在概率论和信息论中,两个随机变量的互信息(mutual Information,MI)度量了两个变量之间相互依赖的程度。。
对于两个随机变量,MI是一个随机变量由于已知另一个随机变量而减少的“信息量”(单位通常为比特)。互信息的概念与随机变量的熵紧密相关,熵是信息论中的基本概念,它量化的是随机变量中所包含的“信息量”。
MI不仅仅是度量实值随机变量和线性相关性(如相关系数),它更为通用。MI决定了随机变量 ${\displaystyle {\displaystyle (X,Y)}}$的联合分布与
${\displaystyle X}$ 和 ${\displaystyle Y}$ 的边缘分布的乘积之间的差异。MI是点互信息(Pointwise Mutual Information,PMI)的期望。克劳德·香农在他的论文A Mathematical Theory of Communication中定义并分析了这个度量,但是当时他并没有将其称为“互信息”。这个词后来由 罗伯特·法诺 创造。互信息也称为信息增益。
设随机变量$(X,Y)$是空间 $X×Y$ 中的一对随机变量。若他们的联合分布是$p(x,y)$,边缘分布分别是$p(x)$和$p(y)$,那么,它们之间的互信息可以定义为:
$$
I(X;Y)=D_{\mathrm{KL}}(p(x,y)|p(x)\otimes p(y))
$$
其中,${\displaystyle {\displaystyle D_{\mathrm {KL} }}}$ 为KL散度(Kullback–Leibler divergence)。
注意,根据KL散度的性质,若联合分布${\displaystyle p(x,y)}$ 等于边缘分布${\displaystyle p(x)}$和${\displaystyle p(y)}$的乘积,则 ${\displaystyle I(X;Y)=0}$,即当 $X$和 $Y$ 相互独立的时候,观测到 $Y$对于我们预测X没有任何帮助,此时他们的互信息为0。
离散随机变量 X 和 Y 的互信息可以计算为:
$$
{\displaystyle I(X;Y)=\sum _{y\in Y}\sum _{x\in X}p(x,y)\log {\left({\frac {p(x,y)}{p(x),p(y)}}\right)},,!}
$$
其中 p(x, y) 是 X 和 Y 的联合概率质量函数,而 ${\displaystyle p(x)} $ 和 ${\displaystyle p(y)}$ 分别是 $X$ 和 $Y$ 的边缘概率质量函数。
在连续随机变量的情形下,求和被替换成了二重定积分:
$$
{\displaystyle I(X;Y)=\int _{Y}\int _{X}p(x,y)\log {\left({\frac {p(x,y)}{p(x),p(y)}}\right)};dx,dy,}
$$
其中 $p(x, y)$ 当前是 X 和 Y 的联合概率密度函数,而 ${\displaystyle p(x)}$ 和 ${\displaystyle p(y)}$ 分别是 $X$ 和 $Y $ 的边缘概率密度函数。
如果对数以 2 为基底,互信息的单位是 bit。
对任意随机变量 $X,Y$ ,其互信息 $I(X,Y)$ 满足:
对称性:
$$
{\displaystyle I(X;Y)=I(Y;X)}
$$
半正定:
$$
{\displaystyle I(X;Y)\geq 0}
$$
当且仅当 $X,Y$ 独立时:
$$
{\displaystyle I(X;Y)= 0}
$$
平均互信息量不是从两个具体消息出发, 而是从随机变量X和Y的整体角度出发, 并在平均意义上观察问题, 所以平均互信息量不会出现负值。或者说从一个事件提取关于另一个事件的信息, 最坏的情况是0, 不会由于知道了一个事件,反而使另一个事件的不确定度增加。
$$
I(X;Y)≤H(X)
$$
$$
I(Y;X)≤H(Y)
$$
从一个事件提取关于另一个事件的信息量, 至多是另一个事件的熵那么多, 不会超过另一个事件自身所含的信息量。当 $X$ 和 $Y$ 是一一对应关系时: $I(X;Y)=H(X)$, 这时 $H(X|Y)=0$。从一个事件可以充分获得关于另一个事件的信息, 从平均意义上来说, 代表信源的信息量可全部通过信道。当X和Y相互独立时: $H(X|Y) =H(X)$, $I(Y;X)=0$。 从一个事件不能得到另一个事件的任何信息,这等效于信道中断的情况。
$$
I(X_{1},X_{2},\ldots X_{n};Y)=H(X_{1},X_{3},\ldots X_{n})-H(X_{1},X_{3},\ldots X_{n}|Y)
$$
如果 $U\to X\to Y\to V$ 构成马式链,则 $I(U;V)\leq I(X;Y)$。
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。
所以具体的解释就是: 互信息越小,两个来自不同事件空间的随机变量彼此之间的关联性越低; 互信息越高,关联性则越高 。
这证实了互信息的直观意义为: "因X而有Y事件"的熵( 基于已知随机变量的不确定性) 在"Y事件"的熵之中具有多少影响地位( “Y事件所具有的不确定性” 其中包含了多少 “Y|X事件所具有的不确性” ),意即"Y具有的不确定性"有多少程度是起因于X事件;
例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。(这种情形的一个非常特殊的情况是当 X 和 Y 为相同随机变量时。)
互信息是 X 和 Y 的联合分布相对于假定 X 和 Y 独立情况下的联合分布之间的内在依赖性。 于是互信息以下面方式度量依赖性:$I(X; Y) = 0$ 当且仅当 X 和 Y 为独立随机变量。从一个方向很容易看出:当 X 和 Y 独立时,$p(x,y) = p(x) p(y)$,因此:
$$
{\displaystyle \log {\left({\frac {p(x,y)}{p(x),p(y)}}\right)}=\log 1=0.,!}
$$
互信息又可以等价地表示成:
$$ {\displaystyle {\begin{aligned}I(X;Y)&{}=H(X)-H(X|Y)\\&{}=H(Y)-H(Y|X)\\&{}=H(X)+H(Y)-H(X,Y)\\&{}=H(X,Y)-H(X|Y)-H(Y|X)\end{aligned}}} $$
其中 ${\displaystyle \ H(X)}$ 和 ${\displaystyle \ H(Y)}$ 是边缘熵,$H(X|Y) $和 $H(Y|X)$ 是条件熵,而 $H(X,Y)$ 是 $X $ 和 $Y $ 的联合熵。注意到这组关系和并集、差集和交集的关系类似,于是用Venn 图表示
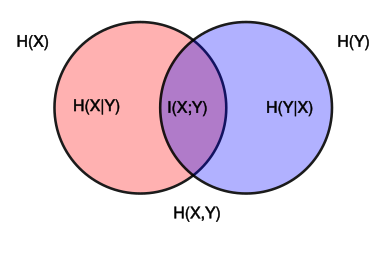
如果把熵 H(Y) 看作一个随机变量于不确定度的量度,那么 H(Y|X) 就是"在已知 X 事件后Y事件会发生"的不确定度。于是等式的右边第二行就可以读作“将Y事件的不确定度,减去基于X事件后Y事件因此发生的不确定度”。
注意到离散情形 H(X|X) = 0,于是 H(X) = I(X;X)。因此 I(X;X) ≥ I(X;Y),我们可以制定”一个变量至少包含其他任何变量可以提供的与它有关的信息“的基本原理。
互信息也可以表示为两个随机变量的边缘分布 X 和 Y 的乘积 $p(x) × p(y)$ 相对于随机变量的联合熵 $p(x,y)$ 的相对熵:
$$
{\displaystyle I(X;Y)=D_{\mathrm {KL} }(p(x,y)|p(x)p(y)).}
$$
此外,令 $p(x|y) = p(x, y) / p(y)$。则
$$ {\displaystyle {\begin{aligned}I(X;Y)&{}=\sum _{y}p(y)\sum _{x}p(x|y)\log _{2}{\frac {p(x|y)}{p(x)}}\\&{}=\sum _{y}p(y)\;D_{\mathrm {KL} }(p(x|y)\|p(x))\\&{}=\mathbb {E} _{Y}\{D_{\mathrm {KL} }(p(x|y)\|p(x))\}.\end{aligned}}} $$
注意到,这里相对熵涉及到仅对随机变量 X 积分,表达式 ${\displaystyle D_{\mathrm {KL} }(p(x|y)|p(x))}$ 现在以 Y 为变量。于是互信息也可以理解为相对熵 X 的单变量分布 $p(x)$ 相对于给定 Y 时 X 的条件分布 $p(x|y) $:分布 $p(x|y) $ 和 $p(x)$ 之间的平均差异越大,信息增益越大。
互信息与信息增益
一、两者描述的时空不同
信息增益: $Gain=H(X)-H(X/Y)$, 意义是系统分类后增加的信息量(研究同一系统的不同状态)
互信息:$I(X,Y)=H(X)-H(X/Y)=H(Y)-H(Y/X)$,意义就是 X 与 Y 之间对应关系的信息量(研究同一状态下系统中的两个子系统)
二、Y的含义不一样
增益里面Y是分类方式,互信息里面Y是事件
互信息里面的Y,用 $H(Y)$ 表示,可以通过统计测量概率,并用信息熵公式计算。
但是增益里面的Y,由于是一种分类方式,它的熵要是直接计算,信息论里面没有介绍。
三、两者之间的关系
信息增益是描述前后两种不同状态的信息熵变化,即确定性的增加量,分类本质就是将一个系统中各种元素之间的分类关系(X,Y,Z,…)确定下来。
四、总结
Gain是各元素之间的人为定义的关系信息,I只是两两之间客观关系信息,当然I也能够扩展,通过扩展可以计算得到gain,不论是I还是gain他们都是关系信息,而非事件信息。信息增益是互信息的无偏估计,所以在决策树的训练过程中, 两者是等价的。
文章链接:
https://www.zywvvd.com/notes/study/information-theory/mutual-info/mutual-info/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。