你有没有遇到过这种情况:一个文件在浏览器里点击就能下载,但把链接丢到下载工具、aria2、wget 或 curl 里就 403 了?
最近想在 NHK 网站上下载一批 PDF,丢给 aria2 直接被拒,加了 User-Agent 也不行。但浏览器打开链接,秒下。
原因很简单:浏览器发请求时会自动带上 Cookie、User-Agent、Referer 等一堆 Headers,而外部下载器发的是"裸请求"。现在越来越多的网站(尤其是需要登录的站点)会校验这些信息,裸请求直接被拦。

现有的方案都不太好用
我试了几种常见的解决办法:
给 aria2 手动加 Headers——理论上可以,但需要从浏览器开发者工具里一个个复制 Cookie、UA、Referer,遇到带 token 的链接还会过期,操作很繁琐。
浏览器转发扩展(比如把下载任务从浏览器发到 aria2 RPC)——这些扩展能转发 Headers,但只能拦截你在浏览器里点击的下载,不能批量粘贴一堆 URL 进去。
市面上的批量下载扩展——看了一圈,要么收费,要么权限要一大堆,要么下载时并不走浏览器原生通道——又绕回了丢 Cookie 的老问题,要么项目早就没人维护了。
回到问题本质
想明白一件事:既然浏览器下载没问题,那就让浏览器自己来下载。
Chrome 允许扩展调用浏览器自身的下载能力,效果等同于你在地址栏输入链接按回车——Cookie、UA、Referer 全部自动携带,不需要你手动配置任何东西。
基于这个思路,我做了 Native Batch Downloader。
怎么用
- 点击工具栏图标,打开弹窗
- 粘贴 URL(一行一个)
- 设置并发数和下载间隔
- 点"开始下载"
就这么简单。下载进度、成功/失败统计、实时日志都在弹窗里显示。
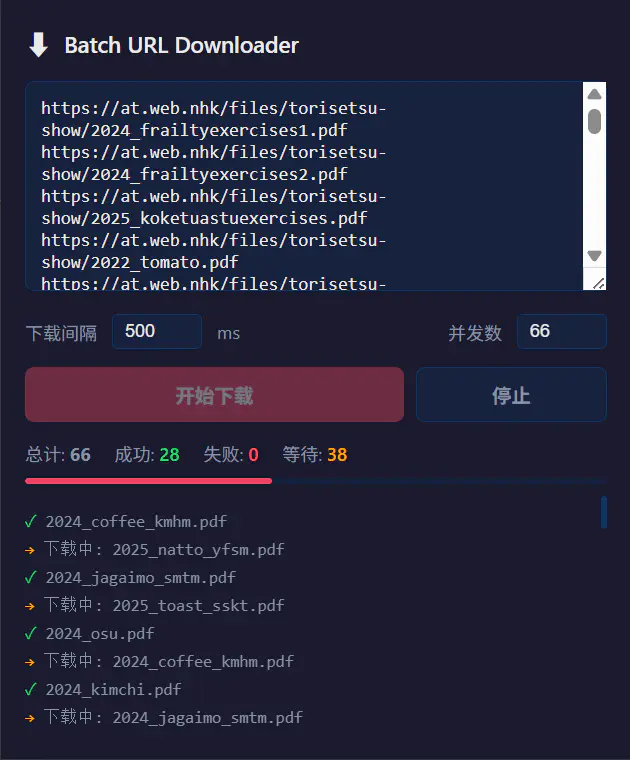
实测批量下载 66 个 PDF 文件(最大 120MB),全部正常完成。
几个你可能关心的问题
支持什么文件类型? 不限。PDF、图片、视频、压缩包、可执行文件,只要 URL 是直链就行。
并发数多少合适? 默认 10。但浏览器对同一个网站有并发连接数限制,所以下载同一个站点的文件时,设再高也不会更快。跨站下载时高并发才有意义。
需要登录的网站能用吗? 能,只要你在浏览器里已经登录了。扩展走的就是浏览器自己的请求通道,登录态天然携带。
URL 必须是直链吗? 是的。如果一个网站是点按钮后 JS 动态生成临时下载地址的(比如网盘的"点击下载"),你需要想办法拿到实际的文件 URL。这个扩展不负责解析页面。
权限要了哪些? 只需要"下载"权限,不会读取你的浏览记录、网页内容或其他隐私数据。无第三方依赖,支持 18 种语言,代码完全开源可审查。
适用场景
- 批量下载需要登录态的资源(论文库、内部系统、会员站点)
- 批量下载反爬站点的文件(检查 UA/Referer 的站点)
- 从文本列表批量下载任意直链文件
- 替代 aria2 在带认证场景下的批量下载需求
不适用的场景
- 需要从网页上自动提取链接(这个扩展只接受你手动提供的 URL 列表)
- 网盘等需要点击按钮才能获取真实下载地址的场景
- 需要断点续传的超大文件(chrome.downloads 本身支持续传,但扩展层面没做额外处理)
安装地址:Chrome Web Store
开源地址:https://github.com/rockbenben/native-batch-downloader
MIT 协议,有需要的直接用。问题和建议欢迎提 issue。