
Datadog’s guide shows you how to connect AI spend, infrastructure, and model performance into a single view, so you can catch cost spikes the moment they happen. See how Kevel cut AWS costs by up to $100,000/month after replacing reactive cost reviews with real-time visibility.
You’ll learn how to:
Break down AI costs by token, model, provider, and team
Get alerted the instant inference volume spikes or API spend exceeds budget
Correlate cost increases directly to architecture changes so root-cause analysis takes minutes
DoorDash’s customer support chatbot had a hallucination problem. Not the dramatic kind where it invents entire conversations, but the subtle, harder-to-catch kind.
For example, the chatbot would look at a customer’s order history, see a delivery status field, misread it, and then confidently suggest a refund policy that didn’t actually exist. The raw data was right there in the chatbot’s context window, the working memory where an LLM holds everything it needs to generate a response, but having too much information was making things worse.
For reference, DoorDash is one of the largest food delivery and local commerce platforms in the United States, connecting customers with restaurants and stores through a network of independent delivery drivers called Dashers.
At that scale, the company handles hundreds of thousands of support contacts every day from customers, merchants, and Dashers, making automated support not just a nice-to-have but a necessity.
The team could see the problem clearly, but fixing it was a different story. Every change they made to reduce hallucinations in one scenario risked creating new ones in another. They were stuck between two bad options. They could deploy changes to production and hope for the best, which meant risking real customer experiences. Or they could manually test dozens of conversation scenarios for every prompt change, which would take weeks and still might miss things.
This tension isn’t unique to DoorDash. It’s the fundamental challenge anyone faces when they move from traditional deterministic software to LLM-based systems. DoorDash used to run customer support on hand-built decision trees, where every change had a predictable, traceable impact. LLMs replaced that predictability with flexibility and more natural conversations, but they also introduced non-determinism, meaning the same input can produce different outputs each time.
DoorDash’s answer to this problem wasn’t a better chatbot. It was a better system for improving the chatbot, something they call the simulation and evaluation flywheel. In this article, we will learn how they built this flywheel and the key takeaways.
Disclaimer: This post is based on publicly shared details from the DoorDash Engineering Team. Please comment if you notice any inaccuracies.
The flywheel has two interconnected pieces:
The first is an offline simulator that generates realistic multi-turn customer conversations without involving any real customers.
The second is an evaluation framework that automatically grades how the chatbot performed in those conversations.
Together, they create a tight iteration loop.
When the team notices a problem, they write an evaluation that captures the specific failure mode they want to fix. A single job trigger then orchestrates the entire pipeline end-to-end, automatically generating test scenarios from historical transcripts, running multi-turn conversations between the simulator and the chatbot, and evaluating the results.
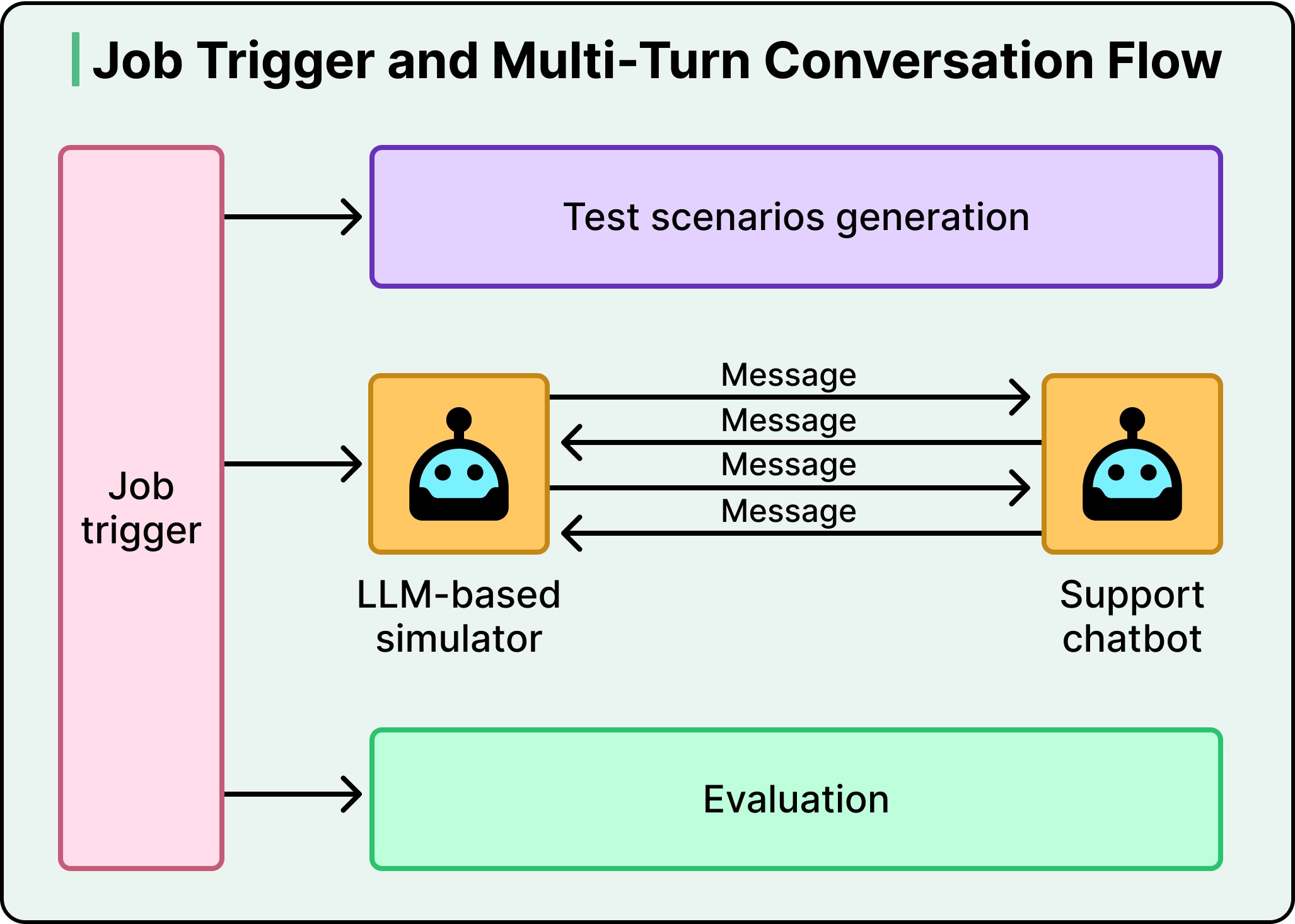
Then they modify the prompt or the system architecture, run the simulator again, and check whether the pass rate climbed. If it did, they would keep going. If it didn’t, they try something else. They repeat this cycle until the pass rate hits their exit criteria, and then they deploy with confidence that the change actually works.
The graph below shows the pass rate for no-hallucination evaluation over time
The speed of this loop makes this a powerful approach. DoorDash can run more than 200 simulated conversations in under five minutes and get automated evaluation results immediately.
In other words, what used to take days of manual testing and review now takes hours. And because everything happens offline, they never risk degrading the experience for real customers while they iterate.
Their evaluation suite has grown to more than 50 evaluations covering hallucination detection, tone assessment, issue classification, and other quality dimensions. Before any change goes to production, it must pass the full suite, which serves as both a quality check and a regression test.
The flywheel sounds straightforward, but both the simulator and the evaluator required solving genuinely hard problems.

Speed without control is a false economy. As AI code-generation accelerates software delivery, the FeatureOps Summit 2026 is here to ensure that when we ship more, we break less.This premier virtual event brings together engineers, architects, and product leaders to explore the infrastructure of fearless delivery.
Key Themes:
AI Safety Nets: Guardrails for the flood of automated code.
Edge Resilience: Sub-millisecond evaluation at scale.
Continuous Flow: Moving past the “fixed-release” mindset. Register today to master the tools and patterns required for a fail-safe release environment.
A static test case can check whether the chatbot gives a reasonable answer to a single message, but it can’t capture what happens when a frustrated customer pushes back three times, provides additional information mid-conversation, or threatens to escalate.
DoorDash’s simulator doesn’t use scripted messages at all.
Instead, it uses an LLM to play the customer role, generating dynamic responses based on detailed test scenarios. At each turn, the simulator runs through a structured analysis, asking questions such as:
Was the issue addressed?
Is the conversation making progress?
Does the customer need to provide more information?
Is the conversation going in circles?
Based on this analysis, it decides what a realistic customer would say next.
The test scenarios themselves come from real historical support transcripts, not from engineers imagining what customers might say.
LLMs analyze past conversations from DoorDash’s database and extract structured behavioral profiles, including the customer’s personality traits (frustrated and demanding versus confused and patient), a detailed narrative of the situation, and the specific outcome the customer is seeking. This grounds the simulator in actual customer behavior rather than idealized test cases.
See the diagram below:
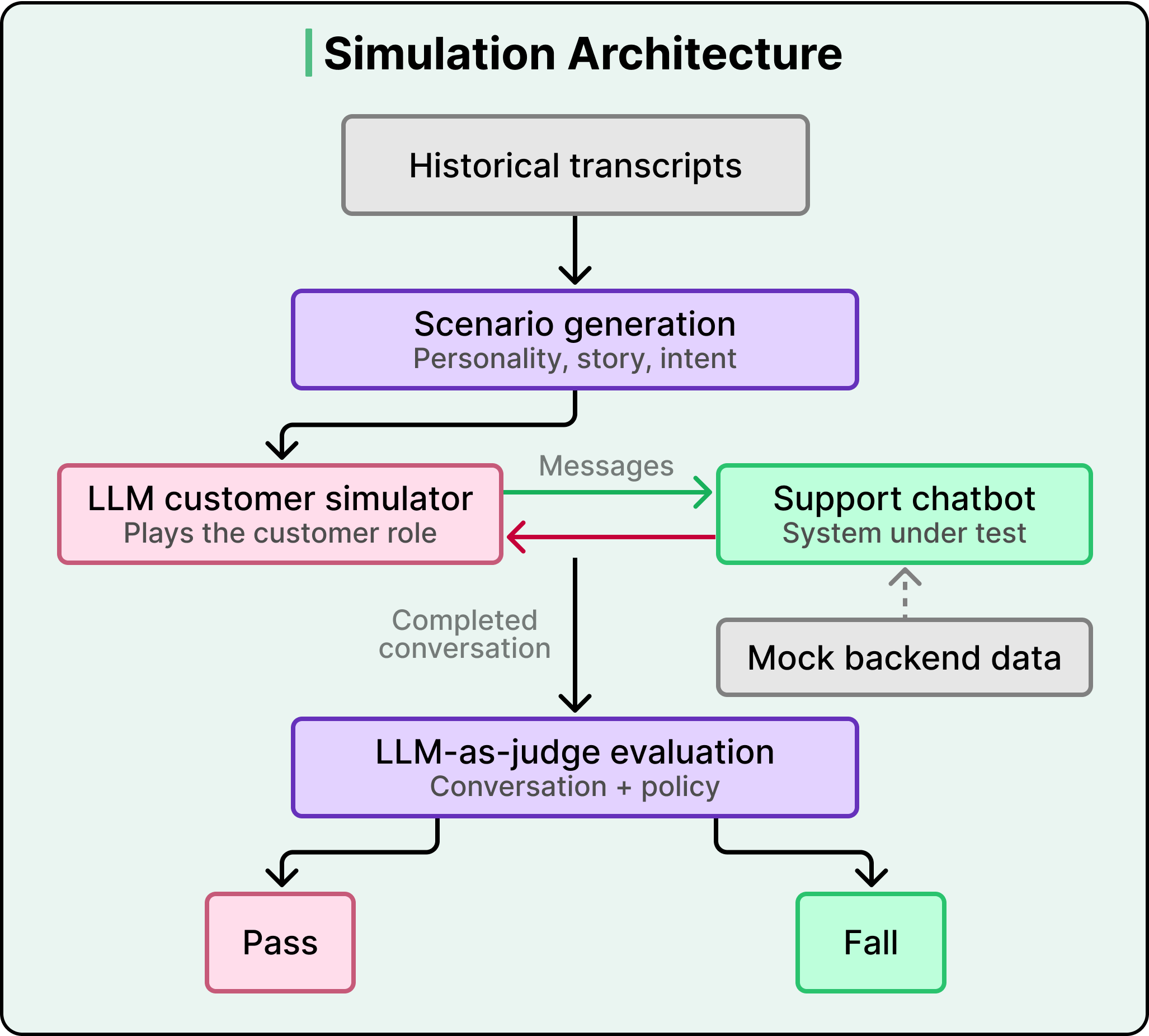
The simulator also exhibits realistic escalation patterns. It doesn’t immediately ask for a manager. Instead, it gives the chatbot multiple chances to resolve the issue, only escalating after repeated unhelpfulness or circular exchanges, and re-engaging when progress becomes clear again. This mirrors how real customers behave.
For a simulated conversation to be meaningful, the chatbot also needs realistic backend data. It needs to look up delivery status, check refund eligibility, and pull order details. DoorDash handles this through mock data that blends real production data with scenario-specific test data, preserving timestamps and relationships to keep interactions realistic. This allows them to test complex edge cases, including fraud scenarios and high-value refunds, that their previous testing infrastructure couldn’t handle.
Running hundreds of realistic conversations is only useful if you can tell whether the chatbot actually handled them well. However, manually reading through every simulated conversation would defeat the entire purpose of automation. So DoorDash uses an LLM to evaluate the chatbot’s performance automatically.
Each evaluation is structured as a function that takes the full conversation transcript (including tool calls and backend responses) along with the relevant company policy, applies a prompt asking whether the chatbot correctly followed that policy, and returns a binary pass or fail with the reasoning behind the judgment.
The obvious objection here is that this sounds circular. If an LLM caused the problem by hallucinating, why would you trust another LLM to catch the hallucination?
DoorDash addresses this directly with a concept they call the generator-verifier gap. Acting as a full customer support agent involves complex, multi-step decision-making across a huge range of possible scenarios. That’s genuinely hard. But verifying a single, narrowly-defined behavior is a much simpler task.
For example, “Did the chatbot claim the customer was eligible for a refund when the policy says otherwise?” is a straightforward binary question. The evaluator isn’t trying to be a better support agent. It’s checking one specific thing at a time, and LLMs are much more reliable at these focused binary judgments than they are at open-ended generation.
But DoorDash doesn’t just trust the LLM judge out of the box. They calibrate it against human judgment through a structured process. They collect a sample of conversations, have human experts label each one as pass or fail, run the LLM judge on the same samples, and then measure how often the judge agrees with the humans and how often it misses problems or flags false ones. They analyze the reasoning behind any mismatches, revise the evaluation prompt to fix systematic errors, and repeat until the judge reliably matches human expert judgment. This calibration step creates trust in the system.
The binary nature of the evaluations is important here. DoorDash isn’t asking the LLM to rate the chatbot’s performance on a subjective scale of 1 to 10. They’re asking whether the chatbot followed a specific policy or not. It makes calibration faster, makes disagreements easier to diagnose, and produces more reliable judgments.
With the simulator generating conversations and the evaluator grading them, DoorDash had a working flywheel.
During early launches, human reviewers noticed the chatbot was getting overwhelmed by the sheer volume of data in its context window. Order histories, delivery status updates, refund decisions, and tool call results were all being fed directly to the model as raw event logs. The chatbot would misinterpret a field or suggest a policy that didn’t exist, not because the information was wrong, but because there was too much of it. This runs directly counter to the intuition that giving a model more information should produce better results.
DoorDash hypothesized that the same data that was vital for the chatbot’s reasoning was becoming noise when it came time to generate a response to the customer. Their solution was an architectural layer they called the “case state,” which synthesizes the raw tool history into a structured, intermediate representation. Instead of dumping everything into the context window, the case state distills the relevant facts into a clean format that the chatbot can actually use.
Getting the case state right required the flywheel. Their first attempts at extraction logic didn’t work well at all. Some versions left out critical information, causing the chatbot to miss details that were essential for driving resolutions. Other versions remained too noisy or poorly structured, confusing the model in different ways. Since the simulator could generate numerous realistic conversations in minutes, the team experimented with dozens of different context shapes and prompt strategies in a rapid feedback loop. Each iteration took hours instead of the weeks it would have required through manual testing.
Over 11 iterations, the hallucination evaluation pass rate climbed steadily upward, with a notable dip at iteration 3, where a change actually made things temporarily worse. That dip shows that improvement isn’t linear, even with a flywheel, and that part of the flywheel’s value is catching regressions before they reach real customers.
The final result was a 90% reduction in hallucinations in simulation, and that improvement carried over into production. The strong correlation between their offline metrics and live traffic performance gave the team confidence that the flywheel is a reliable development tool, not just an internal sandbox disconnected from reality.
The simulation and evaluation flywheel has fundamentally changed how DoorDash develops and deploys chatbot improvements, compressing iteration cycles from days to hours and giving them a way to validate changes across hundreds of scenarios before any real customer is affected.
However, the flywheel does come with real tradeoffs worth understanding.
The main limitation is that it can only catch problems for which you’ve written evaluations. If a failure mode isn’t captured by an evaluation, the flywheel is blind to it. DoorDash mitigates this by running a full evaluation suite before every deployment, covering hallucination, tone, and issue classification, but new failure modes can always emerge that existing evaluations don’t cover. This is why human review remains the starting point for every improvement cycle. Despite all the automation, someone still has to look at real conversations and notice what’s going wrong.
Simulation fidelity is another inherent limitation. Even with transcript-derived scenarios and hybrid mock data, synthetic conversations are approximations of real user behavior. DoorDash reports a strong correlation between its offline metrics and production results, which validates the approach, but that correlation isn’t guaranteed to hold for every type of scenario or every kind of system change.
There’s also the question of cost. Running hundreds of LLM-to-LLM conversations per test cycle, plus LLM-as-judge evaluations on each one, requires significant compute. For smaller teams or less critical applications, a lighter-weight version with fewer scenarios and more targeted evaluations might be the pragmatic starting point.
The broader takeaway is that LLM systems require a completely different testing paradigm than traditional software. Since we can’t trace the branch anymore, we need a feedback loop that lets us simulate, evaluate, and iterate fast enough to build confidence before shipping.
References: