本文最后更新于 105 天前,其中的信息可能已经有所发展或是发生改变。
前言
请打开日间模式进行阅读
本来是想学习RoPE(旋转位置编码),所以回去从头从最开始的三角函数式位置编码开始看,发现自己当时学的还是浅了。在此总结一下。
注:本文涵盖不了所有位置编码,只挑主流的去学习。具体就是由绝对位置编码到相对位置编码再到RoPE
由《Attention is All You Need》提出
定义:
首先这种定义保证了每个位置都有唯一的编码
其次,原文中提到:
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset , can be represented as a linear function of .
can be represented as a linear function of
重点就在这句话。这说明不同位置的编码之间存在可计算的线性关系,这样就可以使模型学到不同token之间的位置关系
那怎么就有线性关系了呢?
推导如下:
对于
为了方便推导,我们首先令
则:
所以我们将相同的奇偶对打包成一块:
假设为偶数
则
接下来我们只需要证明和有线性关系,那么即可外推出和有线性关系。
这里的就表示位置距离个位置的token
因为
根据三角恒等式(高中学的)
得到:
然后将和提出来,得到:
即:
而这里的就是线代中的旋转矩阵,这个旋转矩阵在后边旋转位置编码中也会用到,这里推导出的旋转矩阵的作用是将与他相乘的向量顺时针旋转度
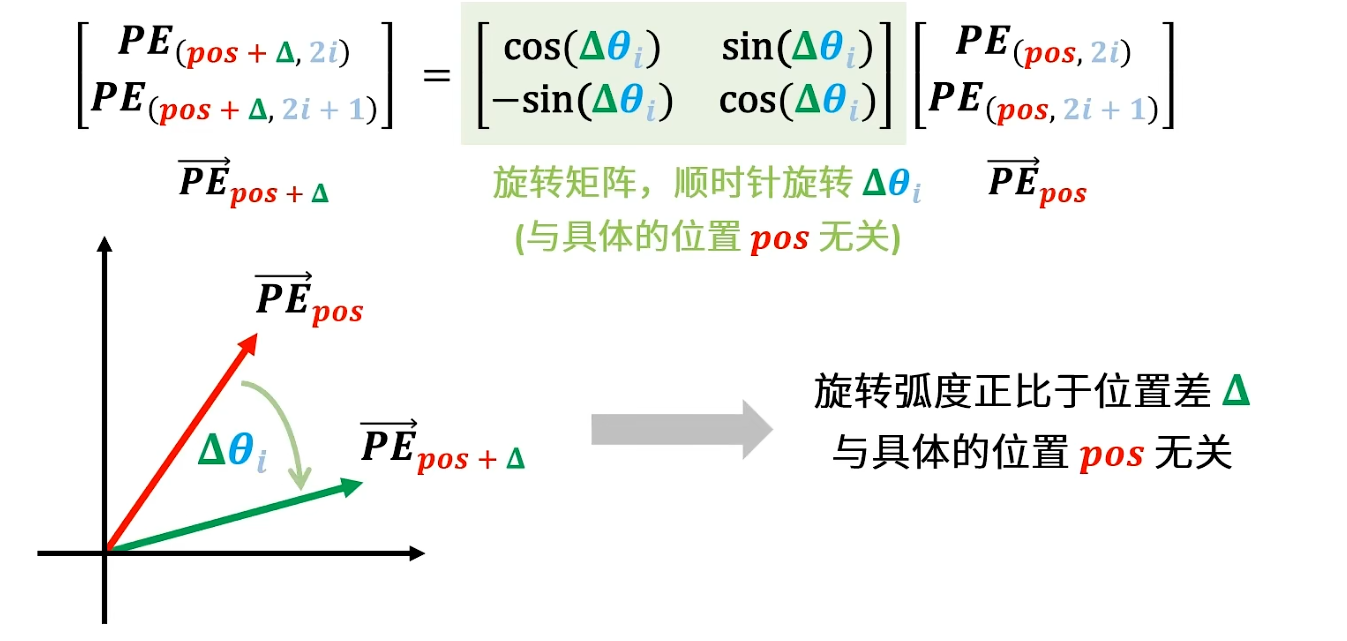
此时已经证出:和有线性关系,而扩展到和
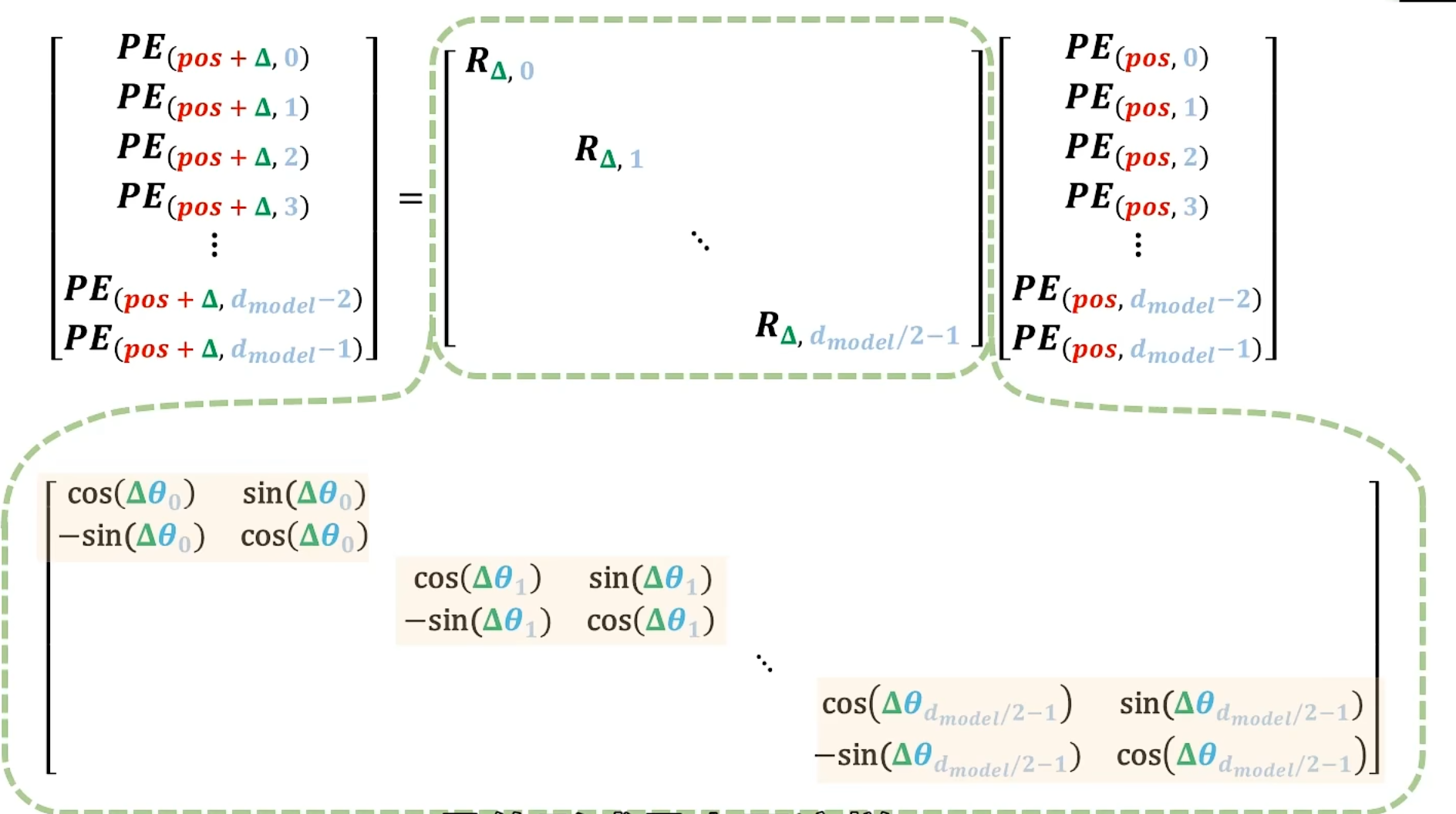
把所有的放在对角线上(块对角):
即可得到:
即原文的:
can be represented as a linear function of
补一张图会比较清晰一些:
在Attention过程中是如何计算位置信息的?
对于第个token的最终编码为:,其中和分别代编wordembedding和positional encoding。
之后在计算注意力的时候:
注意力分数计算:
展开得到:
这四项如果说强行解释一下他们在算什么,可以这么理解:
| 项 | 含义 |
|---|---|
| 输入-输入 | 语义相关性 |
| 输入-位置 | 内容对位置的依赖 |
| 位置-输入 | 位置对内容的影响 |
| 位置-位置 | 纯位置关系 |
但我们更想让模型做的是从位置编码里学到纯位置关系。那么就是要依靠第四项。
这里的第四项是依赖 i 和 j 的绝对编号。
Sinusoidal位置编码被归为绝对位编码,绝对位置编码的绝对体现在完整建模每个输入的位置信息,之后将词向量和位置编码直接相加,之后在计算注意力分数的时候,所得到的位置关系是依赖 i 和 j 的绝对编号来计算两个token的相对位置信息。除了三角函数式的绝对位置编码,还有一种就是可学习的绝对位置编码,通过初始化一个大的矩阵,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。
相对位置编码
由上边的推导可以发现,绝对位置编码最终也是在注意力计算中进行两个token之间的相对位置学习,那如果不完整建模每个输入的位置信息,而是直接在计算注意力的地方加入两个token的相对位置信息是不是可行?
相对位置编码就是这么做的,相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与Attention的位置的相对距离,这样的做法更灵活。
Transformer-XL相对位置编码
来源:《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
相对位置编码的核心思想是将依赖 i 和 j 绝对编号的项改成相对项
对于展开式:
Transformer-XL采取的方式为:将替换为相对位置向量,而两个替换为两个可训练的向量
得到:
论文原文中提到:
Note that is a sinusoid encoding matrix (Vaswani et al.,2017) without learnable parameters
所以即为
注意第二项和第四项:,由于和的编码方案不同,所以不一定在同意子空间,所以的参数矩阵不应该和的参数矩阵共享,所以作者又做了一个改动:
即:为相对位置引入一套独立的 key 投影矩阵。
除此之外,作者还做了一个改动就是,将和前面的参数矩阵合并为一起:
这一步主要就是为了使公式更简洁。
最终得到:
可以简记为:
T5位置编码
来源:《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
依旧是在这个上边动手脚:
| 项 | 含义 |
|---|---|
| 输入-输入 | 语义相关性 |
| 输入-位置 | 内容对位置的依赖 |
| 位置-输入 | 位置对内容的影响 |
| 位置-位置 | 纯位置关系 |
T5认为位置信息和语义信息应该是独立的,所以他们也无需进行交互,所以T5将中间两项删掉了。并且将最后一项位置与位置的项换成了一个标量偏置:
其中:
也就是说位置信息不再通过向量交互表达,
而是直接作为 attention 矩阵上的一个 bias。
这里我的理解就是,类似于绝对位置编码提前将位置编码和词向量相加,这里直接将含有相对位置信息的位置偏置加到词向量中,省去了绝对位置编码中提前向量建模以及,通过两个位置的绝对位置来计算相对位置的步骤,这种方式直接将相对位置信息加到词向量上。
不过T5并没有直接使用距离 i−j,而是对i-j进行了一个函数映射,这个函数采用了分桶处理的思想,
先看直接使用距离i−j的后果:如果序列长度是 1024,那么:
随着序列长度的增加,i-j的取值范围也越来越大,这不现实。之前的工作采用的是截断的方法,即:将i-j限定在一定的范围内,如果超出,则取边界
而T5采取的是分桶处理的思想:就是离得比较近的位置,需要分的精细一些,而离得远的,就粗糙一些,小距离逐个分配:大距离按对数尺度压缩。
具体来说就是:当,取,当大于8时,采用对数尺度的压缩,具体如下:
| 距离 | bucket |
|---|---|
| 8~15 | 8 |
| 16~31 | 9 |
| 32~63 | 10 |
| 64~127 | 11 |
| ... | ... |
因为在自然语言中,大多数情况都是:影响力随距离指数衰减,而之前的截断法也是这个想法,只不过那个方法粗暴的将一定阈值以及更远的距离设置为一个值,不如分桶法优雅。
DeBERTa位置编码
来自:《DeBERTa: Decoding-enhanced BERT with Disentangled Attention》
依旧是在这个上边动手脚:
不过DeBERTa和T5截然相反,DeBERTa是保留了第二项、第三项,然后去掉了第五项。(太有意思了),然后将绝对位置换成相对位置
得到:
至于也是用的和上文中提到的截断法。
这意味着,DeBERTa 不再建模“位置与位置之间的直接关系”,而是只建模“内容与位置之间的交互”。
其他相对位置编码
至于其他的相对位置编码,我个人感觉也是大部分在这个式子上改来改去(比如ALiBi)
旋转位置编码(Rotary Position Embedding)
绝对位置编码的缺点是无法将相对信息直接显式的编入位置编码中,而是需要在计算注意力分数的时候,间接的学习相对位置信息。
而旋转位置编码的核心思想就是通过绝对位置编码的方式实现相对位置编码
前面提到,绝对位置编码是需要提前完整建模每个输入的位置信息,在此基础上要满足:在、计算注意力分数时,得到的内积结果还能直接带有相对位置信息(非间接),即满足该式:
为注入绝对位置信息的最终编码
总结一下就是:
虽然我们对 注入的是“绝对位置 m,n”,但最终内积得到的结果是显式的包含“相对位置 m-n”。
此时问题就是如何找到与函数满足以上的等式。
还记的前面提到的三角函数位置编码中的旋转矩阵吗?
为旋转矩阵,表示将顺时针旋转度。
RoPE中使用这个旋转矩阵来作为和,不过RoPE中的旋转矩阵为逆时针旋转(实际上顺时针逆时针都可以),因此我们把旋转矩阵重新写成:
为旋转矩阵,会将与他相乘的向量逆时针旋转度,m表示位置
对于维模型(是偶数):
将这个旋转矩阵与q相乘得到:
同理,
之后,只需要验证和的点积结果是否符合下面的式子即可:
验证过程:
因为:
对于高维情况,由于 是由多个 块对角拼接而成,因此:
所以
又因为:的意义是将向量逆时针旋转一定角度,那么乘以之后再乘以,就可以理解为将该向量逆时针旋转度。即d。这个也是可以推导的:
计算乘积:
左上角:
右上角:
左下角:
右下角:
因此:
同理:对于高维情况,由于 是由多个 块对角拼接而成,因此:
所以:
得到:
满足:
注意事项:
上边推导过程中的和三角函数编码中是一样的:
本质是一种频率衰减函数,用于在RoPE中为不同维度分配不同的旋转频率,从而实现位置信息的多尺度表达和长序列的相对位置建模。
这个公式的核心作用是:让低维部分对应低频(缓慢旋转),高维部分对应高频(快速旋转),使 RoPE 能够在不同尺度上编码相对位移,实现短程与长程依赖的统一建模。
因为是一个对角线矩阵,所以直接用矩阵乘法来实现会很浪费算力。所以RoPE落实在代码上的实现是:
一些问题
以上推导就仅仅是证明了RoPE的可行性,但是作者是如何想到用旋转矩阵的呢?并不是拍脑袋想的,原作者写的博客中提到了推导过程,提到了复数,欧拉公式等。目前本人的数学底子没那么厚(有点看不懂),之后有机会再细细研究。
以下是苏神的求解过程

总结
RoPE的本质在于它通过乘法而非传统的加法来注入位置信息,这使得模型在处理序列时能天然地捕获相对位置关系,同时保持绝对位置的编码能力。(既要绝对位置能力,又要相对位置能力)
这种乘法操作的本质是将词向量与一个依赖于位置的旋转矩阵相乘,从而在高维空间中对向量进行“旋转”。旋转的角度由位置索引和预设的频率参数共同决定,使得不同位置的向量在空间中呈现出不同的方向。避免了加性位置编码在长序列中可能出现的“位置淹没”问题(直接相加,位置信息可能会被语义信息覆盖)
学完这些之后,就引出了更多问题,但现在说不上来,感觉位置编码这块还有很多需要探索的地方
参考资料
苏神博客:
https://spaces.ac.cn/archives/8130
https://spaces.ac.cn/archives/8265
Bilibili:
https://www.bilibili.com/video/BV1xR1RY9ECm/?spm_id_from=333.337.search-card.all.click&vd_source=b59fac4a4032a8df8c5f68b99a0e5f0c