BEVFusion 专注于多传感器融合(即多视图相机和激光雷达),用于多任务 3D 感知(即检测和分割),本文记录相关内容。
多传感器融合对于精确可靠的自动驾驶系统是必不可少的。 最近的方法是基于点级融合:用摄像机特征增强LIDAR点云。 然而,相机到激光雷达的投影会丢弃相机特征的语义密度(semantic density),阻碍了这种方法的有效性,尤其是对于面向语义的任务(如三维场景分割)。
本文利用BEVFusion这一高效通用的多任务多传感器融合框架,打破了这一根深蒂固的惯例。 它在共享鸟瞰(BEV)表示空间中统一了多模态特征,很好地保留了几何和语义信息。 为了实现这一点,我们用优化的BEV池化来分析和解决视图转换中的关键效率瓶颈,将延迟减少了40%以上。BevFusion从根本上来说是与任务无关的,它无缝地支持不同的3D感知任务,几乎没有架构上的变化。
背景:自动驾驶系统配备了多种传感器,提供互补的信号。但是不同传感器的数据表现形式不同。
自动驾驶系统配备了多样的传感器。 例如,Waymo的自动驾驶车辆有29个摄像头、6个雷达和5个激光雷达。 **不同的传感器提供互补的信号:**例如,摄像机捕捉丰富的语义信息,激光雷达提供精确的空间信息,而雷达提供即时的速度估计。 因此,多传感器融合对于准确可靠的感知具有重要意义。**来自不同传感器的数据以根本不同的方式表示:**例如,摄像机在透视图中捕获数据,激光雷达在3D视图中捕获数据。

(a) 对相机:几何损耗 ;
(b) 对激光雷达:语义有损 ;
© : BEVFusion将相机和激光雷达功能统一在一个共享的BEV空间中,而不是将一种模式映射到另一种模式。 它保留了摄像机的语义密度和激光雷达的几何结构。
由于在二维感知方面取得了巨大的成功,自然的想法是将激光雷达点云投影到摄像机上,并用二维CNNS处理RGB-D数据。 然而,这种激光雷达到摄像机的投影引入了严重的几何失真(见图 1a,本来在3D图像中的红色点和蓝色点在2D图像中相邻 ),这使得它对面向几何的任务(如三维物体识别)的有效性降低。
最近的传感器融合方法也是朝着另一个方向发展的。 它们用semantic lables、CNN features、virtual point from 2D image 来增强了激光雷达点云,,然后使用基于激光雷达的探测器来预测三维包围盒。 虽然它们在大规模检测基准上表现出了显著的性能,但这些点级融合方法几乎不能用于面向语义的任务,如BEV地图分割。 这是因为相机到激光雷达的投影在语义上是有损的(见图 1B):对于一个典型的32光束激光雷达扫描仪,只有5%的相机特征将匹配到一个激光雷达点,而所有其他特征都会被丢弃掉。 对于较稀疏的激光雷达(或成像雷达)来说,这种密度差异将变得更加剧烈。
在本文中,我们提出了BEVFusion将多模态特征统一到共享鸟瞰(BEV)表示空间中,用于任务无关的学习(task-agnostic learning)。 我们维护几何结构和语义密度(见图 1c)并自然支持大多数3D感知任务(因为它们的输出空间可以在BEV中自然捕获)。
在将所有特性转换为BEV时,我们确定了视图转换中主要的阻碍效率瓶颈:BEV池化操作 占用模型运行时的80%以上。 然后,我们提出了一个具有预计算和间隔缩减的专用核来消除这一瓶颈,实现了40%以上的加速比。
最后,我们应用全卷积BEV编码器融合统一的BEV特征,并附加一些特定于任务的头来支持不同的目标任务。
BevFusion在Nuscenes基准上设置了新的最先进的性能。 在3D物体检测方面,它在所有解决方案中排名第一。 BEVFusion在BEV地图分割方面有更显著的改进。 在现有的融合方法难以实现的情况下,它的MIOU比纯相机模型高6%,比纯激光雷达模型高13.6%。 BEVFusion是高效的,以1.9倍的低计算量提供了所有这些结果。BevFusion打破了长期以来认为点级融合是多传感器融合的最佳解决方案的观点。 简洁也是它的关键力量。 我们希望这项工作能为未来的传感器融合研究提供一个简单而有力的基线,并启发研究者重新思考通用多任务多传感器融合的设计和范式。
与现有的方法相比,BEVFusion在一个共享的BEV空间中进行传感器融合,对前景和背景、几何和语义信息一视同仁。 BEVFusion是一种通用的多任务多传感器感知框架。
BEVFusion专注于多传感器融合(即多视角摄像机和激光雷达)用于多任务3D感知(即检测和分割)
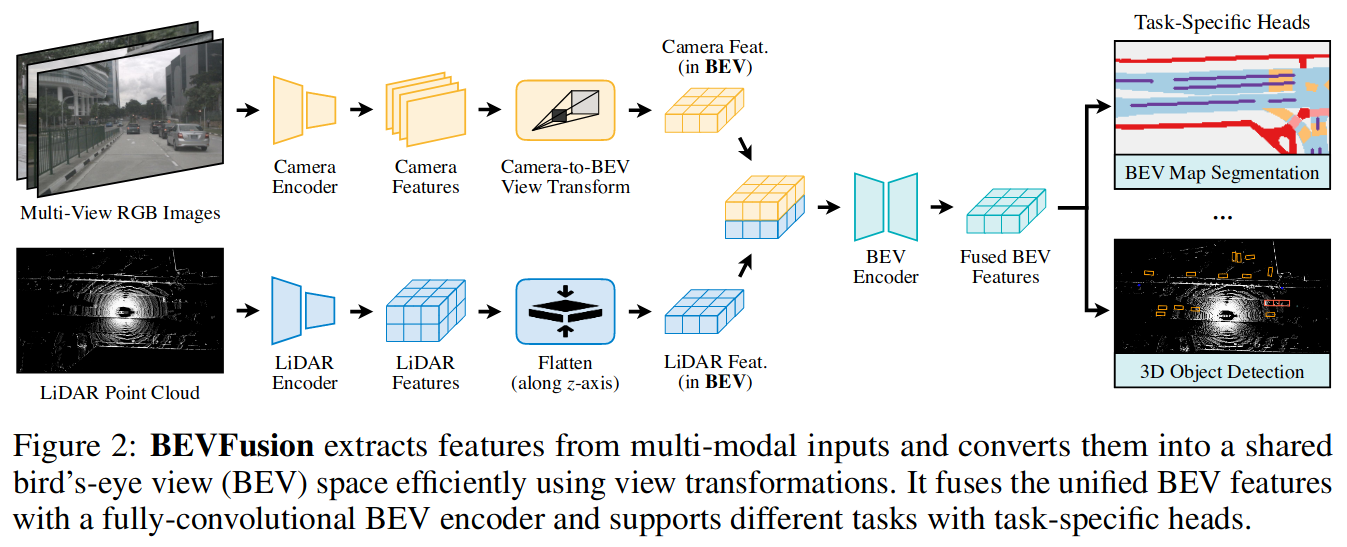
BEVFusion 从多模式中提取特征,并使用视图转换有效的将它们转换成共享鸟瞰图(BEV)空间。它融合了统一的BEV功能和全卷积BEV编码器,并支持不同任务和任务特定的头。
上图是BEVFusion的框架,流程如下:
目标:为不同视图的特征找到一种共享的表达方式。要求这种统一表示不丢失信息,且适用于不同任务。
不同的特征可以存在于不同的视图中。 例如,相机特征在透视图中,而激光雷达/雷达特征通常在3D/鸟瞰视图中。 即使对于相机特征,它们中的每一个都有一个不同的视角(即,前、后、左、右)。 这种观点差异使得特征融合变得困难,因为不同特征张量中的相同元素可能对应于完全不同的空间位置(在这种情况下,原始的元素特征融合将不起作用)。 因此,寻找一种共享的表示方式是至关重要的,而且需要
(1)所有传感器特征都可以很容易地转换成共享的表示方式而不丢失信息
(2)共享的表示方式适合于不同类型的任务。
统一表示的方式:
To Camera
在RGB-D数据的激励下,一种选择是将激光雷达点云投影到相机平面,渲染2.5D稀疏深度。 然而,这种转换在几何上是有损耗的。 深度图上的两个邻居在三维空间中可以相距很远。 这使得相机视图对于聚焦于对象/场景几何形状的任务(如3D对象检测)的有效性降低。
To LiDAR
最先进的传感器融合方法用其相应的相机特征(例如,语义标签、CNN特征或虚拟点)装饰激光雷达点。 然而,这种相机到激光雷达的投影在语义上是有损耗的。 相机和激光雷达功能的密度有很大的不同,导致只有不到5%的相机功能匹配到激光雷达点(对于32通道激光雷达扫描仪)。 放弃相机特征的语义密度严重损害了模型在面向语义任务(如BEV地图分割)上的性能。 类似的缺点也适用于潜在空间中较新的融合方法(例如,对象查询)。
To Bird’s-Eye View
我们采用鸟瞰视图 (BEV) 作为融合的统一表示。 这个视图对几乎所有的感知任务都很友好,因为输出空间也在BEV中。更重要的是,到BEV的转换既保持了几何结构(来自激光雷达特征),又保持了语义密度(来自相机特征)。 一方面,Lidar-to-BEV 投影使稀疏的 Lidar 特征在高度维上变平,从而不会在图形上产生几何畸变;另一方面,Camera-to-BEV 投影将每个摄像机特征像素投射回三维空间中的一条射线(在下一节中详细描述),这可以导致如图所示的密集的BEV特征映射, 保留来自摄像机的全部语义信息。
camera→BEV 的转换是非常重要的,因为与每个摄像机特征像素相关的深度本质上是模糊的。
继 LSS 和 BEVDet,我们显式预测每个像素的离散深度分布。然后,我们将每个特征像素沿着摄像机光线分散成D个离散点,并根据它们对应的深度概率重新确定相关特征。 这生成大小为 $ N\times H\times W\times D$ 的相机特征点云,其中 $N$ 是相机的数量,$ (H,W)$ 是相机特征图大小。 这样的3D特征点云以 $r$(例如,0.4m)的步长沿着 $X、Y$ 轴被量化。 我们使用 BEV pooling 操作来聚合每个 $r\times r$ BEV 网格中的所有特征,并沿着 $Z$ 轴 flatten 特征。
虽然简单,但BEV pooling 出奇地低效和缓慢,在RTX 3090 GPU上需要500ms以上(而我们模型的其余部分只需要100ms左右)。 这是因为相机功能点云非常大:对于典型的工作负载每帧可能会产生大约200万个点,比激光雷达特征点云密度高两个数量级。 为了解决这一效率瓶颈,我们提出了通过precomputation和interval reduction来优化BEV pooling。
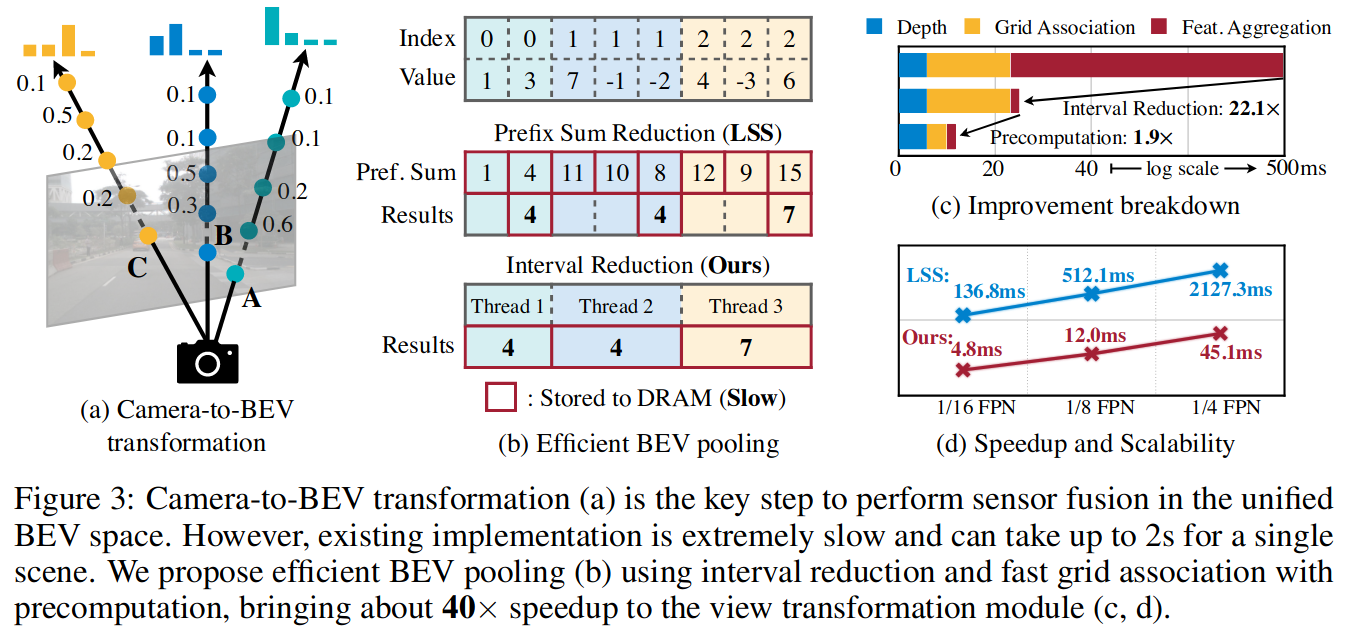
通过预计算,把点云中的每个点赋予在BEV网格的排序编号。
BEV池化的第一步是将摄像机特征点云中的每个点与一个BEV网格关联起来。网格关联后,同一BEV网格内的所有点将在张量表示中是连续的。
与激光雷达点云不同的是,相机特征点云的坐标是固定的(只要相机内参和外力保持不变,通常经过正确的校准后就是这样)。
这种缓存机制可以将网格关联的时延从17ms降低到4ms
在栅格关联之后,同一BEV栅格内的所有点在张量表示中将连续排列。BEV pooling 的下一步是通过某种均匀的函数(例如,均值、最大值和总和)聚合每个BEV网格中的特征。
如图3(b)所示现有执行情况首先计算所有点的前缀和,然后减去索引变化边界处的值。 然而,前缀和操作需要在GPU上进行tree reduction,并产生许多未使用的部分和(因为我们只需要边界上的那些值),这两种操作都是低效的。
为了加速特征聚合,我们实现了一个专门的GPU内核,该内核直接在BEV网格上并行化:我们为每个网格分配一个GPU线程,该线程计算其间隔和并将结果写回。 该内核消除了输出之间的依赖关系(因此不需要多级tree reduction),并避免将部分和写入DRAM(动态随机存储器),将特征聚合的延迟从500ms减少到2ms
通过优化的BEV池,相机到BEV的转换速度快了40:延迟从超过500ms减少到12ms(仅为我们模型端到端运行时间的10%),并且可以在不同的特征分辨率上进行扩展(图3d)。 这是在共享的BEV表示中统一多模态感官特征的关键使能器。 我们同时进行的两项工作也发现了仅摄像机三维检测的效率瓶颈。 它们通过假定均匀的深度分布来近似视图转换器或截断每个BEV网格内的点。 相比之下,我们的技术是精确的,没有任何近似,但仍然更快。
当所有的模态特征转换为共享的BEV表示时,我们可以很容易地用元素操作(如级联)将它们融合在一起。 在同一空间中,由于视图变换中的深度不准确,激光雷达和摄像机的BEV特征在空间上仍会出现一定程度的错位。 为此,我们应用了一个基于卷积的BEV编码器(带有少量残差块)来补偿这种局部不对齐。 我们的方法可能受益于更精确的深度估计(例如,用地面真实深度来监督视图),我们把它留到以后的工作中去。
我们将多个特定于任务的头应用于融合的BEV特征映射。 我们的方法适用于大多数三维感知任务。 我们展示了两个例子:三维物体检测和BEV地图分割。
我们使用一个特定于类的中心HeatMap头来预测所有对象的中心位置,并使用一些回归头来估计对象的大小、旋转和速度。
不同的地图类别可能会重叠(例如,人行横道是可驾驶空间的子集)。 因此,我们将此问题表述为多个二进制语义分割,每类一个。 我们遵循CVT用标准焦损训练分段头.
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/bev/bevfusion/bevfusion/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。