教程索引目录请访问:《大数据技术入门级系列教程》
HDFS是指 Hadoop Distributed File System,Hadoop分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
任何事物都有优缺点,世界上没有完美的东西,大数据使用 Hadoop 并不是说它很完美,而是暂时没有找到比它更好的解决方案。
HDFS的设计天生就是数据冗余的,所以数据会很安全,有很高的容错性,即使其中一个节点整个丢失也不会影响数据安全,因为数据将被分布在多个节点,并且存储多份,所以我们可以使用廉价的机器来存储我们宝贵的数据。
同时分布式的设计可以让集群拥有非常大的存储容量,可以是GB、TB、PB甚至是EB的容量。
因为它的优点就会带来缺点,因为文件被分布在多个节点,所以获取文件的延迟就很严重,不像是单硬盘中获取数据那样毫秒级的读写数据。
同时因为 HDFS 是采用分布式存储,这就需要 NameNode 的帮助来记录文件分布在哪里,如果你有大量的小文件存储需求,也是不适合的,这会给 NameNode 带来非常大的压力。
不支持文件并发写和随机修改,也就是说 HDFS 并不能像硬盘那样随时修改数据,而是只能追加文件或者写入以后只进行读取操作。
这里引用 Hadoop 官网文档的一个结构图,其中主要描述的就是三大块。
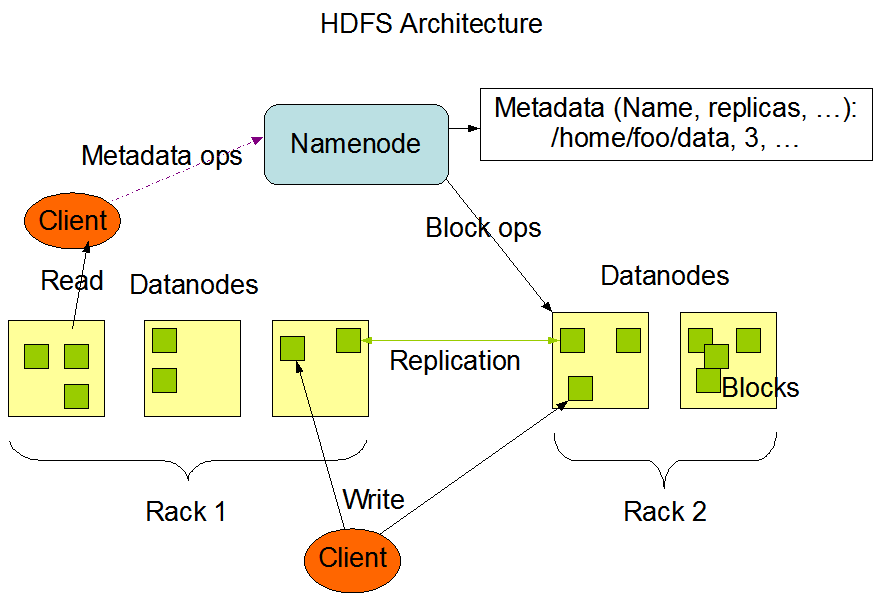
NameNode是Master主管,它负责管理 HDFS、副本策略、数据块(Block)映射信息、处理客户端的读写请求。
DataNode是Slave从属,它负责存储实际的数据块(Block)、读写数据
Client是客户端,客户端对数据进行切分成多个数据块(Block)进行上传,与 NameNode 交互获取文件数据块(Block)的位置信息,与 DataNode 交互读写数据,主要通过客户端对 NameNode 下达命令。
HDFS 文件系统跟我们日常使用的硬盘还有个最大的不同之处就是数据块(Block),HDFS 并不是存储一个一个的文件,而是一个一个的数据块(Block),然后把数据块(Block)一个一个的存储在不同的集群节点中,需要提取文件的时候再从各个集群节点中提取出数据块(Block),恢复成我们原始的文件。
数据块(Block)的大小可以通过配置进行改变,但默认 Hadoop2.x 是128MB,Hadoop1.x 是64MB。
我们需要先关注一下读取文件都发生了什么?
1.去询问 NameNode 我需要的文件都在哪里,这个叫寻址
2.去对应的 DataNode 读取数据块(Block),这里才是实际传输数据
假设我们的数据块(Block)很小,那么就会产生非常多的数据块(Block),在第一步寻址就会花费很长时间;那加入数据块(Block)很大呢,虽然数据块(Block)数量会减少,寻址会很快,但第二步可能就会很慢,因为硬盘的IO性能也是有限的。
目前市面上的机械硬盘读取速度都在 100MB/S 左右,如果将数据块(Block)设置成128M基本就是每秒读取一个数据块(Block),而寻址时间基本是10ms左右,这样搭配更合理一些,所以如果你的磁盘性能比较高的话可以将数据块(Block)调大,反之调小。我们使用默认的就可以。
关于 HDFS 的 Shell 命令,我就不说太多了,因为我讲的话也是去抄官方文档,不如直接去看官方文档:https://hadoop.apache.org/docs/r2.10.1/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html。
我只讲几个常用的给起个头,剩下的就得自己看文档了。其实 HDFS 的操作和 Linux 中的操作十分像,所以上手会很快,来举个例子。
显示目录信息:hadoop fs -ls /
创建文件夹:hadoop fs -mkdir -p /renfei/test
显示文件内容:hadoop fs -cat /renfei/test/hadoop.txt
是不是和 Linux 的操作一样的命令?所以我就不再啰嗦了,直接看官方文档吧。下一篇我们将使用编程的方式操作 HDFS。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。