], interval[1]);
}
}Merge Intervals: Given a collection of intervals, merge all overlapping intervals.
Input: intervals = [[1,3], [2,6], [8,10], [15,18]]
Output: [[1,6], [8,10], [15,18]]
intervals = [[1,3], [2,6], [8,10], [15,18]]
(Already sorted by start time)
Step 1: interval = [1,3]
merged is empty, add [1,3]
merged = [[1,3]]
Step 2: interval = [2,6]
last = [1,3], start = 2 <= end = 3
Overlap! Merge: end = max(3, 6) = 6
merged = [[1,6]]
Step 3: interval = [8,10]
last = [1,6], start = 8 > end = 6
No overlap, add [8,10]
merged = [[1,6], [8,10]]
Step 4: interval = [15,18]
last = [8,10], start = 15 > end = 10
No overlap, add [15,18]
merged = [[1,6], [8,10], [15,18]]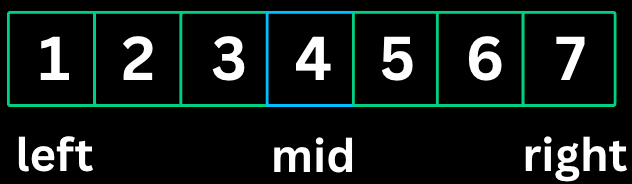
This pattern adapts binary search to handle rotated arrays, finding boundaries, or searching for conditions rather than exact values.
Searching in rotated sorted arrays
Finding first/last occurrence of element
Finding minimum/maximum satisfying a condition
Peak finding problems
// Standard binary search
int left = 0, right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) return mid;
else if (nums[mid] < target) left = mid + 1;
else right = mid - 1;
}
// Find first occurrence
while (left < right) {
int mid = left + (right - left) / 2;
if (condition(mid)) right = mid;
else left = mid + 1;
}Search in Rotated Sorted Array: Search for a target in a rotated sorted array.
Input: nums = [4, 5, 6, 7, 0, 1, 2], target = 0
Output: 4
nums = [4, 5, 6, 7, 0, 1, 2], target = 0
Step 1: left = 0, right = 6, mid = 3
nums[mid] = 7 != 0
nums[left] = 4 <= nums[mid] = 7 (left half sorted)
target = 0 not in [4, 7), search right
left = 4
Step 2: left = 4, right = 6, mid = 5
nums[mid] = 1 != 0
nums[left] = 0 <= nums[mid] = 1 (left half sorted)
target = 0 in [0, 1), search left
right = 4
Step 3: left = 4, right = 4, mid = 4
nums[mid] = 0 == target
Found at index 4!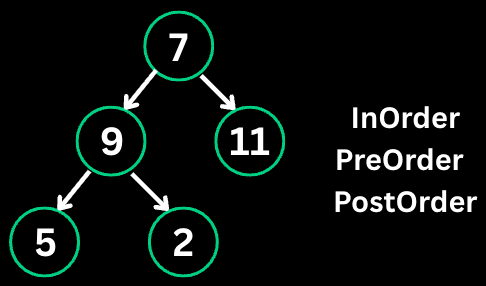
Binary Tree Traversal visits all nodes in a specific order. The three main orders are preorder (root-left-right), inorder (left-root-right), and postorder (left-right-root).
Processing tree nodes in specific order
Building trees from traversals
BST operations (inorder gives sorted order)
Tree serialization/deserialization
// Preorder (Root -> Left -> Right)
void preorder(TreeNode node) {
if (node == null) return;
process(node); // visit root
preorder(node.left); // left subtree
preorder(node.right); // right subtree
}
// Inorder (Left -> Root -> Right)
void inorder(TreeNode node) {
if (node == null) return;
inorder(node.left); // left subtree
process(node); // visit root
inorder(node.right); // right subtree
}
// Postorder (Left -> Right -> Root)
void postorder(TreeNode node) {
if (node == null) return;
postorder(node.left); // left subtree
postorder(node.right); // right subtree
process(node); // visit root
}Inorder Traversal: Return the inorder traversal of a binary tree.
Input: Tree with root = [1, null, 2, 3]
Output: [1, 3, 2]
Tree:
1
\
2
/
3
Inorder: Left -> Root -> Right
Step 1: Start at 1
No left child, visit 1
result = [1]
Step 2: Go to right child 2
Has left child 3, go left
Step 3: At node 3
No left child, visit 3
result = [1, 3]
No right child, backtrack
Step 4: Back at node 2
Left done, visit 2
result = [1, 3, 2]
No right child
Done: [1, 3, 2]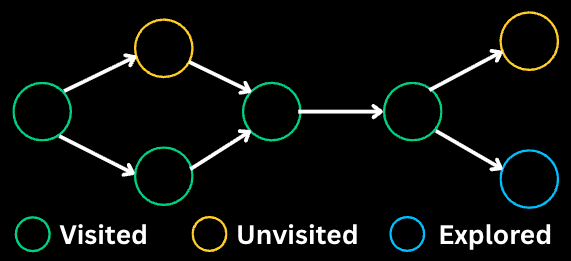
DFS explores as deep as possible along each branch before backtracking. It uses a stack (or recursion) to remember which nodes to visit next.
Exploring all paths in a tree/graph
Finding connected components
Detecting cycles
Topological sorting
Path finding when all paths matter
// DFS on a graph - visited tracking required
void dfs(int node, boolean[] visited, List<List<Integer>> graph) {
visited[node] = true;
// Process current node
process(node);
// Explore unvisited neighbors
for (int neighbor : graph.get(node)) {
if (!visited[neighbor]) {
dfs(neighbor, visited, graph);
}
}
}Path Sum: Determine if the tree has a root-to-leaf path where values sum to a target.
Input: root = [5, 4, 8, 11, null, 13, 4, 7, 2], targetSum = 22
Output: true (path: 5 -> 4 -> 11 -> 2)
Tree:
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
Target = 22
DFS Path 1: 5 -> 4 -> 11 -> 7
Sum = 5 + 4 + 11 + 7 = 27 != 22
DFS Path 2: 5 -> 4 -> 11 -> 2
Sum = 5 + 4 + 11 + 2 = 22 == target
Found! Return true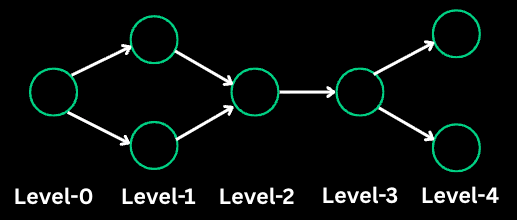
BFS explores nodes level by level, visiting all neighbors before moving deeper. It uses a queue and guarantees the shortest path in unweighted graphs.
Finding shortest path (unweighted)
Level-order traversal
Finding all nodes at distance k
Spreading problems (rotting oranges, walls and gates)
public void bfs(Node start) {
// Handle edge case
if (start == null) return;
// Initialize queue and visited set
Queue<Node> queue = new LinkedList<>();
Set<Node> visited = new HashSet<>();
// Add starting node
queue.offer(start);
visited.add(start);
// Process nodes level by level
while (!queue.isEmpty()) {
Node current = queue.poll();
// Process the current node
process(current);
// Add unvisited neighbors to queue
for (Node neighbor : current.getNeighbors()) {
if (!visited.contains(neighbor)) {
visited.add(neighbor);
queue.offer(neighbor);
}
}
}
}Level Order Traversal: Return the level order traversal of a binary tree.
Input: root = [3, 9, 20, null, null, 15, 7]
Output: [[3], [9, 20], [15, 7]]
Tree:
3
/ \
9 20
/ \
15 7
Step 1: Level 0
queue = [3]
Process 3, add children 9, 20
result = [[3]]
Step 2: Level 1
queue = [9, 20]
Process 9 (no children)
Process 20, add children 15, 7
result = [[3], [9, 20]]
Step 3: Level 2
queue = [15, 7]
Process 15 (no children)
Process 7 (no children)
result = [[3], [9, 20], [15, 7]]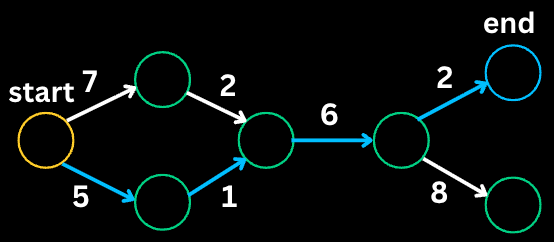
Shortest path algorithms find the minimum distance between nodes. Dijkstra’s works for weighted graphs with non-negative weights, while Bellman-Ford handles negative weights.
Finding minimum cost/distance paths
Network routing problems
Weighted graph traversal
Problems with varying edge costs
// Dijkstra's Algorithm using Priority Queue
int[] dist = new int[n];
Arrays.fill(dist, Integer.MAX_VALUE);
dist[source] = 0;
// PQ: (distance, node)
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
pq.offer(new int[]{0, source});
while (!pq.isEmpty()) {
int[] curr = pq.poll();
int d = curr[0], node = curr[1];
if (d > dist[node]) continue; // already processed
for (int[] edge : graph.get(node)) {
int neighbor = edge[0], weight = edge[1];
int newDist = dist[node] + weight;
if (newDist < dist[neighbor]) {
dist[neighbor] = newDist;
pq.offer(new int[]{newDist, neighbor});
}
}
}Network Delay Time: Find the time it takes for a signal to reach all nodes from a source node.
Input: times = [[2,1,1], [2,3,1], [3,4,1]], n = 4, k = 2
Output: 2
Graph: 2 --(1)--> 1
2 --(1)--> 3 --(1)--> 4
Source: node 2
Initial: dist = [INF, INF, 0, INF, INF] (1-indexed)
pq = [(0, 2)]
Step 1: Process (0, 2)
Neighbor 1: dist[1] = 0 + 1 = 1
Neighbor 3: dist[3] = 0 + 1 = 1
pq = [(1, 1), (1, 3)]
Step 2: Process (1, 1)
No outgoing edges
pq = [(1, 3)]
Step 3: Process (1, 3)
Neighbor 4: dist[4] = 1 + 1 = 2
pq = [(2, 4)]
Step 4: Process (2, 4)
No outgoing edges
dist = [INF, 1, 0, 1, 2]
Max distance = 2Matrix traversal uses DFS or BFS to explore 2D grids. The key is handling 4-directional (or 8-directional) movement and boundary checks.
Grid-based problems (islands, regions)
Flood fill algorithms
Finding connected components in 2D
Path finding in mazes
// Direction arrays for 4 directions
int[] dx = {0, 0, 1, -1};
int[] dy = {1, -1, 0, 0};
// DFS on matrix
void dfs(int[][] grid, int i, int j, boolean[][] visited) {
int m = grid.length, n = grid[0].length;
// boundary and validity check
if (i < 0 || i >= m || j < 0 || j >= n) return;
if (visited[i][j] || grid[i][j] == 0) return;
visited[i][j] = true;
// process cell
// explore 4 directions
for (int d = 0; d < 4; d++) {
dfs(grid, i + dx[d], j + dy[d], visited);
}
}
// BFS on matrix
Queue<int[]> queue = new LinkedList<>();
queue.offer(new int[]{startRow, startCol});
visited[startRow][startCol] = true;
while (!queue.isEmpty()) {
int[] cell = queue.poll();
int i = cell[0], j = cell[1];
for (int d = 0; d < 4; d++) {
int ni = i + dx[d], nj = j + dy[d];
if (ni >= 0 && ni < m && nj >= 0 && nj < n
&& !visited[ni][nj] && grid[ni][nj] == 1) {
visited[ni][nj] = true;
queue.offer(new int[]{ni, nj});
}
}
}Number of Islands: Count the number of islands (connected 1s) in a 2D grid.
Input:
grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]Output: 3
Grid:
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
Step 1: Find '1' at (0,0)
DFS marks connected cells: (0,0), (0,1), (1,0), (1,1)
islands = 1
Step 2: Find '1' at (2,2)
DFS marks: (2,2)
islands = 2
Step 3: Find '1' at (3,3)
DFS marks connected cells: (3,3), (3,4)
islands = 3
Result: 3 islands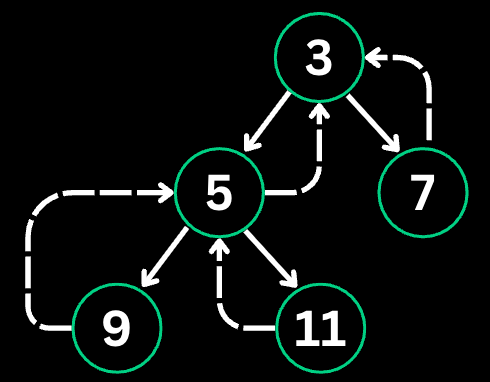
Backtracking explores all possible solutions by making choices, and undoes (backtracks) when a path leads to an invalid solution. It builds solutions incrementally.
Generating all permutations/combinations/subsets
Solving constraint satisfaction problems (N-Queens, Sudoku)
Finding all paths meeting certain criteria
String partitioning problems
public void backtrack(State state, Choices choices, Results results) {
// Base case: Is this a complete solution?
if (isComplete(state)) {
results.add(copy(state)); // Store the solution
return;
}
// Recursive case: Try each available choice
for (Choice choice : getAvailableChoices(state, choices)) {
// 1. CHOOSE: Make the choice
makeChoice(state, choice);
// 2. EXPLORE: Recursively explore with this choice
backtrack(state, choices, results);
// 3. UNCHOOSE: Undo the choice (backtrack)
undoChoice(state, choice);
}
}Subsets: Generate all possible subsets of an array.
Input: nums = [1, 2, 3]
Output: [[], [1], [1,2], [1,2,3], [1,3], [2], [2,3], [3]]
nums = [1, 2, 3]
backtrack([], start=0)
add [] to result
i=0: choose 1 -> [1]
backtrack([1], start=1)
add [1] to result
i=1: choose 2 -> [1,2]
backtrack([1,2], start=2)
add [1,2] to result
i=2: choose 3 -> [1,2,3]
backtrack([1,2,3], start=3)
add [1,2,3] to result
unchoose 3 -> [1,2]
unchoose 2 -> [1]
i=2: choose 3 -> [1,3]
backtrack([1,3], start=3)
add [1,3] to result
unchoose 3 -> [1]
unchoose 1 -> []
i=1: choose 2 -> [2]
...similar process
Result: [[], [1], [1,2], [1,2,3], [1,3], [2], [2,3], [3]]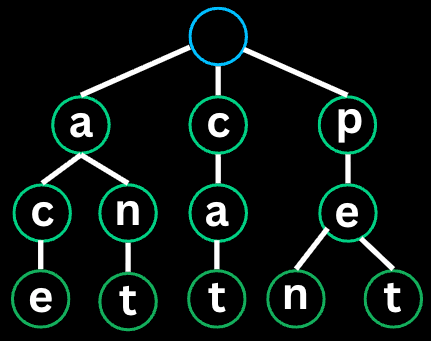
A Trie (prefix tree) stores strings character by character, allowing efficient prefix lookups. Each node represents a character, and paths from root to nodes represent prefixes.
Autocomplete and search suggestions
Spell checking
IP routing (longest prefix match)
Word games (finding valid words)
class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isEndOfWord = false;
}
class Trie {
TrieNode root = new TrieNode();
void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEndOfWord = true;
}
boolean search(String word) {
TrieNode node = searchPrefix(word);
return node != null && node.isEndOfWord;
}
boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private TrieNode searchPrefix(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) return null;
node = node.children[idx];
}
return node;
}
}Implement Trie: Implement a trie with insert, search, and startsWith methods.
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // returns true
trie.search("app"); // returns false
trie.startsWith("app"); // returns trueInsert "apple":
root
|
a (idx=0)
|
p (idx=15)
|
p (idx=15)
|
l (idx=11)
|
e (idx=4, isEndOfWord=true)
Search "apple":
Traverse: a -> p -> p -> l -> e
Node exists and isEndOfWord = true
Return true
Search "app":
Traverse: a -> p -> p
Node exists but isEndOfWord = false
Return false
StartsWith "app":
Traverse: a -> p -> p
Node exists (prefix found)
Return trueGreedy algorithms make locally optimal choices at each step, hoping to find a global optimum. They work when local optimal choices lead to global optimal solutions.
Optimization problems with greedy choice property
Interval scheduling
Huffman coding
Activity selection
When proof by exchange argument works
public Result solveGreedy(Input input) {
// Step 1: Sort or organize input (if needed)
sort(input, byGreedyCriterion);
// Step 2: Initialize result and tracking variables
Result result = initialResult();
State state = initialState();
// Step 3: Iterate and make greedy choices
for (Element element : input) {
if (canInclude(element, state)) {
// Make the greedy choice
result = update(result, element);
state = updateState(state, element);
}
}
return result;
}Jump Game: Determine if you can reach the last index starting from index 0.
Input: nums = [2, 3, 1, 1, 4]
Output: true
nums = [2, 3, 1, 1, 4]
Track maxReach (farthest index we can reach)
Step 1: i = 0, nums[0] = 2
maxReach = max(0, 0 + 2) = 2
Step 2: i = 1, nums[1] = 3
i <= maxReach (1 <= 2)
maxReach = max(2, 1 + 3) = 4
Step 3: i = 2, nums[2] = 1
i <= maxReach (2 <= 4)
maxReach = max(4, 2 + 1) = 4
Step 4: i = 3, nums[3] = 1
i <= maxReach (3 <= 4)
maxReach = max(4, 3 + 1) = 4
maxReach = 4 >= last index (4)
Return true
Dynamic Programming (DP) solves problems by breaking them into overlapping subproblems and storing results to avoid recomputation. It works when problems have optimal substructure.
Problems with overlapping subproblems
Optimization (min/max) problems
Counting problems (number of ways)
Decision problems (can we achieve X?)
Fibonacci Pattern (1D DP with previous states)
0/1 Knapsack (include or exclude each item)
Longest Common Subsequence (2D DP on two sequences)
Longest Increasing Subsequence
You can find more DP patterns and how to approach them in this article.
Climbing Stairs: Find the number of ways to climb n stairs, taking 1 or 2 steps at a time.
Input: n = 4
Output: 5
n = 4
dp[i] = number of ways to reach step i
dp[i] = dp[i-1] + dp[i-2]
(we can reach step i from step i-1 or step i-2)
Base cases:
dp[0] = 1 (one way to stay at ground)
dp[1] = 1 (one way: take 1 step)
Step 2: dp[2] = dp[1] + dp[0] = 1 + 1 = 2
Ways: [1,1], [2]
Step 3: dp[3] = dp[2] + dp[1] = 2 + 1 = 3
Ways: [1,1,1], [1,2], [2,1]
Step 4: dp[4] = dp[3] + dp[2] = 3 + 2 = 5
Ways: [1,1,1,1], [1,1,2], [1,2,1], [2,1,1], [2,2]
Result: 5 waysThat’s it. Thanks for reading!
I’ve put together many more patterns and problems on my website. You can explore them here: algomaster.io
If this article helped you, give it a like and share it with others.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。