SVM 在实际应用时往往会用到核函数,可以用很小的计算代价达到提升特征维度的效果,本文记录相关内容。
$$
\mathrm{K}(x, z)=\Phi(x) \bullet \Phi(z)
$$
则称函数 $K(x,z)$ 为核函数 (kernel function), $\Phi(x)$ 为映射函数,$\Phi(x) \bullet \Phi(z)$ 为 $x,y$ 映射到特征空间上的内积。
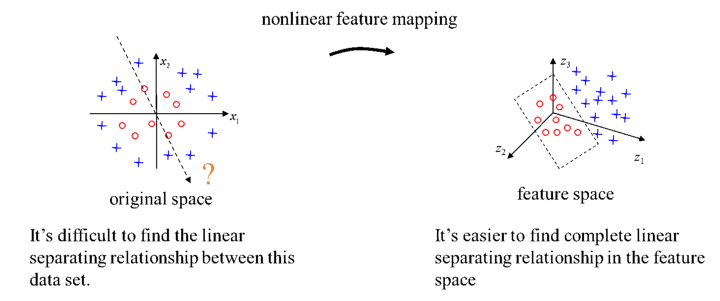
SVM 的求解和推断过程均可以表示为数据的内积运算,因此核函数替换内积后完全不影响结果,但是会显著提升高维特征的 SVM 运算速度。
$$ \begin{array}{c} L(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum_{i=1}^{n} \alpha_{i}\left(y_{i}\left(w^{T} \cdot \Phi\left(x_{i}\right)+b\right)-1\right) \\ s.t. y_{i}\left(w^{T} \cdot \Phi\left(x_{i}\right)+b\right) \geq 1 \end{array} $$
$$ \begin{array}{l} \frac{\partial L}{\partial w}=0 \Rightarrow w=\sum_{i=1}^{n} \alpha_{i} y_{i} \Phi\left(x_{n}\right) \\ \frac{\partial L}{\partial b}=0 \Rightarrow 0=\sum_{i=1}^{n} \alpha_{i} y_{i} \end{array} $$
$$ \begin{array}{l} \min _{\alpha} \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\Phi\left(x_{i}\right) \cdot \Phi\left(x_{j}\right)\right)-\sum_{i=1}^{n} \alpha_{i}\\ s.t. \sum_{i=1}^{n} \alpha_{i} y_{i}=0 , \alpha_{i} \geq 0 \end{array} $$
$$
w^{T} x+b=0
$$
$$
f(x)=\operatorname{sign}\left(w^{T} x+b\right)
$$
$$
w=\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i}
$$
$$
b=y_j-w^Tx_j
$$
$$ \begin{aligned} f(x) &=w^{T} x+b \\ &=(\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i})^{T} x+y_j-(\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i})^{T}x_j\\ &=\sum_{i=1}^{n} \alpha_{i} y_{i}\left\langle x_{i}, x\right\rangle+y_j-\sum_{i=1}^{n} \alpha_{i} y_{i} \langle x_{i},x_j \rangle \end{aligned} $$
$$
f(x)=\sum_{i=1}^{n} \alpha_{i} y_{i} K(x_{i},x)+y_j-\sum_{i=1}^{n} \alpha_{i} y_{i} K(x_{i},x_j)
$$
我们知道了什么是核函数,看到了核函数在 SVM 中的巧妙运用,也就是只要定义好核函数,求解推断一切都可以包办,但什么样的函数可以成为核函数呢。
$$
K(x,y)=K(y,x)
$$
$$ \begin{array}{c} M &=&\left[\begin{array}{cccc}\boldsymbol{\Phi}\left(\mathbf{x}_{1}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{1}\right) & \boldsymbol{\Phi}\left(\mathbf{x}_{1}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{2}\right) & \ldots & \boldsymbol{\Phi}\left(\mathbf{x}_{1}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{N}\right) \\ \boldsymbol{\Phi}\left(\mathbf{x}_{2}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{1}\right) & \boldsymbol{\Phi}\left(\mathbf{x}_{2}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{2}\right) & \ldots & \boldsymbol{\Phi}\left(\mathbf{x}_{2}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{N}\right) \\ \Phi\left(\mathbf{x}_{N}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{1}\right) & \boldsymbol{\Phi}\left(\mathbf{x}_{N}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{2}\right) & \ldots & \boldsymbol{\Phi}\left(\mathbf{x}_{N}\right)^{T} \boldsymbol{\Phi}\left(\mathbf{x}_{N}\right)\end{array}\right] \\ &=&\left[\begin{array}{lllll}\mathbf{z}_{1} & \mathbf{z}_{2} & \ldots & \mathbf{z}_{N}\end{array}\right]^{T}\left[\begin{array}{llll}\mathbf{z}_{1} & \mathbf{z}_{2} & \ldots & \mathbf{z}_{N}\end{array}\right] \end{array} $$
$$
K(x,y)=\langle x,y\rangle
$$
$$
K(x,y)=(\langle x,y\rangle+c)^d
$$
$$ K(x, y)=e^{-\frac{\|x-y\|^{2}}{2 \sigma^{2}}} $$
文章链接:
https://www.zywvvd.com/notes/study/machine-learning/about-svm/svm-kernel/svm-kernel/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。