Andy团队出的,也算是非常经典的作品
Because disk accesses are no longer the principle bottleneck in such systems, the focus in designing query execution engines has shifted to optimizing CPU performance.
这个判断奠定了未来(哪怕是现在2025年)数据库开发的基调
文章测试使用的数据库为Peloton(已于2019年放弃)
Introduction
Given this trend, we anticipate that most future OLAP applications will use in-memory DBMSs. Because in-memory DBMSs are designed such that the bulk of the working dataset fits in memory,
就这么说吧,大量使用Memory是本世纪20年代后的数据库研究的主要特征😋(吐槽下,这点内存跟LLM比还是少很多的好吧)
A key challenge for both software prefetching and SIMD vectorization is that neither technique works well in a tuple-at-a-time model (i.e., Volcano [19]).
SIMD也是,数据库/大数据处理平台也就是从那时起开始重视这一块(要知道,SIMD最早适用于音视频处理加速的,但数据库大规模使用列存后基本都会用SIMD)
Until now, no DBMS has taken a holistic view on how to use all of the above techniques effectively together throughout the entire query plan.
这可太对了
Our experimental results show that ROF improves the performance of the DBMS for OLAP queries by up to 2.2X
两倍么,那还行
Background
To illustrate this approach, consider the plan shown in Fig. 2a for the TPC-H query in Fig. 1 annotated with its three pipelines P1, P2, and P3.

Figure1是TPC-H 19(感兴趣的朋友可以手写下代码,我用LLM写的几个版本在我的开发板上运行,要么运行超时,要么Out-Of-Memory被系统强行kill掉),他这里拆了三条流水线,有意思
The DBMS’s optimizer generates one loop for every pipeline. Each loop iteration begins by reading a tuple from either a base table or an intermediate data structure (e.g., a hash-table used for a join).
这里使用的还是传统的火山模型
Combining the execution of multiple operators within a single loop iteration is known as operator fusion. Fusing together pipeline operators in this manner obviates the need to materialize tuple data to memory, and can instead pass tuple attributes through CPU registers, or the stack which will likely be in the cache.
可以在内存中实现算子融合
Returning to our example, Fig. 2c shows the colored blocks of code that correspond to the identically-colored pipeline in the query execution plan in Fig. 2a. The first block of code (P1) performs a scan on the Part table and the build-phase of the join. The second block (P2) scans the LineItem table, performs the join with Part, and computes the aggregate function.
Looks nice
A vectorized engine relies on the compiler to automatically detect loops that can be converted to SIMD, but modern compilers are only able to optimize simple loops involving computation over numeric columns.
这里在说自动向量化效果不行(但DuckDB后面采取的,就是向量自动化的这一种方式)
Fig. 3 shows pseudo-code for TPC-H Q19 using the vectorized processing model. First, P1 is almost identical to its counterpart in Fig. 2c, except tuples are read from Part in blocks. Moreover, since vectorized DBMSs employ late materialization, only the joinkey attribute and the corresponding tuple ID is stored in the hashtable. P2 reads blocks of tuples from LineItem and passes them through the predicate.

这图也很棒,相当于增加了用于SIMD的Block用于Join
2.3讲的是数据预取(Prefetch)但这个方案更多依赖CPU的ISA,最多能做的就是给编译器进行Hint,所以这块就不贴了
Problem Overview
In the previous section, we described how query compilation, vectorized processing, and prefetching can optimize query execution for in-memory DBMSs. A natural question to ask is whether it is possible to combine these techniques into a single query processing model that embodies the benefits of them all?
将SIMD, Query Compilation和Prefetch结合起来到一个Query Processing Model?一个很灵魂的发问——文章下面给的回复是当时没有数据库做到
Part of the reason is that most systems that employ query compilation generate tuple-at-a-time code that avoids tuple materialization
火山模型基本都是每个Tuple进行LazyLoad,都会避免Tuple Materialization(如果用PushModel这些问题应该可以得到解决)
Hence, we contend that what is needed is a hybrid model that is able to tactfully materialize state to support both tuple-at-a-time processing, vectorized processing, and prefetching.
尝试做一个混合模型(Hybrid Model)验证下三混一行不行

From the results shown in Fig. 4, we see that SIMD probes utilizing the vertical vectorization technique performs worse than tuple-ata-time probes with prefetching, even when the hash-table is cacheresident. This is because vectorization requires recomputing hash values on hash and key collisions.
用SIMD遇到了一些麻烦——有些HashKey需要重新计算,而且哈希表超过CPU缓存时,性能显著下降
其实这块有点没看懂,但结论是这三个方案合在一起需要进行trade off,中间流水线需要物化,有些数据选取需要动态选择
Example
这章主要讲文章的主要贡献ROF这个方案,这部分用的2b的图在前边
There are two key distinguishing characteristics between ROF and traditional vectorized processing; with the exception of the last stage iteration, ROF stages always deliver a full vector of input to the next stage in the pipeline, unlike vectorized processing that may deliver input vectors restricted by a selection vector.
emmm,没看懂😂他说的这个ROF是否就是Push-Model?或者应该就是存粹带有Pipeline的PushModel

Fig. 2b shows a modified query plan using our ROF technique to introduce a single stage boundary after the first predicate ( 1). The ⌅ operator denotes an output vector that represents the boundary between stages.
boundary图标复制下来好像有问题,到是好奇Boundary是否需要什么特殊代码
Staging alone does not provide many benefits; however, it facilities two optimizations not possible otherwise: SIMD vectorization, and prefetching of non-cache-resident data.
OK,是为SIMD和Prefetch做准备
Vectorization
Given this, we greedily force a stage boundary on all SIMD operator outputs. The advantages of this are (1) SIMD operators always deliver a 100% full vector of only valid tuples, (2) it frees subsequent operators from performing validity checks, and (3) the DBMS can generate tight loops that are exclusively SIMD. We now describe how to implement a SIMD scan using these boundaries.
文章给了两种使用SIMD的方案,而最终选择了在Boundary上输出SIMD结果(原因是更容易优化)
The illustration in Fig. 6 is performing a SIMD scan over a 4-byte integer column attr_A and evaluating the predicate attr_A < 44. The DBMS first loads as many attribute values as possible (along with their tuple IDs) into the widest available SIMD register.

使用bimask进行比较,然后predict,这里给的示例应该是AVX256
The permutation table stores an 8-byte value for each possible input bit-mask. A SIMD register storing n elements can produce 2n masks. With AVX2 256-bit registers operating on eight 4-byte integers, this results in 28 = 256 possible bit-masks. Thus, the size of the largest permutation table is at most 28 ⇥ 8 = 2 KB, small enough to fit in the CPU’s L1 cache.
这里感觉有点偷鸡😂那如果我是AVX512,有16个4-bytes,$2^{16} \times 16$=1MB,那L1缓存不就炸了?如果你考虑下RVV1.0那最长的2048bit的宽度那更不可能了
Prefetch
We use an open-addressing hash-table design with linear probing for hash and key-collisions. Previous work has shown this design to be robust and cache-friendly [35]. We use MurmurHash3 [9] as our primary hash function. This is differs from previous work [33] that prefers to use computationally simpler (and therefore faster) hash functions, such as multiply-add-shift.
重新设计了Hash Table,使用Murmurhash3算法,好处如下
- work on multiple different non-integer data types,
- provide a diverse hash distribution, and
- execute fast. MurmurHash3 satisfies these requirements and used in many popular systems
我在好多论文上都看到MurmurHash3
Our hash-table design is amenable to both software and hardware prefetching.
Since joins and aggregations operate on tuple vectors, software prefeteching will speed up the initial hash-table probe.
Secondly, the hardware prefetcher kicks in to accelerate the linear probing search sequence for hash collisions. By front-loading the status field and the key, the DBMS tries to ensure that at most one memory reference to a bucket is necessary to check both if the bucket is occupied and if the keys match.
相当于在Hash Table上进行Prefetch
其实我觉得这块是很Ticky的,你要控制一个CPU的缓存Prefetch,要么看编译器优化,要么修改硬件,而这一章节更多在讲构建Hash Table,感觉有点不太符合我的预期
Query Planning
A DBMS’s optimizer has to make two decisions per query when generating code with the ROF model: (1) whether to enable SIMD predicate evaluation and (2) whether to enable prefetching.
关于SIMD和Prefetch的控制
For operators that require random access to data structures whose size exceeds the cache size, the planner will install a stage boundary at the operator’s input to facilitate prefetching.
设计流水线边界的控制
这一块主要讲控制策略,可以是基于规则的启发式(有翻车可能),也可以是贪心(分两路,一路Prefetch,另一路不Prefetch然后对比寻找)
感觉这就是一种Query Optimization
Eexperiment Evaluation
大伙们喜闻乐见的跑分时间(这章节要比想象中的长)
For this evaluation, we implemented ROF in the Peloton in-memory DBMS [5]. Peloton is an HTAP DBMS that used interpretationbased execution engine for queries. We modified the system’s query planner to support JIT compilation using LLVM (v3.7)
上JIT了,以及好古早版本的LLVM
Although the TPC-H workload contains 22 queries, we select eight queries that cover all TPC-H choke-point query classifications [10] that vary from compute- to memory/join-intensive queries.
大伙们喜闻乐见的挑取几条Query比较😂文章引用的论文是TUM的TPC-H Analyzed: Hidden Messages and Lessons Learned from an Influential Benchmark.

效果来看,Q5,Q6有两倍的加速,Q19和Q14接近两倍,但Q1优化很少,我感觉有些怪——但就我分析来看,原因应该是只用SIMD优化Join,而Q1里面的Sum没用SIMD😅


后面的Case Study我就不发了,有空再看😂
We select the optimal staged plan for the eight TPC-H queries and fix the prefetch group size to 16. We then vary the size of all the output vectors in each plan from 64 to 256k tuples.
通过修改Batchsize看看Vector size对于数据处理的影响

Q1 is also insensitive to the vector size, but for a slightly different reason. In this query, more than 98% of the tuples in the LineItem table qualify the predicate. As such, the primary bottleneck in the first pipeline is not in the SIMD scan, but in the aggregation. This aggregation does not benefit from larger vector sizes, which is why Q1 is not impacted by varying this configuration parameter.
这里说Q1对向量化不敏感,Aggregate要分配大锅——应该是对的
For Q13, the primary bottleneck in the query plan is the evaluation of the LIKE clause on the o_comment field of the Orders table. Since the DBMS cannot execute this predicate using SIMD, increasing the size of the predicate’s output vector does not help.
似乎对子句处理不太行?
However, larger vectors don’t improve performance for queries with joins. This is because modern CPUs support a limited number of outstanding memory references, making the query become memory-bound quicker than CPU-bound.
较大的向量块并不能提高连接查询的性能,因为内存足够快
Each pipeline in the query plan is executed using multiple threads that each modify only thread-local state. pipeline-breaking operators, a single coordinator thread coalesces data produced by each execution thread.
给了一个分Pipeline的方案,效果见Figure17

We first note that the jump in execution time when moving from one thread to two threads for all the queries is due to the non-negligible bookkeeping and synchronization overhead that is necessary to support multi-threaded execution.
如果是多线程的话,线程切换有开销,这是不可避免的——
This corroborates our previous results in Sects. 5.3 to 5.5. Executing Q1 with multiple threads yields a consistent increase up to 20 cores at which point all CPUs are fully utilized and have saturated the memory bandwidth.
也就是说,多线程可以有效利用内存带宽
One final observation is the slight variance in execution times in Q3 and Q13 with more than 10 threads. This jitter is due to NUMA effects on our two CPU machine (10 cores per socket). …… Hence, CPUs in different NUMA regions experience different latency when accessing these counters stored in the global hash-table.
哦?还用了NUMA么,如果多线程运行Pipeline的话,NUMA也会成为影响因素。速度平均可以提升1.5倍左右
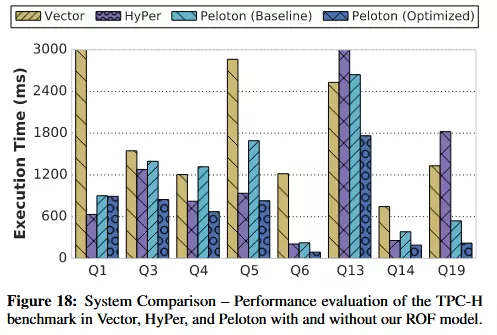
这是一个和其他数据库比较的BenchMark,这个章节的剩余部分都是在分析每个Query为什么快,为什么慢——如果细看还是有很多细节值得关注的
The primary reason for this is because HyPer uses CRC32 for hashing, implemented using SIMD (SSE4), whereas Peloton uses the more computationally intensive MurmurHash3.
那这么说,是不是MurMurHash3能更好的利用SIMD?
结语
要是VLDB有时间检验奖的话,这篇文章在2027年绝对值得得到一个😍虽然有点小Bug,但Query Optimization,Query Compilation以及数据库对于SIMD的应用基本成为了2020年以后RDBMS的主要研究方向。
可能是最近在研究相关方向,这篇文章看起来就很舒服