本文记录异常检测23年性能最佳的工作 DDAD 的原理以及官方源码解析。
DDAD 是 2024 年以前 MVTec AD 数据集上性能最好的异常检测模型,本文解读相关论文并对源码进行解读
| 项目 | 内容 | 备注 |
|---|---|---|
| 方法名称 | DDAD | |
| 论文题目 | Anomaly Detection with Conditioned Denoising Diffusion Models[^25] | |
| 论文连接 | https://arxiv.org/pdf/2305.15956v2.pdf | |
| 开源代码 | https://github.com/arimousa/DDAD | |
| 发表时间 | 2023.12.03 | |
| 方法类别 | 深度学习 -> 基于重构 -> 扩散模型 | |
| Detection AU-ROC | 99.8% | |
| Segmentation AU-ROC | 98.1% | |
| Segmentation AU-PRO | 92.3% | |
| 核心思想 | 1. 利用输入图像和目标图像构建条件扩散模型, 用于输入图像重构 2. 通过预训练网络提取输入图像和重构图像特征进行比对, 结合像素级比对得到异常分数图 3. 用项目数据微调模型, 微调过程中运用原始预训练网络输出作为蒸馏损失加入到微调损失中, 达到既能使得模型适应当前数据, 同时保持了模型的泛化能力的效果 |
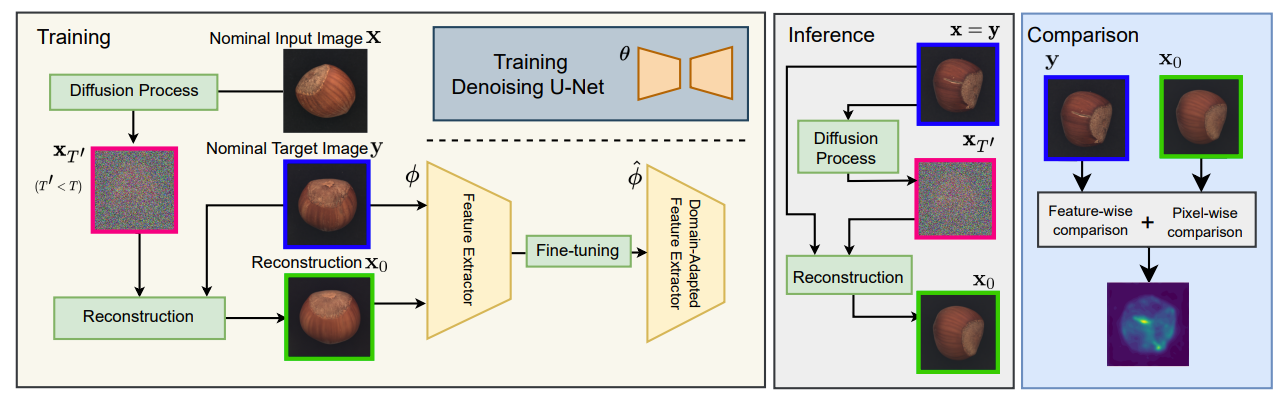
输入图像 $X$, 经过扩散过程得到随机的 $X_{T’}$, 之后需要通过 $X_{T’}$ 经过反扩散过程重构图像生成 $x_0$, 目标是 $y$. 因为重构目标是 $y$, 所以假设重构输出与目标接近, 即:$x_0 \approx y$, 假设从 $X_{T’}$ 到 $X_0$ 每一步添加的噪声为 $\epsilon_\theta^{(t)}$, 得到过程中的 $X_{T’},X_{T’-1},X_{T’-2}, …,X_2,X_1,X_0$, 反过来, 我们向 $y$ 逐步加入 $\epsilon_\theta^{(t)}$, 得到 $y, y_1,y_2, …,y_{T’-2},y_{T’-1},y_{T’}$, 那么根据假设可以推断 $y_t\approx x_t$, 那么就可以用 $y_t$ 指导每一步去噪产生 $x_t$ 的训练过程, 也就是带条件的扩散模型.
该步骤训练完成后会得到可以重构出和目标图像类似的扩散模型, 训练过程中仅使用 OK 数据进行训练, 这样扩散模型仅学会了重构 OK 数据的能力.
在异常检测推断流程中, 重构的目标图像会被设置为输入图像 $x$, 目的是基于 $x$ 生成一幅没有缺陷的重构图 $x_0$, 之后比对 $x_0$ 和 $x$ 之间的差异判断是否存在异常.
条件扩散模型将 AU-ROC 从 85.7% 提高到 92.4%
现在已经得到了 $x_0$ 和 $x$ , 如何对比二者得到异常分数图效果比较好呢. 最直接的想法是将二者直接在像素空间上作差, 结果用 $D_p$表示, 该方法确实直接有效, 但是无法抵抗一些重构过程中产生的噪声, 因此论文使用预训练的骨干网络提取特征作为额外的分数判定依据.
选择一个 ImageNet 预训练的骨干网络, 提取 $x_0$ 和 $x$ 的特征 (主要用下采样 2x 和 4x 的特征), , 计算二者特征的余弦距离作为特征度量差异距离 $D_f$.
最后将二者归一化加权叠加在一起得到异常分数:
$$
D_{anomaly}=\left(v\frac{\max(D_f)}{\max(D_p)}\right)D_p+D_f,
$$
其中 $v$ 为两种距离的权重参数.
按照算法的完备性至此已经可以完成异常检测工作了, 但是文章还试图解决 ImageNet 对当前数据适应性不是最优的问题, 尝试用项目数据对预训练模型进行微调, 使其适应当前的数据以获得更好的特征提取能力.
核心思想仍然基于之前的假设 $x_0 \approx y$ , 那么我们就希望网络对重构产生的误差不那么敏感, 也就是让网络觉得 $x_0$ 和 $y$ 的特征相近, 依此可以进行模型微调. 但是仅用这一个 loss 容易使得模型坍缩退化, 为了使得模型在保持原本的泛化能力的同时适应我们的需求, 作者在刚刚的损失函数基础上增加了当前模型对原始模型的特征蒸馏损失
$$ \begin{gathered} \mathcal{L}_{DA} =\mathcal{L}_{Similarity}(\mathbf{x_0},\mathbf{y})+\lambda_{DL}\mathcal{L}_{DL}(\mathbf{x_0},\mathbf{y}) \\ =\sum_{j\in J}\left(1-\cos(\phi_j(\mathbf{x}_0),\phi_j(\mathbf{y}))\right) \\ +\lambda_{DL}\sum_{j\in J}\left(1-\cos(\phi_j(\mathbf{y}),\overline{\phi}_j(\mathbf{y}))\right) \\ +\lambda_{DL}\sum_{j\in J}\left(1-\cos(\phi_{j}(\mathbf{x}_{0}),\overline{\phi}_{j}(\mathbf{x}_{0}))\right), \end{gathered} $$
如此完成模型的微调.
其中 $j\in {1,2,3}$
域适应性将 AU-ROC 从 92.4% 提高到99.8%

在 MVTec 数据集得到 99.8% 的图像 AU-ROC 和 97.2% 的分割 AU-ROC.
测试数据使用 MVTec AD 数据集,下载链接

开源仓库:https://github.com/arimousa/DDAD
当前 Commit ID: e4e11f1b4ff5cf0a2762c4d8a5dfdfb6bfa64303
将数据集放在仓库根目录 datasets/MVTec 文件夹中:
| 环境 | 版本 | 备注 |
|---|---|---|
| Python | 3.8.+ | |
| kornia | 0.6.12 | |
| matplotlib | 3.7.1 | |
| numpy | 1.24.3 | |
| omegaconf | 2.1.2 | |
| opencv-python-headless | 4.5.5.64 | |
| pandas | 2.0.1 | |
| Pillow | 9.5.0 | |
| scikit-image | 0.19.2 | |
| scikit-learn | 1.2.2 | |
| scipy | 1.10.1 | |
| torch | 2.0.1 | 2.0.1+cu118 |
| torchvision | 0.15.2 | 0.15.2+cu118 |
| torchmetrics | 0.11.4 | |
| sklearn | 0.0.post5 | 没有成功安装,未发现对程序运行的影响 |
核心代码都在根目录中:
1 | |
我们的 3080 显卡 10g 显存,可以使用如下配置训练 DDAD 模型:
配置文件为
config.yaml
1 | |
DDAD 实现异常检测需要分两阶段训练
推断时需要加载训练好的 Unet 和特征提取器
构建 Unet 模型的函数为 main.py -> build_model ,通过实例化 unet.py -> UNetModel 类实现。
核心函数在 dataset.py -> Dataset_maker 类中,根据文件夹名称构建所需数据集。
入口函数在 main.py -> train,核心代码在 train.py -> trainer 函数中
此处训练的是 去噪Unet 网络,期望网络可以将叠加在图像上的噪声恢复出来
向 Unet 输入带噪的图像,输出张量与噪声的二范数距离作为损失
1 | |
经过训练,可以使得 Unet 网络较好地预测添加到数据中的噪声
入口函数 main.py -> finetuning,核心代码在 reconstruction.py 中
微调特征提取器,这里使用的是 Resnet,由于算力有限这里采用 Resnet50
输入一个 batch 的数据一半为输入 一半为目标,训练重构器
同时兼顾原始模型的蒸馏损失
训练完成后保留特征提取器
入口函数 main.py -> detection,核心代码在 ddad.py 的 DDAD 类中
过程中可以在配置文件配置可视化参数为 True
结果保存可视化结果
测试结果
1 | |


结果被 center crop 到 224*224,可以实现一定的检测能力
这个结果远没有达到论文描述的水准,仓库中作者解释说这个去噪网络训练很不稳定,建议下载他们训练好的 Unet 模型,我下载了同规格的模型后性能得到一定提升
1 | |
可视化的图像的效果也要好一些
使用官网更大的模型在这组数据集上可以取得更好的结果
1 | |
但是本机的 3080 显存不足以支撑该训练,而且 WideResnet101 模型较大
graph TD
E(Unet)
B--> C
D(config)
G(noise)
H(trainer)
D -->H
E --> H
I(train)
H -->I
C--提取-->I
G--加入数据-->I
J(loss)
I --预测噪声-->J
J --更新参数--> E
A--组合-->B
A(DATA)
B(dataset)
C(dataloader)
graph TD
A(DATA)
B(dataset)
C(dataloader)
A--> B
B--> C
D(config)
E(Unet)
F(FeatureExtractor)
G(image)
H(noise)
C -->G
I(+)
G-->I
H-->I
J(noised image)
I-->J
J --输入--> E
D --> E
K(target image)
L(predicted noise)
E --> L
M(reconstructed image)
L -->M
K-->M
M --> F
N(image feature)
F-->N
训练耗资源
如果想要达到论文中的结果需要尺寸很大的模型,消费机显卡难以支撑
训练不稳定
官网承认这种训练并不稳定,使用他们的模型可以达到较好的效果,但是复现效果并不容易
推断耗资源
需要十几轮的加噪去噪步骤,执行效率难以保证
重构效果好
可以重构出和目标图像很接近的图,可以作为其他需求的技术储备
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/anomaly-detection/ddad/ddad-source-read/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。