Introduction: An Illusion of "Simplicity"
A narrative has recently become common within the team: "Building an Agent is simple now. You can just piece it together with LangChain, BaiLian, or Flowise, and it runs."
At first glance, this statement is hard to refute—frameworks have indeed lowered the barrier to entry. But that "simplicity" is more of an illusion, a facade created after the complexity has been temporarily absorbed by the platform. From a technical standpoint, Agent development involves:
- Orchestration and task planning;
- Context and Memory management;
- Domain knowledge fusion (RAG);
- And the "agentification" of business logic.
These steps are not accomplished just by writing a few prompts. When developers feel it's "simple," it's because the complexity has been absorbed by the platform. The difficulty of Agents lies not in getting a demo to run, but in making it operate reliably, controllably, and sustainably over the long term.
Why Is Agent Development Mistakenly Seen as "Simple"?
On the surface, we are in an era of explosive AI growth, with platforms and tools emerging endlessly. It's true that by writing a few prompts and connecting a few chains, a "functional" Agent can be born. But this doesn't mean the complexity has vanished. Instead, the complexity has been relocated.
I break this "simplicity" down into three illusions:
1. Encapsulated Complexity
Frameworks help you string prompts and trim context, shielding developers from the details. But the underlying mechanics—debugging, tracing, and state recovery—are still burdens you must bear alone.
Take LangChain as an example. A "question-answering" Agent can be created with just a few lines of code:
from langchain.agents import initialize_agent, load_tools
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent_type="zero-shot-react-description")
agent.run("What is the current weather in Singapore, and convert it to Celsius?")
This code hides almost all complexity:
- Prompt assembly, call chains, and context management are encapsulated internally.
- But if the task fails (e.g., API rate limiting, tool failure), the Agent defaults to neither retrying nor logging a trace.
What looks like a "simple run" actually means sacrificing the interfaces for observability and debugging.
2. Outsourced Complexity
Memory, RAG, and Embeddings are all handed over to the platform for custody. The price is the loss of the ability to intervene and explain.
In LangChain, you can quickly add "memory":
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
But this is just a short-term memory buffer. It doesn't handle:
- Conflicts with old information;
- State drift over multiple turns;
- Or context truncation issues due to excessive length.
As the Agent scales, memory consistency and state cleanup become new sources of system complexity.
3. Postponed Complexity
It doesn't disappear; it just reappears during the execution phase:
- Output drift
- Inability to reproduce results
- Collapse of correctness and stability
Being able to run does not equal being able to run correctly over the long term. What we call simplicity is often just us temporarily avoiding the confrontation with complexity.
The Three Layers of Agent System Complexity
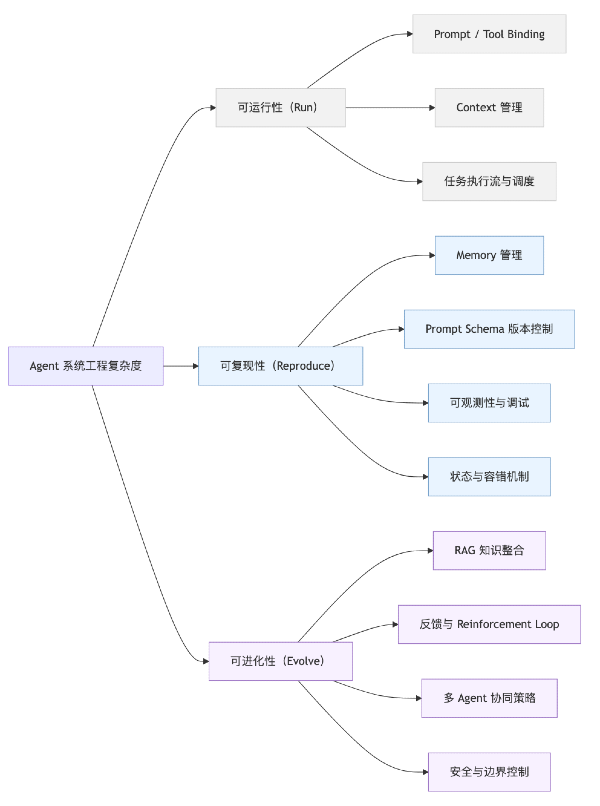
1. Agent Complexity
The complexity of an Agent system manifests in its ability to be run, reproduced, and evolved. Most current Agent frameworks have solved "runnability," but "reproducibility" and "evolvability" remain significant system engineering challenges.
| Level | Core Objective | Engineering Keywords | LangChain Example Explanation |
|---|---|---|---|
| Runnability (Run) | Enable the Agent to start and execute tasks | prompt, context, tool calls, execution flow | Rapidly assembling an executable chain via initialize_agent |
| Reproducibility (Reproduce) | Make behavior controllable and debuggable | memory, state, logs, versioning | No built-in version tracking; Memory state drift requires manual management |
| Evolvability (Evolve) | Allow the system to continuously improve | RAG, feedback loops, collaboration, safety boundaries | Supports vector retrieval, but lacks self-assessment and reinforcement learning mechanisms |
At the "Runnability" level, the abstractions designed by frameworks like LangChain are indeed efficient. But to make an Agent's behavior stable, explainable, and continuously optimizable, additional infrastructure—such as logging systems, prompt version management, and feedback loops—is still required.
From a system engineering perspective, the difficulty of an Agent lies not in "generation" but in "execution." All platforms will eventually expose their costs along these two lifecycles.
| Dimension | Definition | Common Issues | Essence |
|---|---|---|---|
| Correctness | Is each decision correct? | Hallucinations, incorrect tool calls, logical deviations | The output logic is wrong |
| Stability | Is the system reproducible? | State drift, infinite loops, random fluctuations | The behavior is uncertain |
In the implementation phase, stability is often more critical than correctness. Only when stability exists can correctness even be verified and optimized.
Intelligence's uncertainty must be underpinned by engineering's certainty. Stability and observability are the prerequisites for an Agent to be truly evolvable.
2. The Agent Amplification Effect
As shown in the image above, the same model (qwen-max), the same time, and the same prompt produce different results. This is the amplification effect that LLM uncertainty brings to Agents. Compared to the traditional software systems developers are most familiar with, the complexity and difficulty of Agents stem from this uncertainty, amplified at each semantic level by the LLM.
If a single LLM interaction has a 90% correctness rate, an Agent system requiring 10 LLM interactions will have its correctness drop to just 35%. If it requires 20 interactions, the correctness plummets to 12%.
Memory's Uncertainty Amplification
Traditional software state management is deterministic (e.g., what's in the database is what's in the database). An Agent's memory, however, relies on LLM parsing, embedding, and retrieval. The results are highly uncertain. Therefore, memory is not a storage/retrieval problem, but a semantic consistency problem. This is unique to Agents.
Orchestration's Dynamic Amplification
In traditional systems, orchestration (workflow) is a fixed, predefined process. In an Agent, the orchestration—which tool to call next, and how—is often dynamically decided by the LLM. This means the orchestration problem isn't just about "sequence/concurrency"; it's about an explosion of the decision space, making testing, monitoring, and optimization far more complex.
Testability's Unpredictability Amplification
Traditional software is predictable: given input → expected output. An Agent's output is a probability distribution (a stream of tokens from the LLM); there is no strict determinism. Therefore, testing cannot rely solely on unit tests. It must incorporate replay testing, baseline comparison testing, and simulation environment testing, which is far beyond the difficulty of standard application testing.
3. From "Runnable" to "Usable"
The "'It Runs, Doesn't It?' Fallacy"
Some might say, "I can get the Agent to work just by modifying the prompts. Am I amplifying the problem myself, rather than the Agent?"
"Getting it to run by tweaking prompts" essentially means: Short-term goal + High tolerance = Good enough.
The goal of an Agent system, however, is: Long-term goal + Engineering-grade reliability = Drastic increase in difficulty.
Let's first look at why tweaking prompts seems to work. Many Agent Demos or POCs (Proofs of Concept) aim for one-off tasks, like "write a summary for me" or "call this API." In these low-requirement scenarios, the raw power of the LLM masks many underlying issues:
- Memory can be passed purely through context (long-term persistence is never really tested).
- Orchestration can be hard-coded or hinted at in the prompt.
- Testability is irrelevant; if it gets the right answer once, it's a win.
The problem is that when the requirement shifts from a "Demo" to a "Sustainably Usable System," these issues are rapidly amplified:
Prompt Modification ≠ Reliability Guarantee. Changing a prompt might fix the immediate bug, but it doesn't guarantee the same class of problem won't reappear in another case. You haven't established reproducible, maintainable decision logic; you've just engaged in "black-box tweaking."Prompt Modification ≠ Scalability. Prompt hacking works for a single-task Agent. But in a multi-tool, multi-scenario Agent, the prompt's complexity grows exponentially and eventually becomes uncontrollable.Prompt Modification ≠ Engineering Controllability. Traditional software can be covered by test cases to ensure logical coverage. Prompts can only partially mitigate the LLM's probabilistic fluctuations; they cannot provide strong guarantees.
This is why, ultimately, we need more structured methods for memory, orchestration, and testing—which is to say, Agent systematization.
Limitations of Agent Frameworks
Let's use the LangChain framework as an example to see if frameworks can solve the three layers of Agent complexity. LangChain provides a basic CallbackManager and LangSmith integration for tracing an Agent's execution. This functionality is often overlooked, but it is key to understanding "reproducibility" and "observability."
from langchain.callbacks import StdOutCallbackHandler, CallbackManager
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, load_tools
# Create a simple callback manager
handler = StdOutCallbackHandler()
manager = CallbackManager([handler])
llm = OpenAI(temperature=0, callback_manager=manager)
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent_type="zero-shot-react-description")
agent.run("Calculate (15 + 9) * 2")
When executed, LangChain will output every Thought and Action to the console:
Thought: I need to use the calculator tool.
Action: Calculator
Action Input: (15 + 9) * 2
Observation: 48
Thought: I now know the final answer.
Final Answer: 48
This seemingly simple output reveals three important facts:
- The Agent's internal decision process is traceable (this is the prerequisite for reproducibility).
- The CallbackManager must be actively enabled by the engineer (it doesn't log by default).
- The granularity of observation is limited (it cannot directly trace context trimming, memory overwrites, etc.).
LangSmith provides a more complete visual trace, but it remains an external observation tool. The Agent framework itself still lacks built-in verification mechanisms. In other words, the framework gives you the ability to "see," but it doesn't solve the problem of "control" for you.
Although frameworks like LangChain are making interesting attempts to solve the complex problems in Agent systems, we must admit that most engineering dimensions remain unresolved. (In short, frameworks solve the problem of "using an LLM to do things," but not the problem of "making the LLM do things in a way that is controllable, sustainable, and scalable like a system"):
| Module | What Frameworks Provide | What Remains Uncovered / Needs Engineering |
|---|---|---|
| Inference Layer (LLM Layer) | Model calls, Prompt templates | Output stability, task context constraints, hallucination detection |
| Tools Layer | API calls, Function routing | Secure tool sandbox, permission control, error recovery |
| Memory Layer | Basic vector retrieval, session context | Long-term memory compression, conflict detection, memory decay strategy |
| Orchestration Layer | Simple loops or chained calls | Multi-task scheduling, plan optimization, inter-agent dependency graphs |
| Evaluation Layer | Some tracing, benchmarks | Automated metrics (success rate, controllability, cost monitoring) |
| Safety & Compliance | Almost non-existent | Execution boundaries, permission models, audit logs, sandboxed execution |
| Deployment & Ops | Some SDKs, CLI tools | Persistence, elastic scaling, version management, A/B testing mechanisms |
| Framework | Runnability | Reproducibility | Evolvability | Notes |
|---|---|---|---|---|
| LangChain | ✅ Mature chain calls | ⚙️ Partially observable | ⚙️ Manual tuning | Many tools, but state is unstable |
| AutoGen | ✅ Multi-Agent collaboration | ⚙️ Rudimentary memory | ❌ Lacks learning mechanism | Flexible but hard to reproduce |
| CrewAI | ✅ Easy task orchestration | ⚙️ State instability | ❌ No feedback optimization | Strong interaction, weak control |
| AliCloud BaiLian | ✅ Drag-and-drop building | ⚙️ Platform logs | ⚙️ Built-in knowledge center | Platform absorbs complexity, but is a major black box with limited control |
- ✅ Runnability: Generally well-supported (low barrier to entry)
- ⚙️ Reproducibility: Only partially supported (requires self-built state and observation layers)
- ❌ Evolvability: Still relies on manual effort and system design
LangChain makes Agents "buildable," but it makes the system lose its "explainability." Complexity didn't disappear; it just migrated from the code layer to the runtime.
Let's delve deeper into runtime complexity. The new problem Agent systems bring is that they don't just "run"; they must "continuously think," and the side effect of thinking is instability. This is not "traditional code complexity" but "system uncertainty introduced by intelligent behavior." It makes Agent engineering feel more like managing a complex adaptive system than a linear, controllable piece of software.
| New Dimension of Complexity | Description | Example Scenario |
|---|---|---|
| Context Drift | The model misunderstands or forgets key task objectives during multi-turn reasoning | An Agent deviates from the task's semantics during a long conversation, executing irrelevant actions |
| Semantic Non-determinism | The same input may produce different outputs, making processes non-replayable | Prompt debugging results are unstable; automated testing is hard to cover |
| Task Decomposition & Planning | The quality of plans generated by the LLM is unstable; task boundaries are vague | In AutoGen's "plan+execute" model, sub-tasks overflow or loop |
| Memory Pollution | Long-term stored context introduces noise or conflicting information | The Agent "learns" incorrect knowledge, causing future execution deviations |
| Control Ambiguity | The boundary between the Agent's execution and the human/system control layer is unclear | Manual instructions are overridden, tasks are repeated, resources are abused |
| Self-Adaptation Drift | The Agent learns incorrect patterns or behaviors based on feedback | Reinforcing a hallucinatory response during an RLHF/reflection loop |
| Multi-Agent Coordination | Communication, role assignment, and conflict resolution between Agents | Task duplication or conflicts in multi-role systems like CrewAI |
The Only Solution for Agents is Systematization
- Prompt Hacking fails when the problem scales. For a single, simple scenario, tweaking a prompt works. But as task complexity and the number of scenarios increase, the prompt becomes bloated and uncontrollable (e.g., one prompt stuffed with dozens of rules). It's like concatenating strings to build SQL queries: it runs at first, but inevitably leads to injection vulnerabilities and a maintenance disaster. Systematization helps by providing structured constraints and automated orchestration, rather than manual prompt tuning.
- Uncertainty demands controllability. Getting it right once is a win for a demo. But in a production environment, you need 99% correctness (or 100%). Even a 1% hallucination rate will accumulate into a disaster. For example, a log analysis Agent that misses or false-reports an issue just once could lead to an undiscovered online incident. Systematization ensures controllability through testing, monitoring, and replay verification, rather than gambling on luck every time.
- Knowledge persistence vs. repeating mistakes. Today, an Agent's bug is fixed by changing a prompt. Tomorrow, a new requirement comes in, and the exploration starts all over again. Knowledge isn't retained. The Agent can't remember or reuse past solutions, leading to constant redundant labor. A colleague complained that in one business system, prompt modification commits made up over a third of all code commits. Yet, when another colleague tried to reuse that prompt for a similar problem, it was completely non-transferable and had to be hacked again from scratch. Systematization, through
Memory + Knowledge Bases, ensures an Agent can learn and accumulate knowledge, not reinvent the wheel every time.
Prompt Hacking / Demo Agents solve "small problems." Only Systematized Agents can solve the problems of "scalability, reliability, and persistence." These issues might not be obvious now, but they will inevitably explode as usage time and scope expand.
A Demo Agent can solve today's problem. A Systematized Agent can solve tomorrow's and the day after's.
| Dimension | Demo Agent (Can run) | Systematized Agent (Can run sustainably) |
|---|---|---|
| Goal | Single task / POC success | Continuous, repeatable, multi-dependent business processes |
| Memory/Knowledge | Raw chat history; occasional vector retrieval | Layered memory (session/short-term/long-term + RAG strategy); consistency & versioning |
| Orchestration/State | Sequential calls / simple ReAct; no explicit state | Explicit state machine / graph (concurrency, rollback, retry, timeout, fault tolerance) |
| Reliability & Testing | "Passes the example" is the standard; non-reproducible | Replay sets / baseline comparison / fuzz testing; SLOs & failure mode design |
| Observability | A few log lines | End-to-end tracing, call chains, metrics, auditing |
| Security/Permissions | Constraints written in the prompt | Fine-grained permissions / sandbox / audit trails / anti-privilege-escalation |
| Scalability | Prompt becomes uncontrollable as scenarios grow | Modular components / model routing / tool governance |
| Cost Curve | Fast/cheap initially; maintenance costs skyrocket later | Upfront engineering investment; stable and scalable long-term |
From "Smart" to "Reliable"
Some Real-World Agent Cases
Looking at history, we can understand rise and fall. Looking at others, we can understand our own successes and failures. The problems I've encountered in Agent system development are surely not mine alone. I asked ChatGPT to search Reddit, GitHub, and blogs for Agent development cases, hoping to use others' experiences to validate my own thinking and reflections:
1. Typical Failures of Toy-Level Agents
- Auto-GPT community feedback: looping, getting stuck, unable to complete tasks (the classic early example of "runnable but not reliable"). Auto-GPT seems nearly unusable
- Developer questioning if agents can go to production, noting severe step-skipping/hallucinations in multi-step tasks (system prompt + function calling isn't enough). Seriously, can LLM agents REALLY work in production?
- OpenAI Realtime Agents official example repo issue: Even the "simple demo" has too many hallucinations to be usable non-demo contexts. Lots of hallucinations?
2. Engineering Problems Exposed After Production (Not solvable by prompt changes)
- LangGraph deployment under production concurrency pressure: "can't start a new thread" (a resource/concurrency issue triggered by parallel nodes in Celery). Handling "RuntimeError: can't start a new thread" error at production.
- LangChain version upgrade breaks a production multi-agent app (
__aenter__): Highlighting the need for explicit dependencies, version locking, and regression testing. AgentExecutor ainvoke stopped working after version upgrade
3. Industry/Big-Tech Postmortems: Why "Systematization" is Needed
- Anthropic: Effective agents come from "composable simple patterns + engineering practices," not from piling on frameworks (summarized from many client projects). Building Effective AI Agents
- OpenAI: Released Agents SDK + built-in observability, stating clearly "it's hard to turn capabilities into production-grade agents" and requires visualization/tracing/orchestration tools. New tools for building agents
- AWS Strands Agents SDK: Official emphasis on production-grade observability as a key design point, with built-in telemetry/logging/metrics hooks. Strands Agents SDK: A technical deep dive into agent architectures and observability
- Salesforce (Agentforce) Blog: Summarizes 5 top reasons for production failures (silent retrieval failures, lack of fault tolerance, using ReAct as orchestration, etc.), advocating for engineered RAG/fault-tolerance/evaluation. 5 Reasons Why AI Agents and RAG Pipelines Fail in Production (And How to Fix It)
- LangChain Team: Why build LangGraph/Platform—for control, durability, long-running/bursty traffic, checkpoints, retries, and memory. Claims it's used in production by LinkedIn/Uber/Klarna (vendor claims, but highlights the "systematization elements"). Building LangGraph: Designing an Agent Runtime from first principles
4. Positive Case: Treating it with a "Distributed Systems Mindset"
- Community experience: Treating LLM orchestration as a distributed system. Using retry/backoff/idempotency/circuit-breakers/persistent queues to get a multi-step workflow completion rate to 99.5% (an engineering post, emphasizing "systematic" methodology). Production LLM reliability: How I achieved 99.5% job completion despite constant 429 errors
- Developer feedback on LangGraph being production-viable: Migrated from LangChain's Agent Executor; the prototype→streamline→retain-necessities path is more robust (de-hallucinate/de-fancy, retain control). Anyone Using Langchai Agents in production?
The Four Stages of Agent Development
Over more than a year of Agent development, I've gone through a cognitive shift from "Agents are simple" to "Agents are truly complex." At first, I treated frameworks as black boxes, writing prompts and piecing things together to run a demo. As the complexity of the scenarios increased and I needed to go deeper into Agent system R&D, the difficulties gradually revealed themselves. I've tried to break down this "simple → truly hard" process:
Stage 1: The "Hello World" Stage (Looks simple)
Using frameworks like LangChain / AutoGen / CrewAI, you can get something running in a few lines of code. Most people stop at "it can chat" or "it can call tools," so they feel "Agent development is just this."
Stage 2: The Scene Adaptation Stage (Starting to hit pitfalls)
As the complexity of the problems the Agent solves increases, you slowly run into the LLM context window limit, requiring trimming, compression, or selection (i.e., Context Management problems). You find that vector retrieval results are often irrelevant, leading to non-answers, requiring optimization of preprocessing and query rewriting (RAG Knowledge Management). It runs in simple scenes, but falls into traps in slightly more complex ones.
Stage 3: The Systematization Stage (Complexity explodes)
Going further, as tool calls and context management increase, the Agent must ensure consistency across sessions and tasks. You must consider persistence, version control, and conflict resolution. A single Agent can't adapt to complex tasks; you need multi-Agent collaboration. At this point, you must solve deadlock, task conflicts, and state rollbacks. When task complexity rises, debugging the Agent flow can't be solved by tweaking prompts; you must add tracing and observability tools.
Stage 4: The Engineering Landing Stage (The real hard part)
- Agentifying Business Logic: How to test it? How to guarantee controllability and stability?
- Security & Compliance: Permissions, privilege escalation, data leakage. Strict security boundaries are a must.
- Monitoring & SLOs: Like operating microservices, you need monitoring, alerting, and failure recovery.
In summary, frameworks like LangChain lowered the "barrier to entry" for Agents, but they did not lower the "barrier to implementation."
My Cognitive Evolution in Agent Development
I have been developing an Agent system focused on vulnerability and security assessment in my own work. As I experienced the four stages of Agent development mentioned above, my thinking and understanding of Agents also changed:
Level 0: The Framework Illusion Layer
- Typical Behavior: Install LangChain / AutoGen / CrewAI, run an official demo, modify a prompt.
- Cognitive Trait: Believes "Agent Development = Writing Prompts." The barrier to entry is extremely low, similar to writing a script.
- Misconception: Thinks the framework solves all complexity, ignoring memory, orchestration, testing, and security.
Level 1: The Scene Splicing Layer
- Typical Behavior: Can stitch together RAG, tool calls, and simple multi-agent orchestration to build a seemingly viable prototype.
- Cognitive Trait: Begins to realize the importance of context management and RAG strategies.
- Pain Points: Encounters "irrelevant answers," "memory corruption," and "tasks failing to complete reliably."
- Misconception: Tries to use prompt hacking to solve all problems, ignoring underlying information management and system design.
Level 2: The System Design Layer
- Typical Behavior: Treats the Agent as a microservices system, needing to consider architecture, observability, and state management.
- Cognitive Trait: Understands that memory is essentially a database/knowledge-base problem, and orchestration is more like workflow scheduling than a chat.
- Pain Points: Debugging costs are extremely high; requires tracing, logging, and metrics monitoring.
- Key Challenge: How to ensure the Agent is robust, controllable, and reproducible.
Level 3: The Engineering Landing Layer
- Typical Behavior: Deploys the Agent into a production business environment.
- Cognitive Trait: Treats Agent development as an engineering discipline, just like SRE / Security / Distributed Systems.
- Pain Points:
- Testability: The non-determinism of LLMs makes it impossible to guarantee stability with traditional unit tests.
- Security: Permission management, privilege escalation, prompt injection protection.
- Monitoring & SLOs: The Agent must be observable and recoverable, just like a service.
- Key Challenge: How to make the Agent reliable enough to carry critical business functions.
Level 4: The Intelligent Evolution Layer (Frontier Exploration)
- Typical Behavior: Attempting to build an Agent system with long-term memory, autonomous learning, and evolvability.
- Cognitive Trait: No longer sees the Agent as an LLM wrapper, but as a new type of distributed intelligent system.
- Challenges:
- Memory becomes a knowledge graph + adaptive learning problem.
- Orchestration involves game theory, collaboration, and even emergent behavior.
- Security requires "AI sandboxes" to prevent loss of control.
- Status: Most are not at this stage; it is primarily research and experimentation.
Based on my current understanding of Agents, I now position them as system components rather than intelligent robots. My goal is not "occasional brilliance" but "sustained reliability."
Basic Principles:
- Principles:
- Stable first, smart second.
- Observable first, optimized second.
- Functionality:
- Establish a replayable mechanism for state and logs.
- Implement version tracking for Prompts / Memory / RAG.
- Introduce observability metrics (success rate, drift rate, redundant calls).
- Clearly define the boundaries and permission scope for each Agent.
- Designate "error recovery" pathways in the architecture.
- Boundaries:
- If the Agent is only for one-off tasks or exploratory experiments, complexity control can be relaxed.
- If used for production tasks (monitoring, automated operations), stability and security boundaries take precedence.
- The deeper the framework's encapsulation, the more an external explainability layer is needed.
The Path to Agent Intelligence
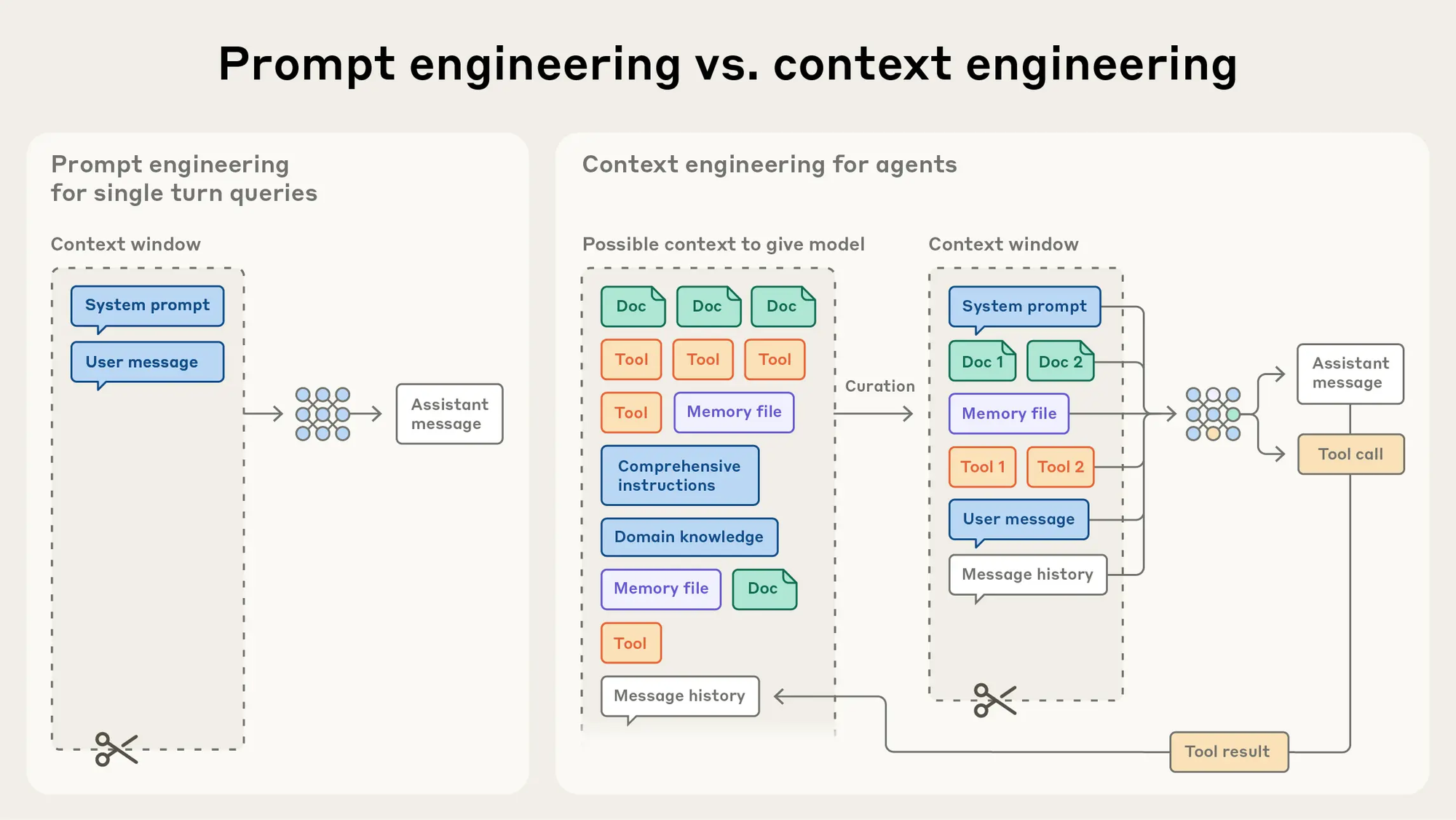
Someone said 2025 might be the "Year of the Agent." After nearly a year of technical iteration, Agents have also seen considerable development from an engineering perspective. LangChain has essentially become the preferred backend option for Agent systems, and Agent R&D has evolved from prompt engineering → context engineering (as shown in the figure below).
1. Agent Development Philosophy
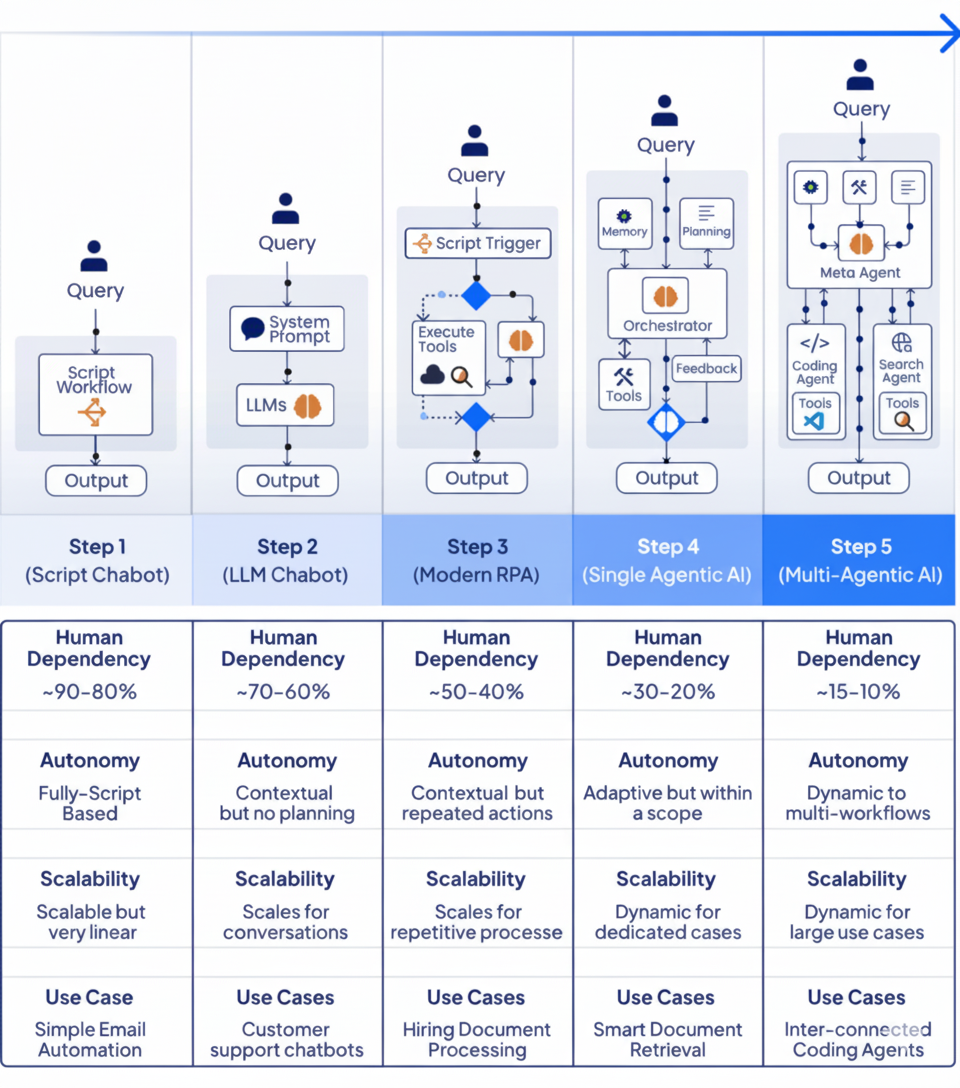
Agents are not a panacea. The key is to choose the appropriate automation stage for tasks of different complexities. I believe we can see from the five evolutionary stages of Agents:
- Complex ≠ Better
- Don't blindly chase the "strongest Agent architecture"; suitability is key.
- Using a complex system for a simple task only increases cost and risk.
- The Real Challenge is "Human"
- Many failed cases stem from the designer choosing the wrong architecture or lacking phased thinking.
- The model and workflow are not the problem; the human is.
- The Importance of Design Thinking
- First, assess the task's complexity and automation potential.
- Then, decide the required level of intelligence (Script → LLM → RPA → Agent → Multi-Agent).
- Finally, match the appropriate tool, don't use a "one-size-fits-all" approach.
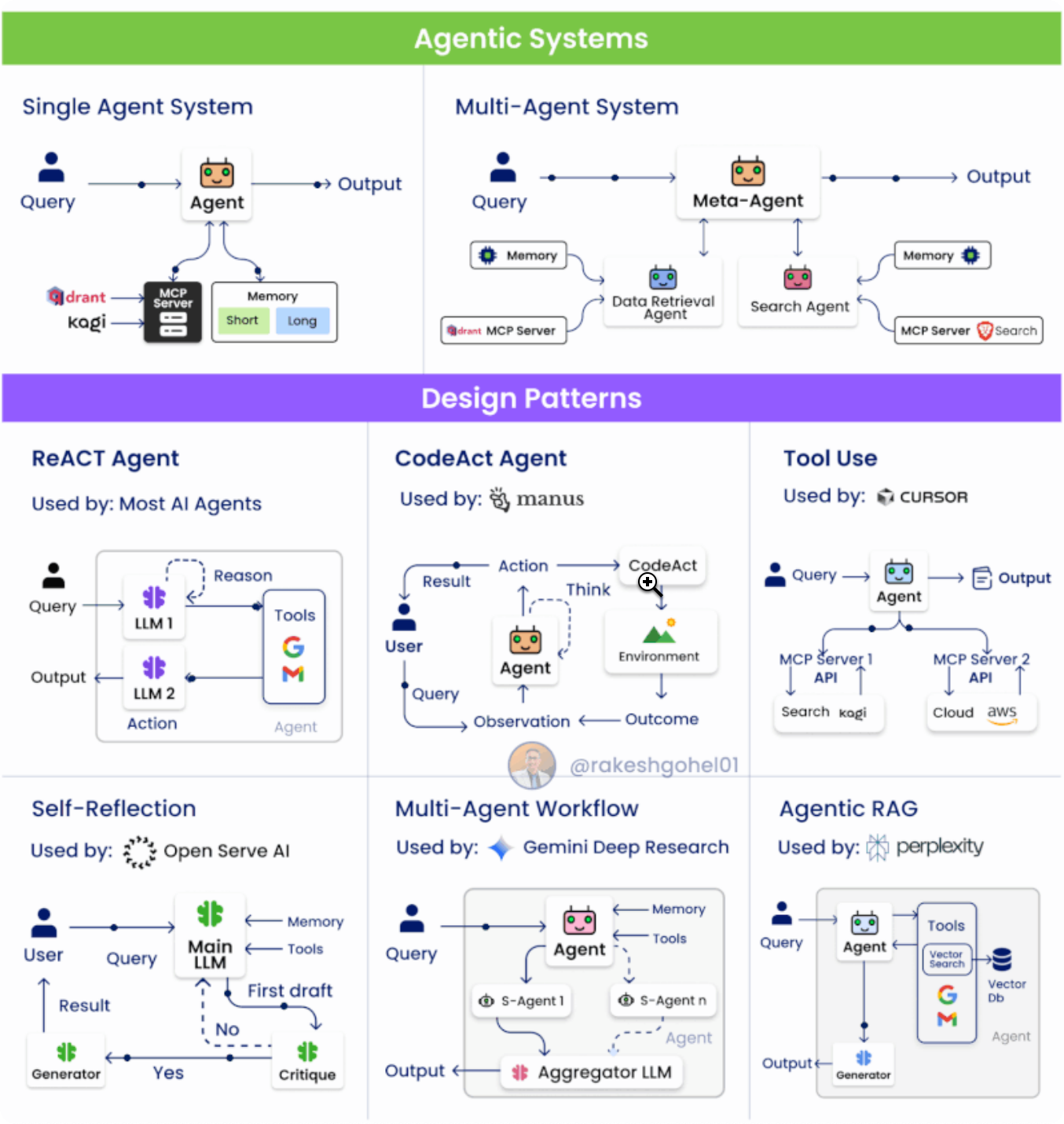
2. Agent Design Patterns
- 1️⃣ ReAct Pattern (Reasoning + Acting)
- Structure: Divided into Reasoning and Acting phases.
- Mechanism:
- LLM1: Understands context, plans which tool/API to call.
- LLM2: Executes the action, returns the result.
- Pros: Decouples reasoning and action, clear structure.
- Applications: Q&A, multi-step tasks, tool-driven workflows.
- 2️⃣ CodeAct Pattern
- Flow:
- User → Plan: User gives a task, Agent plans the steps.
- Code → Feedback: Generates and executes code, corrects based on results.
- Feature: Introduces a feedback loop (code execution → result → reflection).
- Applications: Verifiable tasks (data processing, analysis, API calls).
- Represents: AI acting through code.
- Flow:
- 3️⃣ Tool Use Pattern
- Core Concept: Upgrades from single API calls to a unified protocol (MCP) for managing tools.
- Features:
- Tool abstraction and standardization.
- Supports multi-modal, multi-source tool access.
- Significance: Greatly improves the Agent's ecosystem compatibility and extensibility.
- 4️⃣ Self-Reflection / Reflexion Pattern
- Architecture:
- Main LLM: Executes the main task.
- Critique LLM(s): Criticizes/reviews the main model's output.
- Generator: Combines feedback to produce the final answer.
- Advantages:
- Introduces a "self-reflection" mechanism.
- Reduces hallucination rates, improves logic and quality consistency.
- Applications: Scientific research, content generation, high-risk decision scenarios.
- Architecture:
- 5️⃣ Multi-Agent Workflow
- Structure:
- Core Agent: Coordinates task allocation.
- Sub-Agents: Each focuses on a specific function/domain.
- Aggregator: Integrates outputs from sub-agents.
- Features:
- Simulates real team collaboration.
- Supports complex, cross-functional tasks.
- Applications: Enterprise-level systems, automated programming, cross-departmental processes.
- Structure:
- 6️⃣ Agentic RAG Pattern
- Flow:
- Agent uses tools to perform Web / Vector retrieval.
- Main Agent fuses retrieval results with its own reasoning.
- Generator produces the final answer.
- Features:
- Dynamic retrieval + reasoning.
- Agent can autonomously decide "if, when, and how" to retrieve.
- Significance: From static RAG → intelligent, decision-making Agentic RAG.
- Flow:
3. Latest Agent Progress
Finally, I want to summarize the latest engineering progress in Agents and the most recent engineering experiences worth learning from:
- Agentic Design Pattern (by Google's Antonio Gulli), PDF
- Build agentic AI systems (by Andrew Ng), Course
Below are some takeaways from Agent development. Those interested can look up how various Agent players are planning their strategies.

Perhaps future frameworks will absorb even more of this complexity. But the role of the engineer will not disappear. What we must do is to re-establish order in the places where complexity has been hidden—to make intelligence not just callable, but tamable.