I have a new working paper out (with Whitney Afonso and Denvil Duncan) that does something I haven’t seen before in a research paper: a Model Context Protocol (MCP) that provides a structured way of interacting with the paper via a Large Language Model. I’m going to show you first what I did, and then tell you what I think the opportunities are available at present for scientific research papers.
Without specifics, our paper introduces a pair of randomized treatments (Priority and Performance) to elicit people’s stated preferences. We do all the normal things of a research paper: collect data about the survey respondents, show various tables, figures, and regression results. For regression results, we show you our “preferred” main specifications and selected robustness checks.
What is new is that I’ve built a MCP to allow users to interact with the data using natural language to run other regressions we either didn’t show in the paper or didn’t even think of. It also allows you to create new plots of the data, subset it for other balancing tests, and a bunch of other things (see the model notes for more).
To get a sense of this, suppose you go to the paper’s Github, download the data and server files, and follow the steps to connect the MCP to your favorite LLM. The MCP is built knowing what we have done in the paper, and with the flexibility to do new things.
You can now ask your LLM questions about the data and code. For example, “What’s the mean budget allocation by treatment arm in the practitioners sample?”
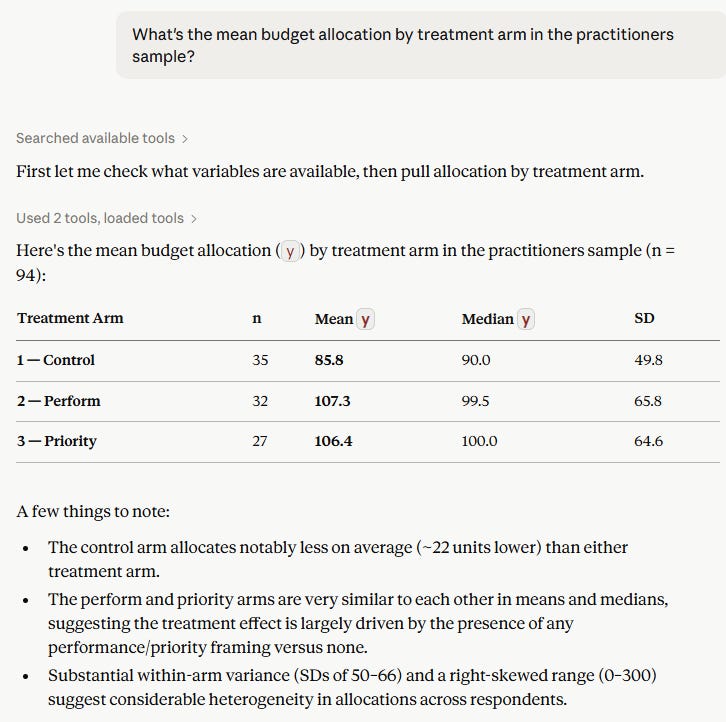
Here is a new regression specification that we did not think of until after I built the MCP, what if we interacted one of the treatment variables with the dummy variable on respondent sex? Here:
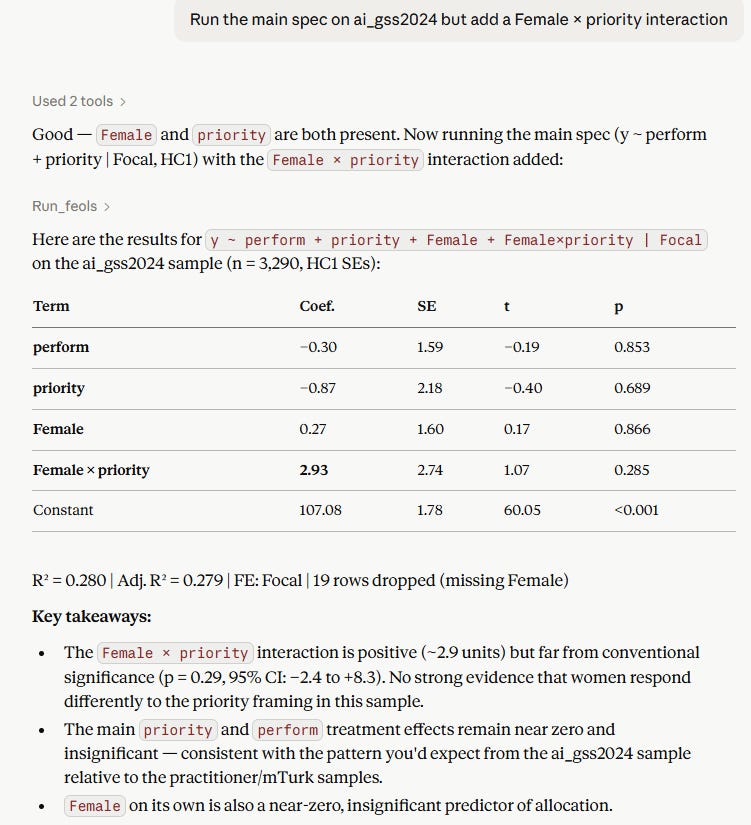
Now you know, and so do I.
Good research papers do a lot of important work. A paper states the research question. It forces the author into a coherent argument. It explains the institutional context, identification strategy, data, results, and limitations. It gives readers a canonical version of what the author believes has been shown, and what questions are reasonable to ask of the evidence.
Tyler Cowen recently asked whether AI will kill the research paper. Instead of reading a fixed PDF, a reader might press a button and update the paper with new data, rerun it under five alternative specifications, or turn it into a “meta-paper” that answers nearly any question about the subject.
I think something like that may eventually happen, but I worry it loses advantages offered by the research paper. Would literatures where motivated reasoning is strong (e.g. maybe minimum wages?) really improve here? I don’t know. In any case, a more immediate opportunity feasible right now is building a MCP as I depicted above. I think it offers efficient opportunities in replication and investigation, while retaining many of the advantages of the research paper design.
Empirical papers sit on top of a large apparatus of raw data, cleaned data, code, model choices, robustness checks, judgment calls, false starts, and dozens or hundreds of alternative specifications that never make it into the published tables.
Even when authors post replication packages, using them usually requires a reader to know the programming language, have compatible software and version control, understand the directory structure, install dependencies, decode the author’s conventions, and infer how the published tables relate to the files.
That is an interface problem: there are high costs to engaging with the research paper.
A MCP is an open standard that allows AI applications to connect to external data sources, tools, and workflows. The official MCP documentation describes it as something like a USB-C port for AI applications: a standardized way for an AI assistant to communicate with databases, files, APIs, and specialized tools rather than relying only on whatever is pasted into a chat window.
For research papers, this means the paper can come with a companion server. The server exposes the underlying data and analysis pipeline in a structured way. The reader does not need to learn the author’s coding conventions before asking a substantive question. The reader asks in ordinary language, and the AI assistant translates that question into verified analytical operations.
In my new paper, the reader can ask via their LLM “Replicate Table 1 for the mTurk sample.”
Or:
“Does the framing effect differ by respondent gender?”
The AI assistant then routes the request to the appropriate tool in the MCP server, executes the analysis, and returns the result. The local server we have built already exposes more than twenty tools across data discovery, summary statistics, balance tests, fixed-effects regressions, and publication-quality figures.
This is not the same as asking ChatGPT to “analyze the paper.” That is too loose or burn tokens predicting what algorithm for regression should be used based on your request. The point of an MCP is that the model is not improvising empirical analysis from memory or from a vague summary of the study. It is calling structured tools that the author has built, documented, and constrained.
The best near-term version of AI-assisted research is a carefully designed research environment that lets readers ask better questions of the actual replication materials. This does not eliminate the need for traditional research skill.
MCP’s create new demands of researchers that complement the existing traditional skills. To build the server means anticipating the appropriate questions readers might ask and choosing the right level of flexibility. Too little flexibility and the MCP is just a prettier replication archive. Too much flexibility and we are back to specification fishing with a friendlier user interface. MCP lets readers ask those questions without first figuring out why “if Lebron==0” (to borrow from our paper example) is an important restriction on the main results.
But the technical reviewer also gains something. If she wants to know whether I used “feols”, “reghdfe”, “lm”, or some custom function buried in a scripts folder, she can ask directly. If I have built the capability into the server, she can inspect alternative model implementations I never directly considered and see whether they matter.
This also changes what authors need to become good at. In the existing replication model, the author’s job is mostly to post enough code that a determined specialist can reproduce the paper. In the MCP model, the author has to anticipate genres of reader questions: descriptive statistics, figures, causal assumptions, robustness checks, subgroup analyses, and plausible extensions. Which brings me to the reviewer process….
Anyone who has published empirical work knows the current system.
A referee reads the paper and asks for ten thousand minor twists and clarifying exercises: add this control, drop that subgroup, cluster differently, try this alternative algorithm, show this balance test, redefine the outcome, move this figure, add that appendix table, yada yada yada.
Some of these requests are genuinely insightful. Some uncover fragility. Some help the referee understand what the author actually did. Others are make-work dressed up as rigor.
But all of them move through an absurdly slow loop: reviewer asks, author reruns, author writes a response, editor waits, reviewer rereads, and the process repeats. This takes months. Sometimes it takes years.
MCP-literate authors and reviewers could improve that process. The author provides the paper and the MCP. The reviewer, instead of asking the author to run every minor variation, connects to the paper’s MCP server and explores many of these questions directly.
If the reviewer wants to know whether the result is sensitive to a different control set, the server can allow that within a pre-specified menu. If the reviewer wants to inspect subgroup patterns, the server can generate them if the author has prepared that functionality. The reviewer should be able to get fast feedback on the petty queries without a round trip through the editorial process, and focus their feedback on whether their queries can get answers from the server.
This matters because AI is already creating a likely imbalance in academic publishing: author productivity outpacing reviewer productivity.
MCP-style replication servers are probably a partial, not full, offset to that problem. They let reviewers answer more of their own minor questions immediately, and reserve the editorial process for the questions that actually require judgment.
The immediate future I’m imagining is that the research paper remains the canonical argument. The replication package is the canonical archive. The MCP server becomes the canonical interface.
The printed article once solved a distribution problem: how to circulate an argument. The PDF solved a storage and access problem: how to make that argument easy to obtain. The replication archive solved a transparency problem: how to let others inspect the machinery behind the argument.
The MCP can solve an interface problem we didn’t even previously recognize. A research paper can not only inform on what the authors found, but also let them ask disciplined questions around the evidence presented.
The MCP in the budgeting paper is a first, hopefully rudimentary effort. It is a local server: you download it from Github (data and code) and follow the instructions to connect it to your preferred LLM. I have never had this go smoothly across several different computers in testing, but luckily LLMs are great at troubleshooting themselves.
The next version I’m working on will (hopefully) be a much simpler url link that you could connect in your LLM without downloading data or messing with your .settings folder. I have a tiny grant proposal out at IU for a summer project to set up a dedicated campus server to pilot letting people stash their MCPs for replications. This would hopefully help us develop some best practices, and serve as a proof of concept for a larger MCP repository for scientific research. Stay tuned.
My essays may be republished online or in print under Creative Commons license CC BY-NC-ND 4.0. I ask that you edit only for style or to shorten, provide proper attribution and link to this substack.