机器学习中的异常检测在很多场景有重要应用,本文记录 SVDD 算法。
支持向量数据描述 SVDD(Support Vector Data Description,SVDD)是一种单值分类算法,能够实现目标样本和非目标样本的区分,通常应用于异常检测、入侵检测等领域。
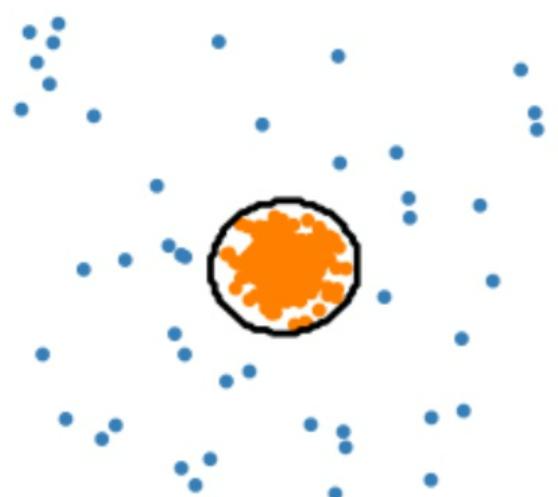
SVDD 的思路是寻找一个尽可能小的高维球体,将训练数据容纳进去,那么在预测数据时,认为在球体之外的数据为异常数据。
$$ (x^{(i)}−a)^T(x^{(i)}−a)≤R^2 $$
$$ \left(x^{(i)}-a\right)^{T}\left(x^{(i)}-a\right) \leq R^{2}+\xi_{i}, \xi \geq 0 $$
$$ \begin{array}{c} \min _{a, \xi,R} R^{2}+C \sum_{i=1}^{m} \xi_{i} \\ \text { s.t. }\left(x^{(i)}-a\right)^{T}\left(x^{(i)}-a\right) \leq R^{2}+\xi_{i}, \\ \quad \xi_{i} \geq 0, i=1,2, \cdots, m .\end{array} $$
其中,$ C>0$ 是惩罚参数,由人工设置。
$$ \begin{aligned} L(R, a, \alpha, \xi, \gamma)=& R^{2}+C \sum_{i=1}^{m} \xi_{i} -\sum_{i=1}^{m} \alpha_{i}\left(R^{2}+\xi_{i}-\left(x^{(i)^{T}} x^{(i)}-2 a^{T} x^{(i)}+a^{2}\right)\right)-\sum_{i=1}^{m} \gamma_{i} \xi_{i} . \end{aligned} $$
其中, $α_i≥0,γ_i≥0$ 是拉格朗日乘子。
此时事实上涉及到了需要用 $\alpha$ 选择支持向量了,但是此时其他参数都还没有确定,那么确定那个样本作为支持向量更是无从谈起,因此原始问题:
$$
\min_{R,a,\xi} \max_{\alpha,\gamma;\alpha\geq 0} L(R, a, \alpha, \xi, \gamma)
$$
无法求解,幸运的是该问题总体是凸优化问题,对偶问题与原问题等价,我们尝试求解对偶问题
$$
\max_{\alpha,\gamma;\alpha\geq 0} \min_{R,a,\xi} L(R, a, \alpha, \xi, \gamma)
$$
$$ \begin{array}{c} \sum_{i=1}^{m} \alpha_{i}=1 \\ a=\sum_{i=1}^{m} \alpha_{i} x^{(i)} \\ C-\alpha_{i}-\gamma_{i}=0 \end{array} $$
$$ \begin{array}{c} \max _{\alpha} L(\alpha)=\sum_{i=1}^{m} \alpha_{i} x^{(i)^{T}} x^{(i)}-\sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} x^{(i)^{T}} x^{(j)}\\ s.t. 0 \leq \alpha_{i} \leq C \\ \sum_{i=1}^{m} \alpha_{i}=1, i=1,2, \cdots, m . \end{array} $$
$$ (z-a)^{T}(z-a)>R^{2} $$
$$ z^{T} z-2 \sum_{i=1}^{m} \alpha_{i} z^{T} x^{(i)}+\sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} x^{(i)^{T}} x^{(j)}>R^{2} $$
正常情况下,数据并不会呈现球状分布,因此有必要使用核函数的方法提高模型的表达能力。
只需将 $ {K}\left(x^{(i)}, x^{(j)}\right) $ 替换 $ x{(i){T}} x^{(j)} $ 即可。
在训练前通过变换函数$Φ:x→F$ 将数据从原始空间映射到新特征空间, 然后在新特征空间中导找一个体积最小的超球体, SVDD 要解决的优化问题变为:
$$ \begin{array}{c} \min _{\mathbf{a}, R, \xi} R^{2}+C \sum_{i=1}^{n} \xi_{i}\\ s.t. \left\|\Phi\left(\mathbf{x}_{i}\right)-\mathbf{a}\right\|^{2} \leq R^{2}+\xi_{i}, \\\xi_{i} \geq 0, \forall i=1,2, \cdots, n \end{array} $$
$$ \begin{array}{c} \min _{\alpha_{i}} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_{i} \alpha_{j} K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)-\sum_{i=1}^{n} \alpha_{i} K\left(\mathbf{x}_{i}, \mathbf{x}_{i}\right) \\ s.t. \quad 0 \leq \alpha_{i} \leq C, \\ \sum_{i=1}^{n} \alpha_{i}=1 \\ \end{array} $$
$$ \mathbf{a}=\sum_{i=1}^{n} \alpha_{i} \Phi\left(\mathbf{x}_{i}\right) $$ $$ R=\sqrt{K\left(\mathbf{x}_{v}, \mathbf{x}_{v}\right)-2 \sum_{i=1}^{n} \alpha_{i} K\left(\mathbf{x}_{v}, \mathbf{x}_{i}\right)+\sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_{i} \alpha_{j} K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)} $$
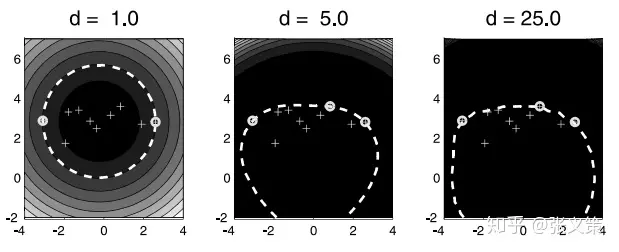
$$ \mathcal {K} \left ( x ^ { (i) ^ {T} } x ^ {(j) } \right ) = (x ^ {(i) ^ {T}} x ^ {(j)}+1) ^ {d} $$
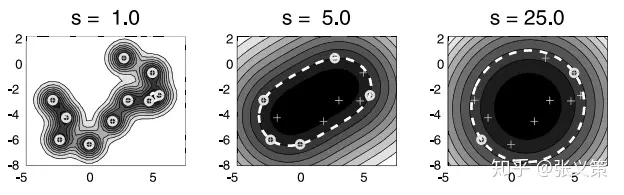
$$ \mathcal{K}\left(x^{(i)^{T}} x^{(j)}\right)=\exp (\frac{-\left(x^{(i)}-x^{(j)}\right)^{2}}{s^{2}}) $$
文章链接:
https://www.zywvvd.com/notes/study/machine-learning/one-class/svdd/svdd/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。