训练 Pytorch 模型时会遇到
CUDA Out of Memory的问题,大部分情况下是模型本身占用显存超过硬件极限,但是有时是Pytorch 内存分配机制导致预留显存太多,从而报出显存不足的错误,针对这种情况,本文记录 Pytorch 内存分配机制,与通过配置max_split_size_mb来解决上述问题。
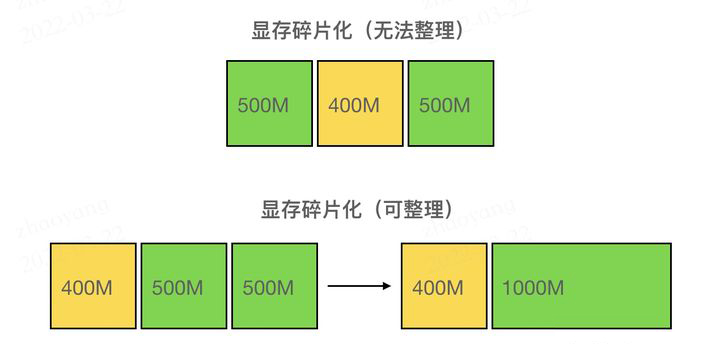
假如我们当前的显存分配如上图所示,假设当前想分配 800MB 显存,虽然空闲的总显存有 1000MB,但是上方图的空闲显存由地址不连续的两个 500MB 的块组成,不够分配这 800MB 显存;而下方的图中,如果两个 500MB 的空闲块地址连续,就可以通过显存碎片的整理组成一个 1000MB 的整块,足够分配 800MB。上方图的这种情况就被称为显存碎片化。
内存池,用 std::set 存储 Block 的指针,按照 (cuda_stream_id -> block size -> addr) 的优先级从小到大排序。所有保存在 BlockPool 中的 Block 都是空闲的。
DeviceCachingAllocator 中维护两种 BlockPool (large_blocks, small_blocks),分别存放较小的块和较大的块(为了分别加速小需求和大需求),简单地将 <= 1MB 的 Block 归类为小块,> 1MB 的为大块。
Block 在 Allocator 内有两种组织方式,一种是显式地组织在 BlockPool(红黑树)中,按照大小排列;另一种是具有连续地址的 Block 隐式地组织在一个双向链表里(通过结构体内的 prev, next 指针),可以以 O(1) 时间查找前后 Block 是否空闲,便于在释放当前 Block 时合并碎片。
Pytorch 申请显存需要用到 malloc 函数:返回一个可用的 Block(L466)
表述定义:
hard-coded:
根据 size 决定实际上的 alloc_size(get_allocation_size 函数,L1078):
Pytorch 在申请显存时会寻找是否有合适的 block, 该过程有五个步骤,如果这五个步骤都没找到合适的 Block,就会报经典的 [CUDA out of memory. Tried to allocate …] 错误。
TLDR:尝试在 Allocator 自己维护的池子中找一个大小适中的空闲 Block 返回。
*** TLDR = Too Long; Didn’t Read**
PYTORCH_CUDA_ALLOC_CONF 中指定了一个阈值 max_split_size_mb,有两种情况不会在此步骤分配:max_split_size_mb 涉及一个有趣的特性,后面会讲到。TLDR:手动进行一波垃圾回收,回收掉没人用的 Block,再执行步骤一。
get_free_block 失败,则在第二步中先调用 trigger_free_memory_callbacks,再调用一次第一步的 get_free_block;trigger_free_memory_callbacks 本质上通过注册调用了 CudaIPCCollect 函数,进而调用 CudaIPCSentDataLimbo::collect 函数(torch/csrc/CudaIPCTypes.cpp : L64);CudaIPCSentDataLimbo 类管理所有 reference 不为 0 的 Block,所以实际上 collect 函数的调用算是一种懒更新,直到无 Block 可分配的时候才调用来清理那些 reference 已经为 0 的 Block(值得一提的是,该类的析构函数会首先调用 collect 函数,见 torch/csrc/CudaIPCTypes.cpp : L58);torch/csrc/CudaIPCTypes.h & .cpp。TLDR:Allocator 在已有的 Block 中找不出可分配的了,就调用 cudaMalloc 创建新的 Block。
上面几个步骤都是试图找到一些空闲显存,下面是两个步骤是尝试进行碎片整理,凑出一个大块显存
TLDR:先在自己的池子里释放一些比较大的 Block,再用 cudaMalloc 分配看看
alloc_block 失败了,就会尝试先调用这一函数,找到比 size 小的 Block 中最大的,由大至小依次释放 Block,直到释放的 Block 大小总和 >= size(需要注意,这一步骤只会释放那些大小大于阈值 max_split_size_mb 的 Block,可以理解为先释放一些比较大的);release_block(L1241),主要就是 cudaFree 掉指针,再处理一些 CUDA graphs 的依赖,更新其他数据结构等等,最后把这个 Block 从 BlockPool 中移除;max_split_size_mb。如果将这样的 Block 全部释放的空间仍比 size 小,那么这一步就会失败。alloc_block 函数,创建新 Block。alloc_block 函数。如果经历上述5个步骤还是没有找到合适的块用于显存申请,则会报出经典的 CUDA out of memory. Tried to allocate ... 错误,例如:
CUDA out of memory. Tried to allocate 1.24 GiB (GPU 0; 15.78 GiB total capacity; 10.34 GiB already allocated; 435.50 MiB free; 14.21 GiB reserved in total by PyTorch)
注意,reserved + free 并不等同于 total capacity,因为 reserved 只记录了通过 PyTorch 分配的显存,如果用户手动调用 cudaMalloc 或通过其他手段分配到了显存,是没法在这个报错信息中追踪到的(又因为一般 PyTorch 分配的显存占大部分,分配失败的报错信息一般也是由 PyTorch 反馈的)。
在这个例子里,device 只剩 435.5MB,不够 1.24GB,而 PyTorch 自己保留了 14.21GB(储存在 Block 里),其中分配了 10.3GB,剩 3.9GB。那为何不能从这 3.9GB 剩余当中分配 1.2GB 呢?原因肯定是碎片化了,而且是做了整理也不行的情况。
我们已经经历了努力寻找显存但是没有成功的过程,那么当我们空闲显存明显比需要申请的显存大很多时候这个过程就存在不太合理的地方了。解决问题的关键在于 CUDA 中的 max_split_size_mb 变量设置。
官方文档:
1 | |
max_split_size_mb 可以防止本机分配程序拆分大于此大小的块(以 MB 为单位),以此减少显存碎片,并且可能允许在不耗尽内存的情况下完成一些边界工作负载。
根据 知乎大神 的Pytorch 显存分配源码解读,max_split_size_mb 的作用应该是限制分配显存时连续空闲显存块的大小的,通过这个阈值降低分配显存时直接拆分大块连续显存的概率。
他起作用的核心在于 get_free_block 函数中:我当前需要申请 size 大小的显存,阈值为 max_split_size_mb,此时我找到了 Block 大小的空闲块:
size < max_split_size_mb (一个小块),但是 Block > max_split_size_mb 则不会直接执行显存分配(避免拆分大块空闲显存,导致 Block 浪费)size > max_split_size_mb 并且 Block > max_split_size_mb,但是 Block - size > 20MB,也不会执行显存分配,这个机制使得大于 20MB 的显存碎片不那么容易产生至于
max_split_size_mb影响数据、模型拆分、是内存分配的最大值等说法,个人不敢苟同。
典型的使用 max_split_size_mb 可以大概率解决的错误信息类似这种:
1 | |
这里 Pytorch 保留显存 17.62 GiB,已分配内存 11.39 GiB,中间 6 个多 g 显存没有充分利用,表示当前碎片化比较严重,这种情况可以尝试降低 max_split_size_mb 的值来降低碎片出现的概率。
直接修改环境变量即可,建议在 Python 运行过程中临时修改,避免不必要的性能降低
1 | |
单位 MB
文章链接:
https://www.zywvvd.com/notes/environment/cuda/cuda-outof-memory/cuda-outof-memory/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。