SURF,英文的全称为 Speed Up Robust Features,直译为:加速版的具有鲁棒特性的特征算法,是由Bay在2006年首次提出的,本文记录相关内容。
加速鲁棒特征(Speed Up Robust Feature, SURF)和SIFT特征类似,同样是一个用于检测、描述、匹配图像局部特征点的特征描述子。SURF 对经典的尺度不变特征变换算法(SIFT算法)进行了改进,SIFT算法最大的缺点就是如果不借助硬件或者专门的图像处理器进行加速的话,SIFT算法很难达到实时处理的效果。SURF算法最大的特征在于采用了Haar特征以及积分图像的概念,这大大的加速了程序的运行时间。SURF算法不仅保持了SIFT算法的尺度不变和旋转不变的特性,而且对光照变化和放射变化同样具有很强的鲁棒性。SURF算法一般应用于计算机视觉中的物体识别、图像拼接、图像配准以及3D重建中。
论文链接:https://link.springer.com/chapter/10.1007/11744023_32
图像点的二阶微分Hessian矩阵的行列式(Determinant of Hessian, DoH)极大值,可用于图像的斑点检测(Blob Detection)。
构建Hessian矩阵的目的是为了生成图像稳定的边缘点(突变点),跟Canny、拉普拉斯边缘检测的作用类似,为特征提取做准备。
构建Hessian矩阵的过程对应着SIFT算法中的DoG过程。
黑塞矩阵(Hessian Matrix)是由一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。由德国数学家 Ludwin Otto Hessian 于19世纪提出。
对于一个图像 $𝐼(𝑥,𝑦)$,其Hessian矩阵如下:
$$ H(I(x,y))=\begin{bmatrix} \frac{\partial^2I}{\partial{x^2}} & \frac{\partial^2I}{\partial{x}\partial{y}} \\ \frac{\partial^2I}{\partial{x}\partial{y}} & \frac{\partial^2I}{\partial{y^2}} \end{bmatrix} $$
H矩阵的判别式 (行列式) 是:
$$ Det(H)=\frac{\partial^2I}{\partial{x^2}}*\frac{\partial^2I}{\partial{y^2}}-\frac{\partial^2I}{\partial{x}\partial{y}} * \frac{\partial^2I}{\partial{x}\partial{y}} $$
在构建Hessian矩阵前需要对图像进行高斯滤波,经过滤波后的Hessian矩阵表达式为:
$$ H(x,y,\sigma)=\begin{bmatrix} L_{xx}(x,y,\sigma) & L_{xy}(x,y,\sigma) \\ L_{xy}(x,y,\sigma) & L_{yy}(x,y,\sigma) \end{bmatrix} $$
其中 $(𝑥,𝑦)$ 为像素位置, $𝐿(𝑥,𝑦,𝜎)=𝐺(𝜎)𝐼(𝑥,𝑦)$, 代表着图像的高斯尺度空间,是由图像和不同的高斯卷积得到。
我们知道在离散数学图像中,一阶导数是相邻像素的灰度差:
$$
L_x=L(x+1,y)-L(x,y)
$$
二阶导数是对一阶导数的再次求导:
$$
L_{xx}=[L(x+1,y)-L(x,y)]-[L(x,y)-L(x-1,y)]
$$
$$
=L(x+1,y)+L(x-1,y)-2L(x,y)
$$
反过来看Hessian矩阵的列式值 DoH,其实就是当前点对水平方向二阶偏导数乘以垂直方向二阶偏导数再减去当前水平、垂直二阶偏导的二次方:
$$
Det(H)=L_{xx}*L_{yy}-L_{xy}*L_{xy}
$$
与LoG算子一样,DoH同样反映了图像局部的纹理或结构信息,与LoG相比,DoH对图像中细长结构的斑点有较好的抑制作用。LoG和DoH在利用二阶微分算子对图像进行斑点检测时,都需要利用高斯滤波平滑图像、抑制噪声,检测过程主要分为以下两步:
通过这种方法可以为图像中每个像素计算出其H行列式的决定值,并用这个值来判别图像局部特征点。Hession矩阵判别式中的$𝐿(𝑥,𝑦)$是原始图像的高斯卷积,从中心点往外,系数越来越小,为了将模板与图像的卷积转化为盒子滤波器(Box Filter)运算,并能够使用积分图,需要对高斯二阶微分模板进行简化,使得简化后的模板只是由几个矩形区域组成,SURF算法使用了盒式滤波器来替代高斯滤波器 $𝐿$,所以在$𝐿_{𝑥𝑦}$上乘了一个加权系数0.9,目的是为了平衡因使用盒式滤波器近似所带来的误差,则H矩阵判别式可表示为:
$$ Det(H)=L_{xx}*L_{yy}-(0.9*L_{xy})^2 $$
盒式滤波器和高斯滤波器的示意图如下:
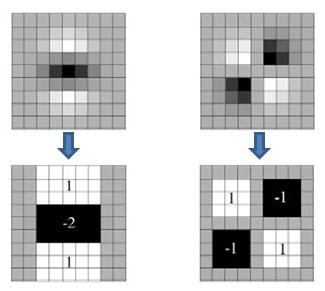
上面两幅图是$9×9$ 高斯滤波器模板分别在图像垂直方向上二阶导数$𝐿_{𝑦𝑦}$和 $𝐿_{𝑥𝑦}$对应的值,下边两幅图是使用盒式滤波器对其近似,灰色部分的像素值为0,黑色为-2,白色为1.
那么为什么盒式滤波器可以提高运算速度呢?这就涉及到积分图的使用,盒式滤波器对图像的滤波转化成计算图像上不同区域间像素的加减运算问题,这正是积分图的强项,只需要简单积分查找积分图就可以完成。
对于 $𝜎=1.2$ 的高斯二阶微分滤波,设定模板的尺寸为 $9×9$ 的大小,并用它作为最小尺度空间值对图像进行滤波和斑点检测。使用 $D_{xx}、D_{yy}、D_{xy}$ 表示简化模板与图像进行卷积的结果,Hessian矩阵的行列式可进一步简化为:
$$ Det(H)=L_{xx}L_{yy}-L_{xy}^2=D_{xx} \dfrac{L_{xx}}{D_{xx}} D_{yy} \dfrac{L_{yy}}{D_{yy}} - D_{xy} \dfrac{L_{xy}}{D_{xy}} D_{xy} \dfrac{L_{xy}}{D_{xy}} $$ $$ = D_{xx}D_{yy}(\dfrac{L_{xx}}{D_{xx}} \dfrac{L_{yy}}{D_{yy}}) - D_{xy} D_{xy} \dfrac{L_{xy}}{D_{xy}} \dfrac{L_{xy}}{D_{xy}} = (D_{xx}D_{yy} - D_{xy} D_{xy} Y)C $$ $$ Y = (\dfrac{L_{xy}}{D_{xy}} \dfrac{L_{xy}}{D_{xy}}) (\dfrac{D_{xx}}{L_{xx}} \dfrac{D_{yy}}{L_{yy}}) $$ $$ C = \dfrac{L_{xx}}{D_{xx}} \dfrac{L_{yy}}{D_{yy}} $$ 式中: $$ Y=(||L_{xy}(1.2)||_F ||D_{xx}(9)||_F)/(||L_{xx}(1.2)||_F ||D_{xy}(9))||_F)=0.912 \approx 0.9 $$
$||X||_F$ 为Frobenius范数,1.2 是 LoG 的尺度 $𝜎$,9 是 box filter 的尺寸。
理论上说,对于不同的 $𝜎$ 值和对应的模板尺寸,$𝑌$ 值应该是不同的,但为了简化起见,可将其视为一个常数,同样 $𝐶$ 也为一常数,且不影响极值求取,因此,DoH可近似如下:
$$
Det(H_{approx}) = D_{xx} D_{yy} - (0.9D_{xy})^2
$$
在实际计算滤波响应值时,需要使用模板中盒子(矩形)区域的面积进行归一化处理,以保证一个统一的 Frobenius 范数能适应所有的滤波尺寸。
使用近似的Hessian矩阵行列式来表示一个图像中某一点处的斑点响应值,遍历图像中的所有像素,便形成了在某一尺度下斑点检测的响应图像。使用不同的模糊尺度和模板尺寸,便形成了多尺度斑点响应的金字塔图像,利用这一金字塔图像,可以进行斑点响应极值点的搜索定位,其过程与SIFT算法类似。
我在学习到算法的这一部分时产生疑问,讲道理使用 Hession 矩阵判定极值点,需要矩阵正定或负定,这是相对麻烦的判定条件,但是实际使用是仅靠矩阵的行列式进行极值点的判定,是否会出问题。
事实上在特征点检测中,我们通常对Hessian矩阵的行列式感兴趣,因为它可以帮助我们判断一个点是局部极值点还是边缘点。具体来说:
也就是说,从理论上确实无法依据hession 行列式判定极值点,但是如果一个点的 Hession 矩阵行列式的值很大,可以大概率判定这是个极值点,这个概率对于工程应用来说已经足够宝贵
然而使用Hessian矩阵的行列式来判断极值点和边缘点只是一种可能性,而不是绝对的。在实际应用中,确实存在误判的情况,但是这种方法在大多数情况下都是有效的,并且在计算上相对高效。为了提高准确性,通常会结合其他方法和步骤来进一步确认和筛选特征点。
以下是几个关键点,说明了为什么这种方法在实际中仍然被广泛使用:
总的来说,虽然Hessian矩阵的行列式不能完全准确地判断一个点是否是极值点或边缘点,但在实际的计算机视觉应用中,通过结合多种方法和步骤,可以大大提高特征点检测的准确性和鲁棒性。这也是为什么这种方法仍然被广泛使用的原因。
要想检测不同尺度的极值点,必须建立图像的尺度空间金字塔。一般的方法是通过采用不同 $𝜎$ 的高斯函数,对图像进行平滑滤波,然后重采样获得更高一层(Octave)的金字塔图像。Lowe在SIFT算法中就是通过相邻两层(Interval)高斯金字塔图像相减得到DoG图像,然后在DoG金字塔图像上进行特征点检测。与SIFT特征不同的是,SURF算法不需要通过降采样的方式得到不同尺寸大小的图像建立金字塔,而是借助于盒子滤波和积分图像,不断增大盒子滤波模板,通过积分图快速计算盒子滤波的响应图像。然后在响应图像上采用非极大值抑制,检测不同尺度的特征点。
同SIFT算法一样,SURF算法的尺度空间由$𝑂$组$𝑆$层组成,不同的是,SIFT算法下一组图像的长宽均是上一组的一半,同一组不同层图像之间尺寸一样,但是所使用的尺度空间因子(高斯模糊系数$𝜎$)逐渐增大;而在SURF算法中,不同组间图像的尺寸都是一致的,不同的是不同组间使用的盒式滤波器的模板尺寸逐渐增大,同一组不同层图像使用相同尺寸的滤波器,但是滤波器的尺度空间因子逐渐增大。如下图所示 (左侧为 SIFT 算法缩放图像,右侧为 SURF 盒状滤波核尺寸缩放):
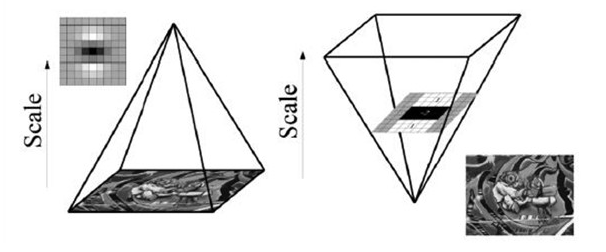
由于采用了box filter和积分图,滤波过程并不随着滤波模板尺寸的增大而增加运算量。
在建立盒状滤波金字塔时,与SIFT算法类似,需要将尺度空间划分为若干组(Octaves)。每组又由若干固定层组成,包括不同尺寸的滤波模板对同一输入图像进行滤波得到的一系列响应图。由于积分图像的离散特性,两个相邻层之间的最小尺度变化量,是由高斯二阶微分滤波模板在微分方向上对正负斑点响应长度(波瓣长度)$𝑙_0$决定的,它是盒子滤波模板尺寸的1/3。
对于$9×9$ 的滤波模板,$𝑙_0$ 为3。下一层的响应长度至少应该在 $𝑙_0$ 的基础上增加2个像素,以保证一边一个像素,即$𝑙_0=5$,这样模板的尺寸为 $15×15$,如下图所示。依次类推,可以得到一个尺寸逐渐增大的模板序列,尺寸分别为 $9×9$、$15×15$、$21×21$、$27×27$。
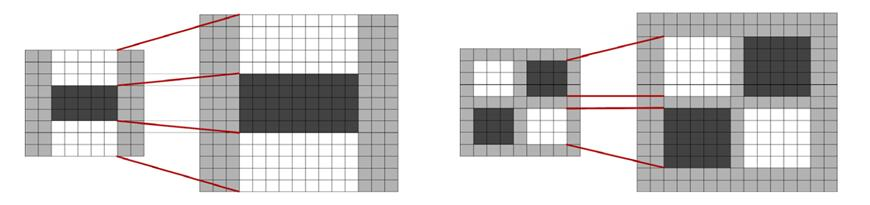
显然,第一个模板和最后一份模板产生的 Hessian 响应图像只作为比较用,而不会产生最后的响应极值。这样,通过插值计算,可能的最小尺度值为$𝜎=1.2×(15+9)/2/9=1.6$,对应的模板尺寸为 $12×12$;可能的最大尺度值为$𝜎=1.2×(27+21)/2/9=3.2$,对应的模板尺寸为 $24×24$。
采用类似的方法处理其他组的模板序列,其方法是将滤波器尺寸增加量按Octave的组数 $𝑚$ 翻倍,即$6×2^{𝑚−1}$,序列依次为$(6,12,24,48,…)$,这样,在盒状滤波金字塔中,每组滤波器的尺寸如下图所示,滤波器的组数可由原始图像的尺寸决定。对数水平轴代表尺度,组之间有相互重叠,其目的是为了覆盖所有可能的尺度。在通常尺度分析情况下,随着尺度的增大,被检测的特征点数迅速衰减。

滤波器的尺寸 $𝐿$、滤波响应长度 $l$、组索引 $𝑜$、层索引 $𝑠$、尺度 $𝜎$ 之间的相互关系如下:
$$
L=3 \times (2^{o+1}(s+1)+1)
$$
$$
l=\dfrac{L}{3}=2^{o+1}(s+1)+1
$$
$$
\sigma=1.2 \times \dfrac{L}{9} = 1.2 \times \dfrac{l}{3}
$$
SURF特征点的定位过程和SIFT算法一致,将经过Hessian矩阵处理的每个像素点(即获得每个像素点Hessian矩阵的判别式值)与其图像域(相同大小的图像)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。
如图所示,中间的检测点要和其所在图像的$3×3$邻域8个像素点,以及其相邻的上下两层$3×3$邻域18个像素点,共26个像素点进行比较。
初步定位出特征点后,再经过滤除能量比较弱的关键点以及错误定位的关键点,筛选出最终的稳定的特征点。

然后,采用3维线性插值法得到亚像素级的特征点,同时去掉一些小于给定阈值的点,使得极值检测出来的特征点更稳健。和DoG不同的是,不需要剔除边缘导致的极值点,因为Hessian矩阵的行列式已经考虑了边缘的问题。
为了保证特征描述子具有旋转不变性,与SIFT一样,需要对每个特征点分配一个主方向。
SIFT 算法特征点的主方向是采用在特征点邻域内统计其梯度直方图,横轴是梯度方向的角度,纵轴是梯度方向对应梯度幅值的累加,取直方图bin最大的以及超过最大80%的那些方向作为特征点的主方向。
而在SURF算法中,采用的是统计特征点圆形邻域内的Harr小波特征,即在特征点的以 $6𝑠$ (s为特征点的尺度)为半径的区域内,求Haar小波响应。Haar小波模板如下图所示,用于计算梯度的Haar小波的尺度是 $4𝑠$,扫描步长为 $𝑠$。
计算图像的Haar小波响应,实际上就是对图像进行梯度运算,只不过需要利用积分图,提高梯度计算效率。

使用 $𝜎=2𝑠$ 的高斯函数对 Haar 小波的响应值进行加权。为了求取主方向,设计一个以特征点为中心,张角为 $𝜋/3$ 的扇形窗口,如下图所示,以一定旋转角度 $𝜃$ 旋转窗口,并对窗口内的Haar小波响应值$𝑑𝑥、𝑑𝑦$ 进行累加,得到一个矢量 $(m_w, \theta_w)$
$$
m_w=\Sigma_w dx + \Sigma_w dy
$$
$$
\theta_w=arctan(\Sigma_w dy / \Sigma_w dx)
$$
主方向为最大 Haar 响应累加值所对应的方向,即 $\theta=\theta_w|max{m_w}$
统计60度扇形内所有点的水平、垂直Harr小波特征总和,然后扇形以0.2弧度大小的间隔进行旋转并再次统计该区域内Harr小波特征值之后,最后将值最大的那个扇形的方向作为该特征点的主方向。
或者仿照SIFT求主方向时策略,当存在大于主峰值80%以上的峰值时,则将对应方向认为是该特征点的辅方向。一个特征点可能会被指定多个方向,可以增强匹配的鲁棒性。
该过程示意图如下:

在SIFT算法中,为了保证特征矢量的旋转不变性,先以特征点为中心,在附近邻域内将坐标轴旋转$𝜃$(特征点的主方向)角度,然后提取特征点周围$4×4$个区域块,统计每小块内8个梯度方向,这样一个关键点就可以产生128维的SIFT特征向量。
SURF算法中,也是提取特征点周围$4×4$个矩形区域块,但是所取得矩形区域方向是沿着特征点的主方向,而不是像SIFT算法一样,经过旋转$𝜃$角度。每个子区域统计25个像素点水平方向和垂直方向的Haar小波特征,这里的水平和垂直方向都是相对主方向而言的,以特征点为中心,沿主方向将 $20𝑠×20𝑠$ 的邻域划分为 $4×4$ 个子块,每个子块利用尺寸为$2𝑠$ 的Haar模板计算响应值。该Harr小波特征为水平方向值之和、垂直方向值之和、水平方向值绝对值之和以及垂直方向绝对之和4个方向。该过程示意图如下:
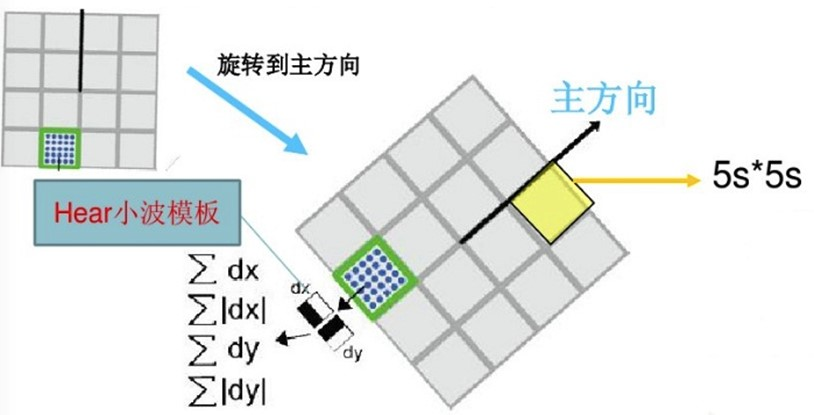
将 $20𝑠$ 的窗口划分为 $4×4$ 个子窗口,每个子窗口大小为 $5𝑠×5𝑠$,使用尺寸为 $2𝑠$ 的 Haar 小波计算子窗口的响应值;然后,以特征点为中心,用$𝜎=10𝑠/3=3.3𝑠$的高斯核函数对 $𝑑𝑥、𝑑𝑦$ 进行加权计算;最后,分别对每个子块的加权响应值进行统计,得到每个子块的向量:
$$
V_i=[\Sigma dx,\Sigma |dx|,\Sigma dy,\Sigma |dy|]
$$
把这4个值作为每个子块区域的特征向量,所以一共有 $4×4×4=64$ 维向量作为SURF特征的描述子,比SIFT特征的描述子减少了一半。
SURF 描述子不仅具有尺度和旋转不变性,还具有光照不变性,这由小波响应本身决定,而对比度不变性则是通过将特征向量归一化来实现。下图为3种简单模式图像及其对应的特征描述子,可以看出,引入Haar小波响应绝对值的统计和是必要的,否则只计算 $Σ𝑑𝑥、Σ𝑑𝑦$ 的话,第一幅图和第二幅图的特征表现形式是一样的,因此,采用4个统计量描述子区域使特征更具有区分度。

为了充分利用积分图像计算Haar小波的响应值,在具体实现中,并不是直接通过旋转Haar小波模板求其响应值,而是在积分图像上先使用水平和垂直的Haar模板求得响应值$𝑑𝑥、𝑑𝑦$,对 $𝑑𝑥、𝑑𝑦$ 进行高斯加权处理,并根据主方向的角度,对 $𝑑𝑥、𝑑𝑦$ 进行旋转变换,从而得到旋转后的$dx′、dy′$。
SURF 在求取描述子特征向量时,是对一个子块的梯度信息进行求和,而SIFT是依靠单个像素计算梯度的方向。在有噪声的干扰下,SURF描述子具有更好的鲁棒性。一般而言,特征向量的长度越长,所承载的信息量就越大,特征描述子的独特性就越好,但匹配时所付出的时间代价也越大。对于SURF描述子,可以将其扩展到128维。具体方法就是在求Haar小波响应值的统计和时,区分 $𝑑𝑥≥0$ 和 $𝑑𝑥<0$ 的情况,以及 $𝑑𝑦≥0$ 和 $dy<0$ 的情况。
为了实现快速匹配,SURF在特征向量中增加了一个新的元素,即特征点的拉普拉斯响应正负号。在特征点检测时,将Hessian矩阵的迹(Trace)的正负号记录下来,作为特征向量中的一个变量。在特征匹配时可以节省运算时间,因为只用具有相同正负号的特征点才可能匹配,对于不同正负号的特征点不再进行相似性计算。
例如我们有一个一维的图像[2,4,6,8,10,12,14,16]。
| 分辨率 | 整体信息 | 细节信息 |
|---|---|---|
| 4 | 3,7,11,15 | -1,-1,-1,-1 |
| 2 | 5,13 | -2,-2 |
| 1 | 9 | -4 |
经过三次分解,我们得到了一个整体信息和三个细节系数,这个就是一维小波变换。
一维小波变换其实是将一维原始信号分别经过低通滤波和高通滤波以及二元下抽样得到信号的低频部分L和高频部分H。而根据Mallat算法,二维小波变换可以用一系列的一维小波变换得到。对一幅m行n列的图像,二维小波变换的过程是先对图像的每一行做一维小波变换,得到L和H两个对半部分;然后对得到的LH图像(仍是m行n列)的每一列做一维小波变换。这样经过一级小波变换后的图像就可以分为LL,HL,LH,HH四个部分,如下图所示,就是一级二维小波变换的塔式结构:
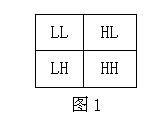
而二级、三级以至更高级的二维小波变换则是对上一级小波变换后图像的左上角部分(LL部分)再进行一级二维小波变换,是一个递归过程。下图是三级二维小波变换的塔式结构图:
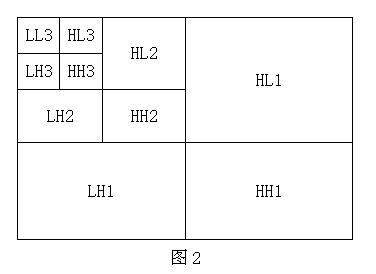
| SIFT | SURF | |
|---|---|---|
| 尺度空间 | 使用DoG金字塔与图像进行卷积操作,而且对图像有做降采样处理 | 近似DoH金字塔(即不同尺度的box filters)与图像做卷积,借助积分图,实际操作只涉及到数次简单的加减运算,而且不改变图像大小。 |
| 特征点检测 | 先进行非极大值抑制,去除对比度低的点,再通过Hessian矩阵剔除边缘点。 | 计算Hessian矩阵的行列式值(DoH),再进行非极大值抑制。 |
| 特征点主方向 | 在方形邻域窗口内统计梯度方向直方图,并对梯度幅值加权,取最大峰对应的方向。 | 在圆形区域内,计算各个扇形范围内 $𝑥、𝑦$ 方向的Haar小波响应值,确定响应累加和值最大的扇形方向。 |
| 特征描述子 | 将关键点附近的邻域划分为 $4×4$ 的区域,统计每个子区域的梯度方向直方图,连接成一个 $4×4×8=128$ 维的特征向量。 | 将 $20𝑠×20𝑠$ 的邻域划分为 $4×4$ 个子块,计算每个子块的Haar小波响应,并统计4个特征量,得到 $ 4×4×4=64$ 维的特征向量。 |
总体来说,SURF和SIFT算法在特征点的检测取得了相似的性能,SURF借助积分图,将模板卷积操作近似转换为加减运算,在计算速度方面要优于SIFT特征,体现在三个方面:
Python OpenCV 的环境配置对于 SIFT 和 SURF 来说复杂一些:
SIFT 和 SURF 等库不是来自与官方,需要按照 opencv-contrib 库才可能使用
这里 OpenCV 的 SIFT、SURF 等模块由于专利版权等原因,在 OpenCV 3.4.2 以及之后的版本不再免费开放,用户想要在 OpenCV 中用这几个库稍微麻烦了一些,强行使用会报错
1 | |
那么这里除了付费使用 OpenCV 的这些库之外,普通用户有两个路线解决该问题
这里不展开描述,之后如有必要会单独记录相关内容
图像1(原始图像)

图像2(缩放、旋转、错切)

1 | |
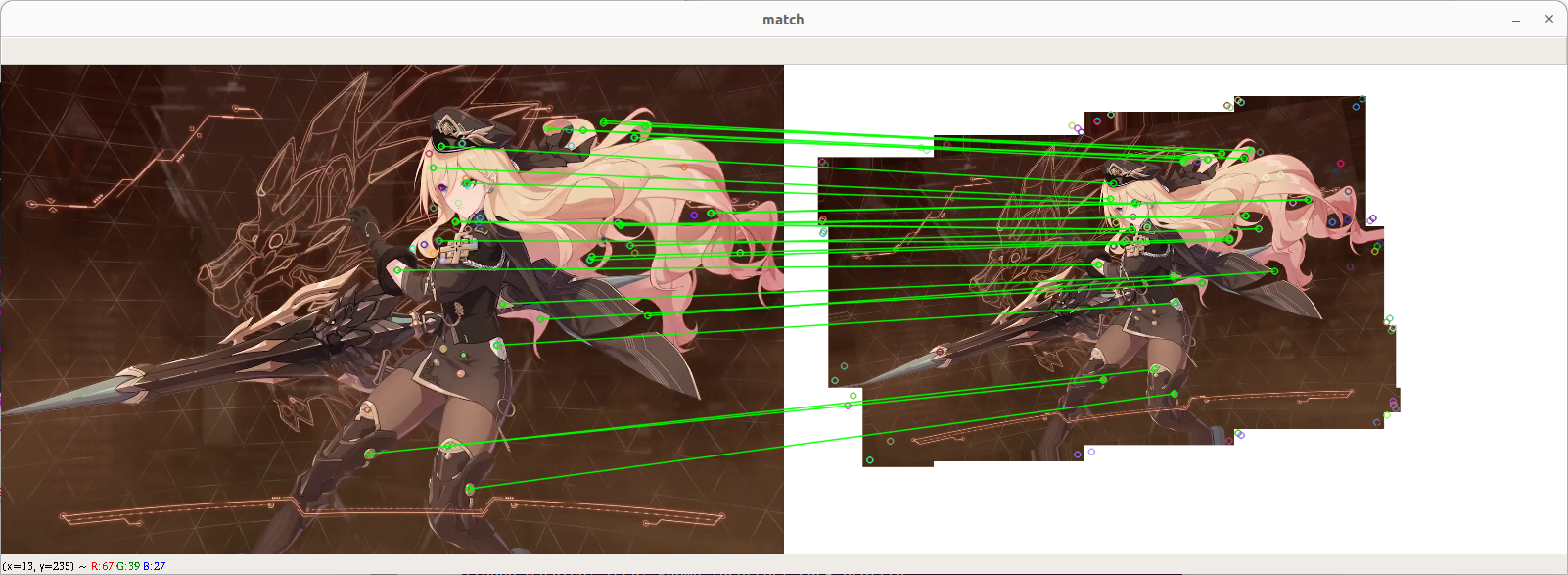
测试图像,缩放到 900*506
1 | |
三种特征示意图
#### 匹配效果
1 | |
SIFT

SURF

ORB

用比值判别法(ratio test)删除离群点:
检测出的匹配点可能有一些是错误正例(false positives)。
以为这里使用过的kNN匹配的k值为2(在训练集中找两个点),第一个匹配的是最近邻,第二个匹配的是次近邻。直觉上,一个正确的匹配会更接近第一个邻居。
换句话说,一个不正确的匹配,两个邻居的距离是相似的。因此,我们可以通过查看二者距离的不同来评判距匹配程度的好坏。比值检测认为第一个匹配和第二个匹配的比值小于一个给定的值(一般是0.5),这里是0.75。
Bay H, Tuytelaars T, Van Gool L. Surf: Speeded up robust features[C]//Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, May 7-13, 2006. Proceedings, Part I 9. Springer Berlin Heidelberg, 2006: 404-417.
https://blog.csdn.net/wsp_1138886114/article/details/90578810
文章链接:
https://www.zywvvd.com/notes/study/image-processing/feature-extraction/surf-fea/surf-fea/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。