On a SaaS spreadsheet, that looks irrational. To OpenAI, Google, Microsoft, Amazon, NVIDIA, and frontier investors, the logic is simpler: own scarce inputs before revenue makes them obvious.
Three inputs keep showing up: proprietary data, models, and people who turn both into leverage. Buyers value famous people fastest and rights-cleared data slowest. That gap is the trade.
Safe Superintelligence is the cleanest case: $1 billion raised at a reported $5 billion valuation in September 2024, then another reported $2 billion at $32 billion in April 2025. It was still pre-product, but it had Ilya Sutskever, co-founder of OpenAI.
OpenAI’s io Products deal priced product taste before device sales. In May 2025, TechCrunch reported that OpenAI agreed to buy Jony Ive’s company for nearly $6.5 billion before consumer hardware shipped. It bought design judgment, recruiting pull, and the iPhone’s defining designer.
AMI Labs priced research authority before product. In March 2026, TechCrunch reported that Yann LeCun’s new company raised a $1.03 billion seed round at a $3.5 billion valuation. LeCun’s credential made diligence legible: Turing Award winner, former Meta chief AI scientist, and central researcher.
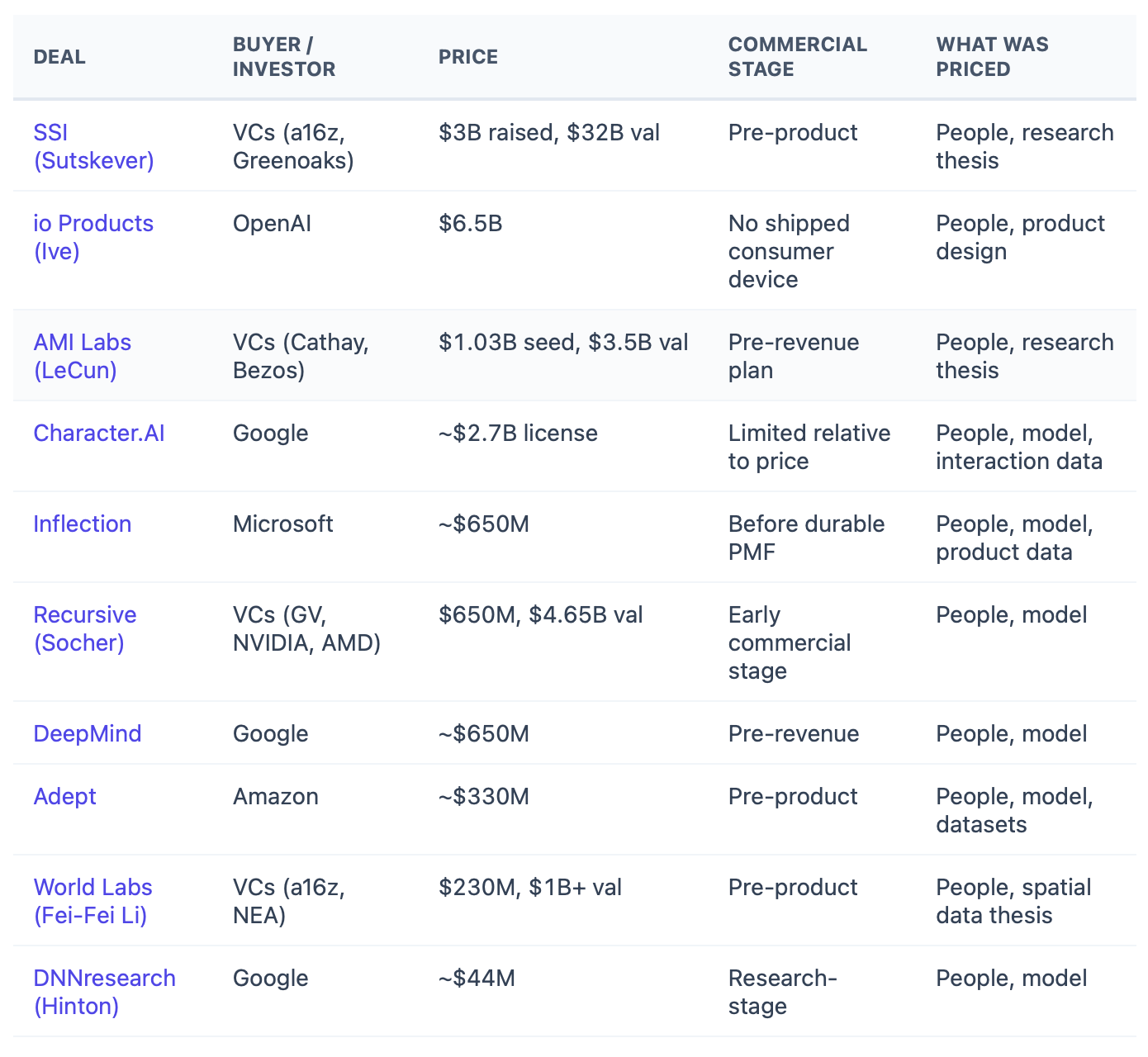
Across these ten cases, disclosed capital raised, acquisition consideration, and reported licensing fees exceed $15 billion. Headline valuations push the implied value much higher. Revenue was usually not the anchor.
The legal forms differ: funding rounds, acquisitions, licensing deals, and hiring-heavy structures. The common move is simple: buyers and investors paid before old-style revenue proof could do the work.
Buyer type changes what gets priced. Strategic buyers pay for people, model rights, product acceleration, and missing capability. Investors pay for recruiting power, compute access, and credible research direction. Data becomes explicit value when it is rare, rights-cleared, strategically missing, and hard for a model builder to reproduce.
The transactions resolve to three assets: data, models, and people. Revenue matters later. At deal time, it was often not the valuation anchor.

Every case in the table is a bet on at least one asset. Buyers pay for famous people faster than they inspect the data that makes those people productive.
The fame premium has a rational core. Elite founders attract talent, capital, compute access, and buyer attention. But exclusive domain data can be harder to replace.
There is a Chinese saying: 巧妇难为无米之炊. Even the cleverest cook cannot make a meal without rice.
The metaphor works because talent transforms data but cannot substitute for it. The researcher is the chef. The data is the rice. Investors still pay for the chef before they pay for the rice.
The pricing gap is visible in public data deals. Reddit’s AI licensing across Google and OpenAI is roughly $130 million a year. News Corp’s journalism archive was reportedly priced at $250 million over five years. Those are large checks for media companies and small next to a $32 billion pre-product valuation for SSI.
Infrastructure deals point to the same bottleneck. Scale AI was valued at $29 billion with roughly $2 billion of ARR, treating labeled data operations as core infrastructure. Salesforce paid about $8 billion for Informatica. IBM paid about $11 billion for Confluent. Buyers are paying to organize, govern, move, and stream data.
Enterprise deployment evidence is consistent. The MIT NANDA GenAI Divide reportfound that about 95% of enterprise AI pilots failed to produce measurable impact, with failures concentrated around missing proprietary context, workflow integration, and tools that did not learn from enterprise data. Generic models do not know a company’s exceptions until they see them.
The talent bottleneck is real, but the broad talent pool is expanding. Roughly 5,900 machine learning PhDs graduate every year. For many open models, fine-tuning can now run on a single consumer GPU. There are more competent chefs every year. Reddit’s historical conversation archive exists once.
Capital still flows through narrow channels. Crunchbase found that startups with Stanford, Harvard, and MIT alumni as founders drew more than 30% of the funding rounds it tracked among U.S. university-affiliated founders. In the AI Power Map, 77 of 420 influential people in core AI are Stanford-affiliated. The talent pipeline is wide. The funding pipeline is narrow.
The best asset is a talented founder with exclusive access to rare data. The second-best asset may be the data itself. Outside frontier research, the sharper question is not “who is the smartest person?” It is “who has the rice?”
A file labeled proprietary data is often worthless. It can be stale, duplicative, legally encumbered, poorly labeled, or impossible to integrate. Ownership alone does not create an AI asset.
Data value depends on time, rights, and context. Last year’s web crawl ages. A one-time survey depreciates when collected. Rights-cleared longitudinal clinical records can appreciate as outcomes appear. Fifteen years of logistics exception data can beat a synthetic substitute because the edge cases happened in the real world.
Valuable datasets have depth, freshness, labeled outcomes, real edge cases, and legal control that a model builder cannot cheaply reproduce. Evaluating them requires domain expertise. AI buyers need technical asset evaluators, not another DCF analyst with a new multiple.
The credential gap suppresses data pricing. Investors can underwrite Sutskever’s training approach or LeCun’s research thesis through the name. A less famous founder with strong domain data has to prove what the famous founder can assert. That asymmetry helps explain why data-rich companies without elite credentials remain underpriced.

A rush creates more than one way to build a fortune. In 1849, tens of thousands of prospectors flooded California to dig for gold. The gold was real. Some miners found it and became rich. Most did not.
Some durable California fortunes came from the supply business around the rush. Levi Strauss sold denim. Sam Brannan sold pickaxes. Leland Stanford sold provisions, then used the profits to build a railroad and a university. These businesses made the gold rush function.
AI has a similar shape. Famous founders can create extraordinary value. A Turing Award winner, a Transformer author, or a frontier-lab operator can deserve the premium buyers assign. But the visible gold field is crowded and credentialed. Most founders lack those credentials, and most investors cannot win when Google, Microsoft, OpenAI, NVIDIA, and the top venture firms are already bidding.
The overlooked claims are in the missing middle: clinician behavior inside healthcare workflow software, routing exceptions inside logistics platforms, structured decision data inside vertical SaaS, and sensor histories inside industrial software. These companies are not worthless because they lack famous founders, and not automatically worth $100 million because they have ARR. Their value sits in an asset class buyers still struggle to inspect, package, and transact.
The supply business around AI is enormous: compounding proprietary data, usable data infrastructure, diligence standards, advisory relationships, and eventually a marketplace that routes scarce assets efficiently. Data is not a shovel because people are the gold. Both people and data are valuable. A rush needs miners, claims, tools, roads, stores, banks, and trusted intermediaries.
In AI, the person who helps a data-rich company find the buyer that needs its workflow data is not selling supplies at the edge of the action. They reduce search costs, make the asset legible, and move a scarce input to the company that can turn it into a product. The roads around the rush can be just as valuable and far less crowded.
AI data and model transactions now have the three conditions that usually precede a marketplace: scarce assets, motivated buyers, and high search costs. The assets are proprietary datasets, trained models, evaluation harnesses, labeling pipelines, deployment telemetry, and specialized ML teams. The buyers are frontier labs, enterprises, and large technology companies.
Existing routes miss the asset class. Data marketplaces lack company context. Startup listing sites serve small SaaS exits. Bankers prefer banker clients. Talent raids work for names every lab knows. None of these channels is built for a company whose core value is a proprietary dataset, a fine-tuned model, or a specialized ML team inside a narrow domain.
The next platform will look less like a startup listing site and more like an MLS for AI assets. It would let holders package provenance, rights, privacy limits, schema quality, freshness, benchmarks, integration difficulty, and buyer fit. Buyers could search by strategic need: specialty care records, logistics exceptions, or robotics training data.
The missing product is trust infrastructure. Buyers do not need more pitch decks claiming “proprietary data.” They need diligence standards, provenance checks, data rooms built for model assets, buyer qualification, and valuation methods that treat data, models, and people as distinct assets.
The valuable version is not a public auction board. It is a confidential network: verified asset profiles, qualified buyers, controlled disclosure, and technical diligence before names or data rooms are exposed. Google, Microsoft, and OpenAI will not shop openly for strategic data. They may work through a trusted intermediary that can match need to asset without exposing either side too early.
The old M&A skill set is necessary but incomplete. Traditional advisors can structure a process, run diligence, negotiate terms, and close. Many cannot evaluate a training dataset, test whether a model is defensible, or judge whether a team can ship frontier-grade systems. They fall back to revenue multiples. Not because revenue is right. Because revenue is legible.
The new dealmaker combines technical judgment, buyer knowledge, and commercial fluency. The ML lead knows which workflow data is rare. The researcher knows which team is real. The product operator knows where a buyer’s AI roadmap has a missing piece. The role does not require a broker license or banking pedigree. It requires domain knowledge, relationships, and the ability to see what traditional finance misses.
The transaction layer may be a platform, a technical advisory firm, a data room company, a bank, a cloud marketplace, or a confidential network without a name. The valuable version will make rare assets visible without making them public. The first nine-figure AI transactions went to names everyone already knew. The next ones may come from assets only a few people can evaluate: clinical workflow histories, logistics exceptions, procurement trails, robotics video, and domain models with real deployment data. The person who can verify the rice, find the buyer, and structure the deal is not standing outside the gold rush. They are building the place where the next claims get priced.
This essay draws from Chapter 5 (The Capital Network) of The AI Power Map, a free interactive network map and 70,000-word companion book tracing 420 people and 1,700+ public relationships across the AI industry. The strategic transactions discussed above draw from the book’s verified acquisition dataset of 121 deals across 38 corporate buyers; the funding rounds are included here as current-market comparables.