本文最后更新于 262 天前,其中的信息可能已经有所发展或是发生改变。
上篇已经模型架构的代码都学习了,本章学习一下如何训练。
文章中的很多模块功能都是定义一个类,首先是batch和mask,该类主要是为训练过程准备输入数据和掩码(mask)的
class Batch:
"""Object for holding a batch of data with mask during training.""" def __init__(self, src, tgt=None, pad=2): # 2 = <blank>
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if tgt is not None:
self.tgt = tgt[:, :-1]
self.tgt_y = tgt[:, 1:]
self.tgt_mask = self.make_std_mask(self.tgt, pad)
self.ntokens = (self.tgt_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
)
return tgt_mask
首先是init函数的参数:def __init__(self, src, tgt=None, pad=2): # 2 = <blank>
src指source data的索引序列,tgt指target data的索引序列,pad指<PAD>填充字符的索引,默认是2
self.src_mask = (src != pad).unsqueeze(-2)
src的维度为(batch_size,seq_len),(src != pad)会得到一个布尔张量,标记哪些位置不是 <blank>。即将填充字符的位置标记为FALSE。之后unsqueeze(-2)会在倒数第二维插入一维方便后边与注意力矩阵相乘。(batch_size,seq_len)——>(batch_size,1,seq_len)
self.tgt = tgt[:, :-1]
self.tgt_y = tgt[:, 1:]
self.tgt = tgt[:, :-1]是去掉最后一个token,作为解码器的输入,self.tgt_y = tgt[:, 1:]是去掉第一个token,作为解码器的输出标签。
看到这里可能有点懵。为什么要这么训练呢,解码器明明输出的都是target data,为什么还要拆成输入和输出。 这个就要从transformer架构推理过程开始说起。
transformer的推理过程与传统基于RNN的enocder-decodedr架构基本很相似,在encoder生成输出后,decoder输入第一个词<BOS>之后生成第二个词,然后再将前两个词喂到transformer中,之后生成第三个词,以此类推,这个过程也是串行的,叫做Decoder的自回归。所以为了让训练和推理保持一致(都只用历史信息预测下一个 token)。就会将target data拆成输入和输出。这个输出的作用就是用来监督输入的。
举个例子:假设tgt = [<bos>, I, like, apples, <eos>]。
self.tgt = [<sos>, I, like, apples] # 输入给 Decoder
self.tgt_y = [I, like, apples, <eos>] # 训练时的标签
训练时,解码器会学习:
输入 <bos> → 预测 I
输入 <bos>, I → 预测 like
输入 <bos>, I, like → 预测 apples
输入 <bos>, I, like, apples → 预测 <eos>
但是transfomer训练过程中是并行的,并不是一步一步串行,训练时会将self.tgt一并输入到decoder中,之后利用掩码机制,保证每个位置只能看到当前位置之前的token
<sos> 只能看到 [<sos>]
I 只能看到 [<sos>, I]
like 只能看到 [<sos>, I, like]
apples 只能看到 [<sos>, I, like, apples]
而self.tgt_y就是解码器的target,当输入self.tgt之后,会输出一个模型输出一个 大小为(batch_size, seq_len, vocab_size)的logits
前面说了训练时的目标是让模型学会:
输入 <bos> → 预测 I
输入 <bos>, I → 预测 like
输入 <bos>, I, like → 预测 apples
输入 <bos>, I, like, apples → 预测 <eos>
所以我们利用self.tgt_y和输出的logits计算loss。然后反向传播更新梯度。
然后接下来是
self.tgt_mask = self.make_std_mask(self.tgt, pad)def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
)
return tgt_mask
可以看到tgt的mask不仅有对<PAD>标签的屏蔽,还有对于未来word的屏蔽,具体就是生成一个上三角为False的矩阵,这个在上一篇中也说过了。
class TrainState:
"""Track number of steps, examples, and tokens processed"""
step: int = 0 # Steps in the current epoch
accum_step: int = 0 # Number of gradient accumulation steps
samples: int = 0 # total # of examples used
tokens: int = 0 # total # of tokens processeddef run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
"""Train a single epoch"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, batch in enumerate(data_iter):
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += batch.src.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_state
在看run_epoch之前,我们需要看看他用到的参数
def run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
data_iter肯定就是数据集,作者类似于我们之前训练用到的dataloader,因为后边也是这么调用了:
for i, batch in enumerate(data_iter)
model就是我们用到的model。
然后是loss_compute,全文中都是用到的都是SimpleLossCompute这个类。
Loss Computation
class SimpleLossCompute:
"A simple loss compute and train function." def __init__(self, generator, criterion):
self.generator = generator
self.criterion = criterion
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
)
/ norm
)
return sloss.data * norm, sloss
前面我们model输出的是一个大小为(batch_size, seq_len, d_model]的隐藏状态,这里的generator就是前一章介绍的generator类,把隐藏状态投影到词表空间用来对每个词进行打分。而criterion就是损失函数了,论文中用的是nn.KLDivLoss,但并不是直接将他输入进来的,而是先进行了平滑处理,用到的类是:LabelSmoothing。这个之后再说。
总之会返回一个损失函数,需要的输入是预测值和实际值。
x.contiguous().view(-1, x.size(-1)),
y.contiguous().view(-1)
这一步操作是将他们铺平对齐,
x,y分别是out, batch.tgt_y,out是模型的输出,维度是(batche_size,seq_len,vocab_size),batch.tgt_y就是上文中的tgt_y,维度为:(batche_size,seq_len)。然后.contiguous()保证内存连续,因为.view()需要内存连续。所以平铺之后x的维度为:(batche_size*seq_len,vocab_size),y的维度为:(batche_size*seq_len,)
之后还要除以一个norm,而norm是batch.ntokens,就是token的数量,除以 norm 就是把损失归一化,平均每个 token 的损失。否则不同seq的token数量不同,会导致损失不可比。
最后返回每个seq的整体损失以及平均损失sloss
然后接下来的参数是optimizer,就是优化器,在正式训练中,作者使用的是torch.optim.Adam。
scheduler
然后是scheduler是我之前没见过的,这玩意是用来自动调节学习率的,作者使用的是:from torch.optim.lr_scheduler import LambdaLR,LambdaLR通过自定义函数来指定每一步或每个 epoch 的学习率变化规律。在文章中是这么用的:
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
这一步的作用就是
LambdaLR 会在每个 scheduler.step() 时,把当前的 step 数(从 1 开始) 传进这个 lr_lambda 函数。rate() 函数根据 step、d_model、factor、warmup 算出一个 学习率缩放因子(相对 base_lr 的比例)。
然后 LambdaLR 会把它乘上 optimizer 的 base_lr,得到 当前 step 应该用的学习率。
def rate(step, model_size, factor, warmup):
"""
we have to default the step to 1 for LambdaLR function
to avoid zero raising to negative power.
"""
if step == 0:
step = 1
return factor * (
model_size ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
)
这是 Transformer 原论文的学习率策略:warm-up + 衰减,Warm-up就是预热阶段,训练初期权重还没初始化好如果一开始学习率太大,梯度可能会很大导致参数更新过猛进而导致训练不稳定甚至发散,所以这个阶段就是学习率逐渐上升,衰减阶段就是训练到一定阶段,模型已经学到比较合理的表示,如果继续保持大学习率,参数可能在最优附近来回震荡,收敛慢。这时候就需要学习率随着训练步数逐渐减小。
如图所示:
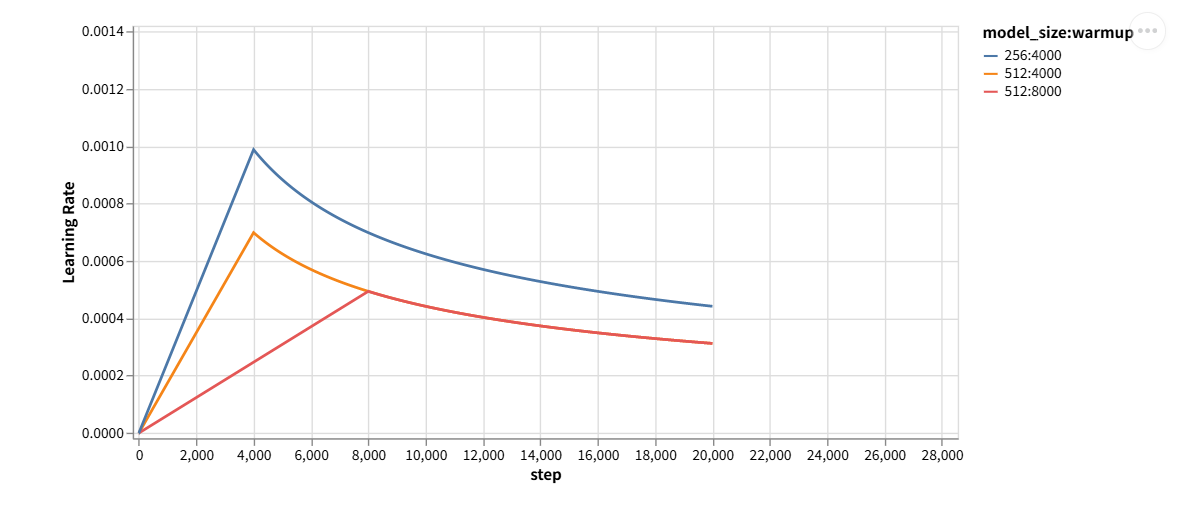
rate函数。该函数实际上就是:的作用是缩放学习率,因为模型越大,就需要更小的学习率来保持稳定。
前期step<warmup时, $step\cdot warmup^{-1.5}
然后代码里多了一个factor,它一个常数缩放因子,用来整体放大或缩小学习率。文章中实际训练时使用的是1.
梯度累积 (gradient accumulation)
倒数第二个参数:accum_iter=1,
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += batch.src.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
正常训练中,每一个batch,我们都会反向传播,更新梯度。但是当batch太大时,显存一次放不下,这个时候就得把一个大 batch 拆成多个小 batch 来累积。accum_iter就表示多少个小 batch 累积一次,再更新参数。但是在代码中,学习率是会随着step每次更新的。
后边的代码就好理解一些,直接写一下注释。
total_loss += loss#累加整个 epoch 的损失
total_tokens += batch.ntokens#计算token数
tokens += batch.ntokens#累加用于局部统计
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]#获取当前学习率
elapsed = time.time() - start#计算该batch训练经过的时间
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0#清空局部统计的tokens
del loss
del loss_node
return total_loss / total_tokens, train_state#返回 epoch 平均 loss(按 token 平均)和 训练状态对象(包含 step、samples、tokens 等累计信息)。首先理解为什么要标签平滑?
在标准分类任务中,目标标签是 one-hot 向量,例如:
target = 2, vocab_size=5
one-hot: [0, 0, 1, 0, 0]
问题:
模型在训练时会过度自信(把正确类别的概率逼近 1,其余类别逼近 0),这样很容易也容易过拟合。
Label Smoothing 的做法是:
不把正确类别的概率设为 1,而是 1 - smoothing,其余类别分配剩余概率 smoothing / (vocab_size - 1)。
例如:smoothing=0.1,vocab_size=5
[0.025, 0.025, 0.9, 0.025, 0.025]
文章中是怎么实现的呢?首先是构造函数。
class LabelSmoothing(nn.Module):
"Implement label smoothing." def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
padding_idx就是pad标签的索引,不参与平滑计算。self.confidence 表示正确类别的值,self.criterion = nn.KLDivLoss(reduction="sum")就是采用的损失函数。size就是vocab_size
这个类实际上实现的是,平滑+计算损失。
接着是forwar函数
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach())
x是模型未经过softmax输出的但已经铺平的logits,维度为(batch_size*seq_len,vocab_size)
target是真实标签的index,维度为(batch_size*seq_len,)
true_dist.fill_(self.smoothing / (self.size - 2))这里之所以-2不是-1,是因为排除了pad标签。
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)

接着:
true_dist[:, self.padding_idx] = 0#任何 padding token 的概率设为 0
mask = torch.nonzero(target.data == self.padding_idx)#找到padding_idx的位置
if mask.dim() > 0:#如果有padding_idx
true_dist.index_fill_(0, mask.squeeze(), 0.0)##如果 target 是 padding,也把整行设为 0 mask.squeeze() →表示得到要操作的行索引
接着
self.true_dist = true_dist #平滑后的target
return self.criterion(x, true_dist.clone().detach())#计算损失
#clone().detach() 新的数据副本 + 与原计算图断开,不让梯度流回原数据
self.criterion(x, true_dist.clone().detach())这一步的意义:
true_dist = x.data.clone() # 假设去掉 clone()/detach()
如果不使用 .detach(),计算图会把 true_dist看作依赖于 x即 KLDivLoss会认为目标分布 true_dist 也是模型输出的一部分
接着是一个简单的copy-task,文章中最后一章是针对真正的任务的,过于复杂,我不打算看那个了。就把这个简单的的任务来总结一下。
We can begin by trying out a simple copy-task. Given a random set of input symbols from a small vocabulary, the goal is to generate back those same symbols.
任务很简单,输入符号,输出就是与该符号相同的符号。
def data_gen(V, batch_size, nbatches):
"Generate random data for a src-tgt copy task."
for i in range(nbatches):
data = torch.randint(1, V, size=(batch_size, 10))#随机生成整数,范围 [1, V-1]
data[:, 0] = 1 #每个seq的起始位置设置为1,表示<BOS>
src = data.requires_grad_(False).clone().detach()
tgt = data.requires_grad_(False).clone().detach() yield Batch(src, tgt, 0)
这里就是准备数据,因为是copy task,所以输入和输出都一样requires_grad_(False).clone().detach()是防御型写法了,这三个操作都可以防止数据污染计算图,也就是说这些数据不会随着反向传播而梯度更新,
data.requires_grad_(False)#明确告诉 PyTorch 这个张量不需要梯度
data.detach()#生成一个 新的张量,脱离计算图
data.clone()#生成 tensor 的 副本
yield 的作用是 一次返回一个值,但保留函数的状态,下次可以从上次停下的地方继续执行。
在后边的代码中:
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
...
总体流程如下:
data_gen(V, batch_size, 20) 生成器,每次产生一个 batch
for i, batch in enumerate(data_iter): 在 run_epoch 内部迭代生成器
model.forward(batch.src, batch.tgt, ...) → 前向传播
loss_compute(...) → 计算 loss
loss.backward() → 反向传播
optimizer.step()→ 更新参数
重复 20 个 batch(nbatches=20)
epoch 完成 → 开始下一个 epoch
作者将训练和预测都写到了一个example_simple_model()函数中。
这个函数主要有三个部分分别是,model.train()模式下的训练,model.eval()模型验证。最后是模型推理:用一个实际的例子来让用户验证。
首先是损失函数、模型、以及优化器的准备
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2) optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
训练集的词表和验证集的词表都是1到V-1,加上<BOS>一共V个。下边的优化器以及学习率优化器都在前面说过了。
接下来是训练
batch_size = 80
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train",
)
这里实际上是在每个batch上又切分了一次,
batch_size是80,那么在run_epoch中每次就跑80条数据,然后data_gen()中第三个参数nbatch是20,意思是会给run_epoch20次数据,每次给80,20次给完,这个epoch才结束,在本例子中,epoch概念被弱化了,实际训练中,遍历完整个数据集,才叫一次epoch,但实际上这个例子中每个epoch的数据都不一样。
紧接着是验证
model.eval()
run_epoch(
data_gen(V, batch_size, 5),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
这里[0]的意义是:run_epoch返回的数据实际上是return total_loss / total_tokens, train_state,取[0]表示取出平均loss.
但是这里没有变量接收这个返回值,写[0]只是为了 取出 total_loss / total_tokens,但因为没有赋值给任何变量,这个值实际上被计算出来后就丢弃了.这段代码在验证阶段只是为了 跑一遍 run_epoch 让模型前向计算并打印日志,但 不保存或使用返回的 loss。这里为了优化,可以加一个值来接收它并打印。
这里的DummyOptimizer和DummyScheduler
class DummyOptimizer(torch.optim.Optimizer):
def __init__(self):
self.param_groups = [{"lr": 0}]
None def step(self):
None
def zero_grad(self, set_to_none=False):
None
class DummyScheduler:
def step(self):
None
因为验证的时候也是用的run_epoch()函数。但是验证的死后是不需要更新参数的,只需要foward+loss,所以需要创建两个类将这两个优化器pass掉。
最后是用一个实际的例子来让用户验证
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ysmodel.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len)
print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))
所谓贪婪推理,就是上一篇中的run_tests()即:将source_data输入到encoder中得到隐藏向量,之后再过一遍decoder,decoder的第一个输入为<BOS>在generator中每次取概率最大的那个作为输出,之后再将已经输出的作为输入重新输入到解码器中。
我在该代码的基础上又将训练函数改了改。
def example_simple_model(save_path="simple_model.pt", num_epochs=30, batch_size=80):
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2).to(device) optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
train_losses = []
for epoch in range(num_epochs):
# ------------------
# 训练
# ------------------
model.train()
train_loss, _ = run_epoch(
data_gen(V, batch_size, 20, device=device),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train",
)
train_losses.append(train_loss.item())# tensor->numpy
# ------------------
# 验证
# ------------------
model.eval()
val_loss=run_epoch(
data_gen(V, batch_size, 5, device=device),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
print(f"Epoch {epoch+1}/{num_epochs} | Train Loss: {train_loss:.4f}")
print(f"Validation loss: {val_loss}")
# ------------------
# 保存模型
# ------------------
torch.save(model.state_dict(), save_path)
print(f"Model saved to {save_path}")
# ------------------
# 可视化训练 loss
# ------------------
plt.figure(figsize=(8, 5))
plt.plot(range(1, num_epochs+1), train_losses, marker='o')
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid(True)
plt.show()
def load_and_decode(model_class, save_path, src_seq, device='cpu', max_len=None, start_symbol=0):
"""
加载已保存的模型,并对输入序列进行贪婪解码
参数:
model_class: make_model 函数或模型类(需要能实例化模型)
save_path: 已保存模型的路径
src_seq: 输入序列 (list 或 tensor)
device: 'cpu' 或 'cuda'
max_len: 解码最大长度,如果 None 则取 src_seq 长度
start_symbol: 解码起始符号
返回:
decoded tensor
"""
# 假设模型的词表大小与训练时相同,这里示例 V=11, N=2 层
V = 11
model = model_class(V, V, N=2).to(device)
# 加载保存的模型参数
model.load_state_dict(torch.load(save_path, map_location=device))
model.eval()
# 构建输入 tensor
if not isinstance(src_seq, torch.Tensor):
src = torch.LongTensor([src_seq]).to(device)
else:
src = src_seq.to(device)
if max_len is None:
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len).to(device)
# 贪婪解码
decoded = greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=start_symbol)
return decodedif __name__ == "__main__":
# example_simple_model()
decoded = load_and_decode(
model_class=make_model,
save_path="simple_model.pt",
src_seq=[0, 1, 2, 4, 6,3,9, 7, 8, 9],
device=device,
start_symbol=0
)
print("Greedy decode result:", decoded)
实验结果拟合的挺好的。
Epoch Step: 1 | Accumulation Step: 2 | Loss: 3.22 | Tokens / Sec: 847.3 | Learning Rate: 5.5e-06
Epoch 1/30 | Train Loss: 2.6971
Validation loss: 2.0443084239959717
Epoch Step: 1 | Accumulation Step: 2 | Loss: 2.16 | Tokens / Sec: 22811.5 | Learning Rate: 6.1e-05
Epoch 2/30 | Train Loss: 1.9578
Validation loss: 1.6869535446166992
Epoch Step: 1 | Accumulation Step: 2 | Loss: 1.77 | Tokens / Sec: 21982.6 | Learning Rate: 1.2e-04
Epoch 3/30 | Train Loss: 1.6649
Validation loss: 1.3588157892227173
Epoch Step: 1 | Accumulation Step: 2 | Loss: 1.48 | Tokens / Sec: 19959.1 | Learning Rate: 1.7e-04
Epoch 4/30 | Train Loss: 1.2859
Validation loss: 0.8525732159614563
Epoch Step: 1 | Accumulation Step: 2 | Loss: 1.06 | Tokens / Sec: 21296.4 | Learning Rate: 2.3e-04
Epoch 5/30 | Train Loss: 0.8551
Validation loss: 0.45536568760871887
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.67 | Tokens / Sec: 21772.1 | Learning Rate: 2.8e-04
Epoch 6/30 | Train Loss: 0.5130
Validation loss: 0.22989791631698608
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.40 | Tokens / Sec: 22787.6 | Learning Rate: 3.4e-04
Epoch 7/30 | Train Loss: 0.3172
Validation loss: 0.07816777378320694
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.19 | Tokens / Sec: 22923.9 | Learning Rate: 3.9e-04
Epoch 8/30 | Train Loss: 0.1793
Validation loss: 0.08288797736167908
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.19 | Tokens / Sec: 22122.3 | Learning Rate: 4.5e-04
Epoch 9/30 | Train Loss: 0.1564
Validation loss: 0.05152091011404991
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.14 | Tokens / Sec: 22887.8 | Learning Rate: 5.0e-04
Epoch 10/30 | Train Loss: 0.1194
Validation loss: 0.05703188478946686
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.19 | Tokens / Sec: 22788.5 | Learning Rate: 5.6e-04
Epoch 11/30 | Train Loss: 0.1584
Validation loss: 0.0343133844435215
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.07 | Tokens / Sec: 23583.3 | Learning Rate: 6.1e-04
Epoch 12/30 | Train Loss: 0.1514
Validation loss: 0.06073753535747528
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.11 | Tokens / Sec: 21671.9 | Learning Rate: 6.7e-04
Epoch 13/30 | Train Loss: 0.1197
Validation loss: 0.045600730925798416
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.16 | Tokens / Sec: 21481.4 | Learning Rate: 7.2e-04
Epoch 14/30 | Train Loss: 0.1295
Validation loss: 0.17674195766448975
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.17 | Tokens / Sec: 21388.8 | Learning Rate: 7.8e-04
Epoch 15/30 | Train Loss: 0.1488
Validation loss: 0.03742923587560654
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.11 | Tokens / Sec: 21344.6 | Learning Rate: 8.3e-04
Epoch 16/30 | Train Loss: 0.1201
Validation loss: 0.026088543236255646
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.10 | Tokens / Sec: 20720.5 | Learning Rate: 8.9e-04
Epoch 17/30 | Train Loss: 0.1083
Validation loss: 0.021275514736771584
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.09 | Tokens / Sec: 21913.7 | Learning Rate: 9.4e-04
Epoch 18/30 | Train Loss: 0.1803
Validation loss: 0.0266287662088871
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.17 | Tokens / Sec: 22380.0 | Learning Rate: 1.0e-03
Epoch 19/30 | Train Loss: 0.1178
Validation loss: 0.024264585226774216
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.06 | Tokens / Sec: 22132.1 | Learning Rate: 1.1e-03
Epoch 20/30 | Train Loss: 0.1084
Validation loss: 0.07377628237009048
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.15 | Tokens / Sec: 22863.8 | Learning Rate: 1.1e-03
Epoch 21/30 | Train Loss: 0.1121
Validation loss: 0.020853251218795776
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.08 | Tokens / Sec: 22698.7 | Learning Rate: 1.1e-03
Epoch 22/30 | Train Loss: 0.0907
Validation loss: 0.025032907724380493
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.12 | Tokens / Sec: 22180.0 | Learning Rate: 1.1e-03
Epoch 23/30 | Train Loss: 0.0939
Validation loss: 0.0221018735319376
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.11 | Tokens / Sec: 19952.6 | Learning Rate: 1.0e-03
Epoch 24/30 | Train Loss: 0.1158
Validation loss: 0.039853885769844055
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.15 | Tokens / Sec: 20710.1 | Learning Rate: 1.0e-03
Epoch 25/30 | Train Loss: 0.1145
Validation loss: 0.024357985705137253
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.05 | Tokens / Sec: 21006.2 | Learning Rate: 9.9e-04
Epoch 26/30 | Train Loss: 0.0907
Validation loss: 0.010511251166462898
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.06 | Tokens / Sec: 21670.6 | Learning Rate: 9.7e-04
Epoch 27/30 | Train Loss: 0.0702
Validation loss: 0.017508547753095627
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.05 | Tokens / Sec: 20740.0 | Learning Rate: 9.5e-04
Epoch 28/30 | Train Loss: 0.0767
Validation loss: 0.030155766755342484
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.05 | Tokens / Sec: 21005.5 | Learning Rate: 9.3e-04
Epoch 29/30 | Train Loss: 0.0953
Validation loss: 0.033265385776758194
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.11 | Tokens / Sec: 20726.1 | Learning Rate: 9.2e-04
Epoch 30/30 | Train Loss: 0.0772
Validation loss: 0.02369164302945137
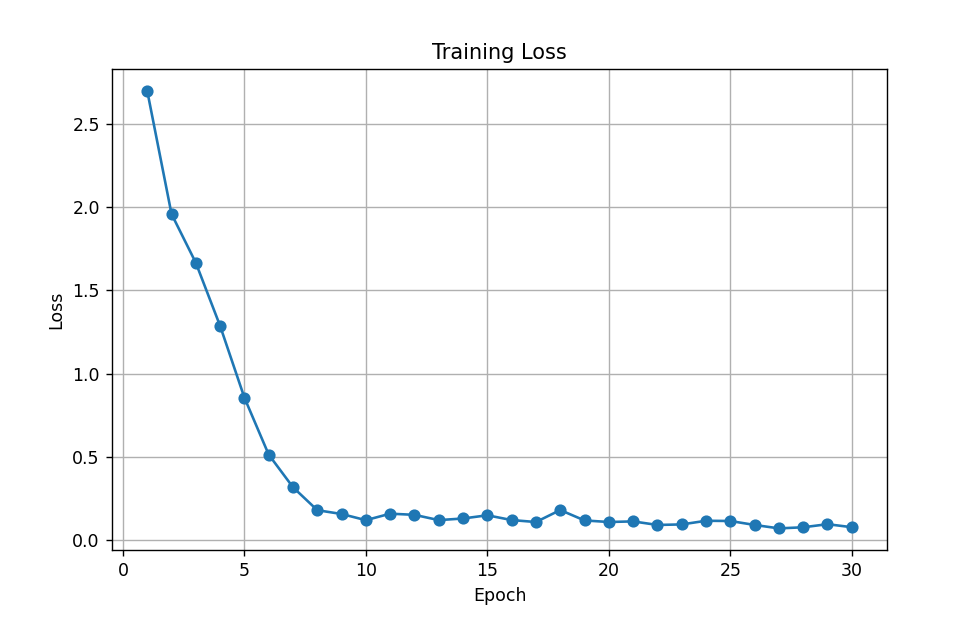
经过我的多轮测试,它确实可以实现一个copy功能:
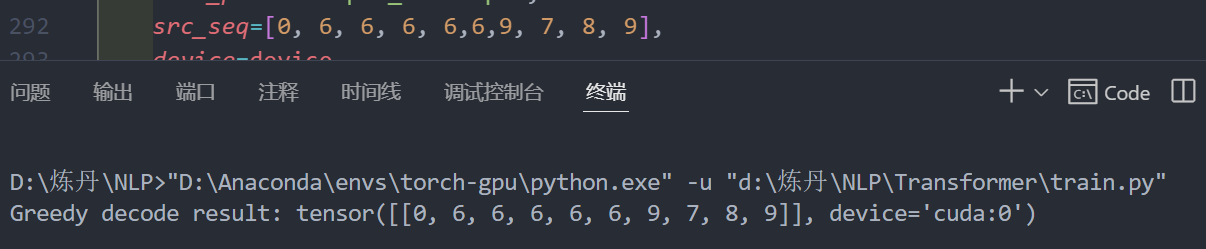
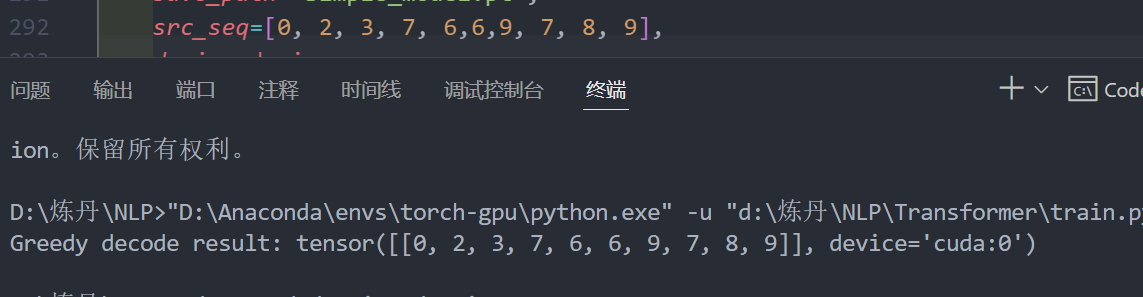
实际上后边还有一章:A Real World Example
Now we consider a real-world example using the Multi30k German-English Translation task. This task is much smaller than the WMT task considered in the paper, but it illustrates the whole system. We also show how to use multi-gpu processing to make it really fast.
完成了一个真正的机器翻译任务。
但我不打算再看了(绝对不是因为我懒)。
一个原因是作者的代码太...优雅了,和写项目一样,层层封装,一个函数封一个函数,是在看的难受。然后就是我现在更想去完成一下导师留的那两个任务,不想在这里掰扯了。。。
最后,作者的代码都能跑,我都跑过了,代码就放到下边吧
https://github.com/Longlong418/Partial-Integration-of-The-Annotated-Transformer-Code
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。