深度学习实现异常检测时常用重构的方法,但是过程中会隐含地学习到对检测不利的内容,OCGAN 尝试克服该问题。
当前的方法认为latent representation包含这in-class样本的信息,从而对于in-class样本,其reconstruction的效果好而out-of-class样本的则差,进而能达到检测异常的目的。
然而,这种假设并不总是有效的,该文章发现了此类现场并尝试解决。
论文: OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representations
对于传统的 AE 模型,以手写数字辨识为例,对于简单的数字(如0,1),模型可以获得很高的准确率;但对于较为复杂的数字(如8),其检测的准确率会有所折扣。这是因为8的latent representation不仅仅包含了其自身的信息,还包含了其他数字(例如1,3,6,7)的信息。

因此哪怕仅用 8 训练的模型也可以重构一些其他数字
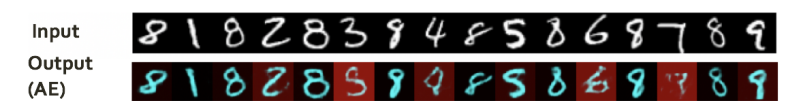
论文的方案是使用一个denoising auto-encoder来学出in-class的latent representation。论文的提出的方法可以直接限制latent space,让其只能表示in-class的信息。该方法包括一下几个部分:
OCGAN由4部分组成:
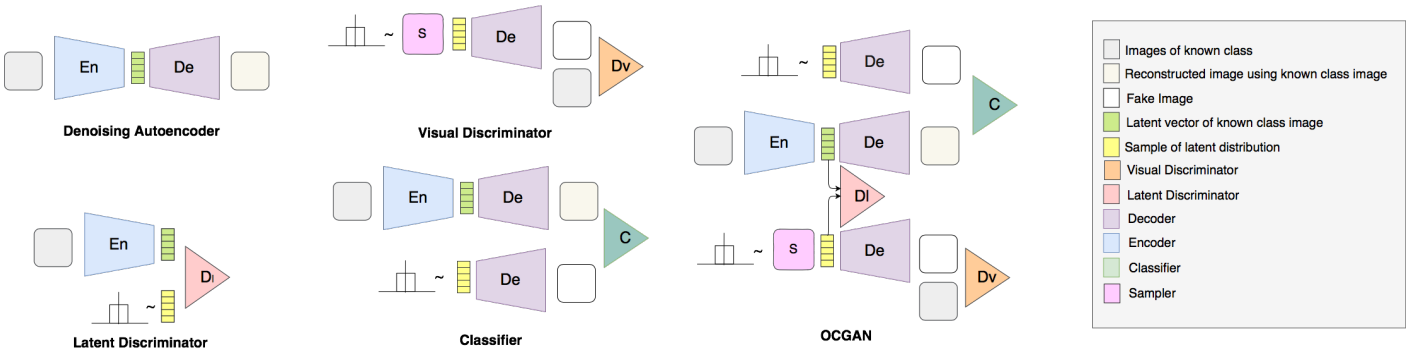
与普通的 auto-encoder 相比,denoising 版本更不容易 overfitting,模型的泛化能力更强。
同时,通过 $tanh()$ 函数把 latent space 限制在了 $(-1, 1)^d$(d 是 latent space 的维度)。
这里的噪声采用的是零均值高斯白噪声,并取方差为2。那么对于输入图片x和噪音n,Loss的计算式为:
$$
l_{\mathrm{MSE}}=||x-\mathrm{De}(\mathrm{En}(x+n))||_2^2
$$
我们期望 latent space上的任何一个样本透过生成器之后都能生成in-class样本,而不是仅仅局限于某一片区域。于是我们要限制latent space的分布是均匀的。
设计该判别器的目的就是为了让latent space接近均匀分布。
Discriminator有两种输入:
判别器Loss如下
$$ \begin{array}{rl}l_{\mathbf{latent}}=-(\mathbb{E}_{s\sim\mathbb{U}(-1,1)}[\log D_l(s)]+\mathbb{E}_{x\sim p_x}[\log(1-D_l(\operatorname{En}(x+n)))])\end{array} $$
这里 $P_x$是 in-class 样本的分布。
Discriminator 要让 $D(s)$ 和 $D(En(x+n))$ 的差距变大,于是期待 $D(s)$ 的值大而 $D(En(x+n))$ 的值小。
我们让它和auto-encoder的网络一起训练:
$$
\max_{\mathbf{En}}\min_{D_l}l_{\mathbf{latent}}
$$
这里的max是指我们期待让encoder产生的 latent space分布接近均匀分布,从而骗过discriminator(即让discriminator的loss变大)。
我们希望从latent space上随机的sample,经过generator(decoder)之后,其重建图像能尽可能像真实的图片。
该 discriminator 的任务就是区分 real images 和 fake images, 其Loss如下:
$$ \begin{array}{rcl}l_\mathrm{visual}=-(\mathbb{E}_{s\sim\mathbb{U}(-1,1)}[\log D_v(\mathrm{De}(s))]+\mathbb{E}_{x\sim p_l}[\log(1-D_v(x))])\end{array} $$
这里x是real images,s是latent space上的一个随机样本。
与latent discriminator类似,我们让它和atuto-encoder网络一起训练:
$$
\max_\text{Dе}{ \min _ { D _ v }}l_{\text{visual}}
$$
同样的,我们希望decoder生成的图像和真实图像越接近越好,从而骗过discriminator(即让其loss变大)。
由于我们不可能把latent space上的点都采样一遍并丢进网络训练,很有可能latent space上存在我们训练时没有采样到的区域,在它们上的latent representation输入到decoder中并不能得到in-class的结果。论文中把这些不好的图片成为informative-negative samples。
或许降低latent space的维度我们有可能把l它遍历一遍,但这样又会导致latent representation包含的信息不够。
论文中提出的方法是主动找到这些不满足条件的区域,并把上面的samples丢到网络里训练,从而让该区域符合条件。对于generator,其输入是从该区域上产生的sample,而对于两个discriminators,其输入依然是latent space上的随机sample。
为了找到不符合要求的样本,我们需要一个classifier。我们首先从latent space上随机得到一堆samples,然后过一遍generator生成图片。classifier的任务就是评估这些图片的质量并根据其Loss来优化latent space。
个人认为是为了补足理论上空间分布过大采取的补救措施
Classifier要区分两类:
它采用的cross entropy loss。注意其训练和generator和discriminators是分开的。
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/anomaly-detection/ocgan/ocgan/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。