雪花算法是一种分布式全局唯一
ID生成的方法,本文记录相关内容。
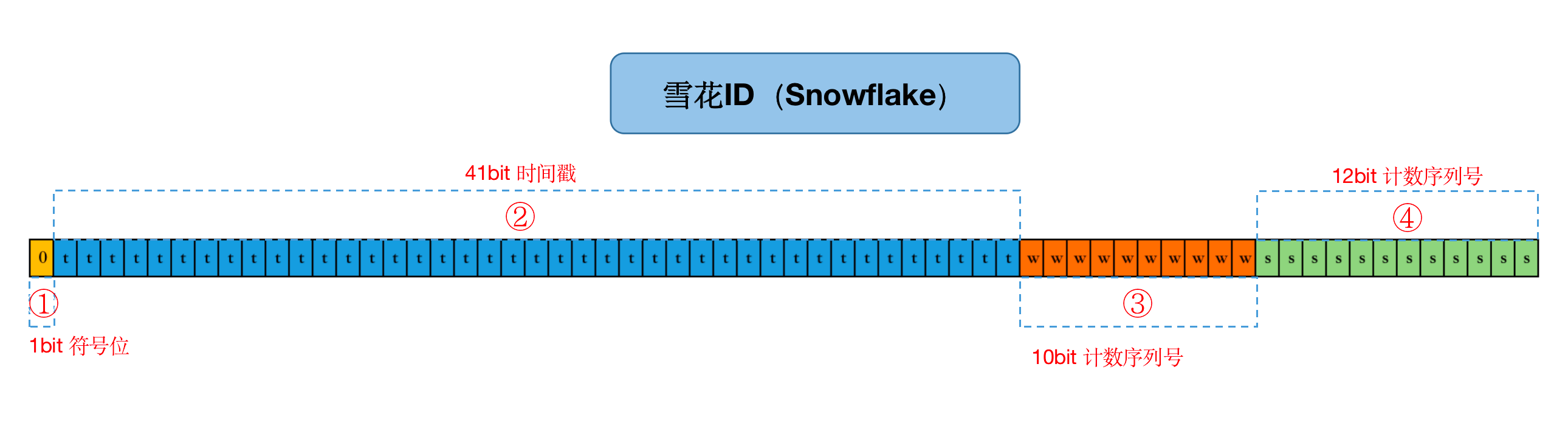
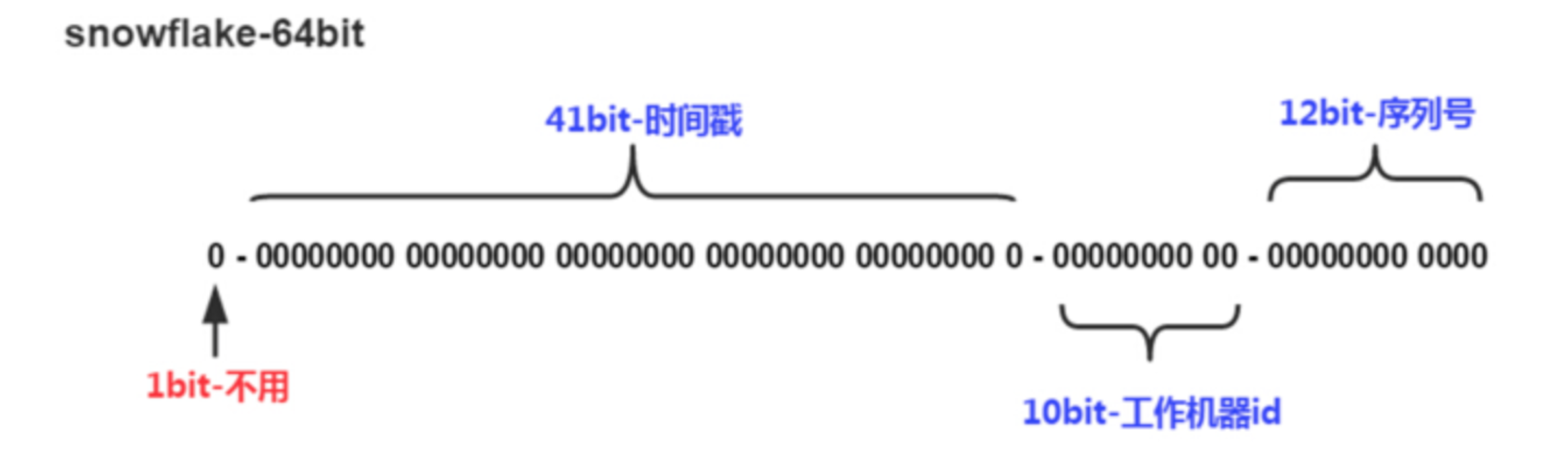
Twitter 于 2010 年开源了内部团队在用的一款全局唯一 ID 生成算法 Snowflake,翻译过来叫做雪花算法。Snowflake 不借助数据库,可直接由编程语言生成,它通过巧妙的位设计使得 ID 能够满足递增属性,且生成的 ID 并不是依次连续的。

Snowflake的其目是生成一个64bit的整数。
SnowFlake的优点是:
(1)单机上整体自增,集群上整体自增,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞;
(2)效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
(3)强依赖性,依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成id冲突或者重复。
Github:https://github.com/twitter-archive/snowflake/tree/b3f6a3c6ca8e1b6847baa6ff42bf72201e2c223
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,算法会直接抛出异常.
1 | |
1 | |
1 | |
1 | |
0.31 秒生成一百万条 ID
1 | |
1 | |
0.28 秒生成一百万条 ID
1 | |
启动
启动pysnowflake —pysnowflake基于Tornado开发,启动时相当于一个服务
1 | |
参数说明:可以通过–help查看
—address:本机的IP地址默认localhost
—dc:数据中心唯一标识符默认为0
—worker:工作者唯一标识符默认为0
—log_file_prefix:日志文件所在位置
也可以后台启动,如下:
1 | |
获取 id
1 | |
性能测试
0.54秒生成 1000 个雪花 id,好处就是可以保证全局使用同一个 id 源。
使用时一定要使用单例模式构建雪花生成器对象,否则多线程快速生成 ID 的场景很容易 ID 碰撞。
python中为位运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| << | 左移运算符:运算数的各二进位全部左移若干位, 由<<右边的数字指定了移动的位数,高位丢弃(前面无效的0),低位补0. |
60 << 2 = 240 |
| >> | 右移运算符:把>>左边的的运算数的各二进位全部 右移若干位,运算符右边的数字指定了右移的位数。 低位丢弃(无效的0),高位补0. |
60>>2 = 15 |
| ^ | 按位异或运算符:当两两对应的二进位相异时,结果取1. | 01^11 = 10 |
1 | |
1 | |
文章链接:
https://www.zywvvd.com/notes/study/algorithm/math/snowflake/snowflake/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。